Segmentation 개요
분할(Segmentation)은 이미지의 유사한 영역 또는 부분(segment)를 해당 클래스 레이블로 그룹화 하는 것을 목표로 한다. object가 있는 위치, 해당 object의 모양, 어떤 pixel이 어떤 object에 속하는지 등을 알려고 할 때 활용된다.
Image Segmentation은 Image Classification의 확장으로 classification외에도 localization을 수행한다.

Segmentation 종류
1. Semantic Segmentation
Image의 pixel을 semantic(의미론적)으로 분류
•
특정 클래스에 속하는 pixel은 단순히 해당 클래스로 분류(다른 정보나 context를 고려하지 않음).
•
위와 같은 특징 때문에 이미지에 동일한 클래스의 여러 instance가 밀접하여 한 번에 masking을 수행하는 단점이 있다(instance를 각각 구분하지 못함).
FCN이 가장 대표적인 기법이다.
2. Instance Segmentation
클래스가 아닌 "Instance"를 기반으로 픽셀을 범주로 분류
•
분류된 영역이 속한 클래스에 대한 개념이 없지만 boundary를 기반으로 겹치거나, 매우 유사한 object region을 분리할 수 있다.
•
만약 군중의 이미지가 있다면 각각의 사람을 모두 masking 할 수 있지만, 각 영역/객체가 어떤 instance인지는 예측할 수 없다.
Mask RCNN이 가장 대표적인 기법이다.
3. Panoptic Segmentation
Object의 각 Instance를 분리하고 Object의 identity을 예측하는 semantic segmentation과 instance segmentation의 조합
•
모든 pixel에 대해 레이블 하면서 각각의 object 별로 개별 masking을 수행한다.
DeepLab이 가장 대표적인 기법이다.
Segmentation 구조
Semantic segmentation model은 제공되는 입력에 해당하는 출력으로 segment map을 제공한다.
이런 segment map은 n 채널로 구성되며, n은 모델이 segment해야 하는 클래스 수를 말한다.
이러한 각각의 n 채널은 본질적으로 binary하여 object location은 1로, empty region은 0으로 구성된다.
Ground truth map은 input과 size가 같고, 범위가 n인 single channel integer array와 각 segment는 해당 클래스의 index 값으로 채워진다. (클래스는 0에서 n-1로 indexing 됨)
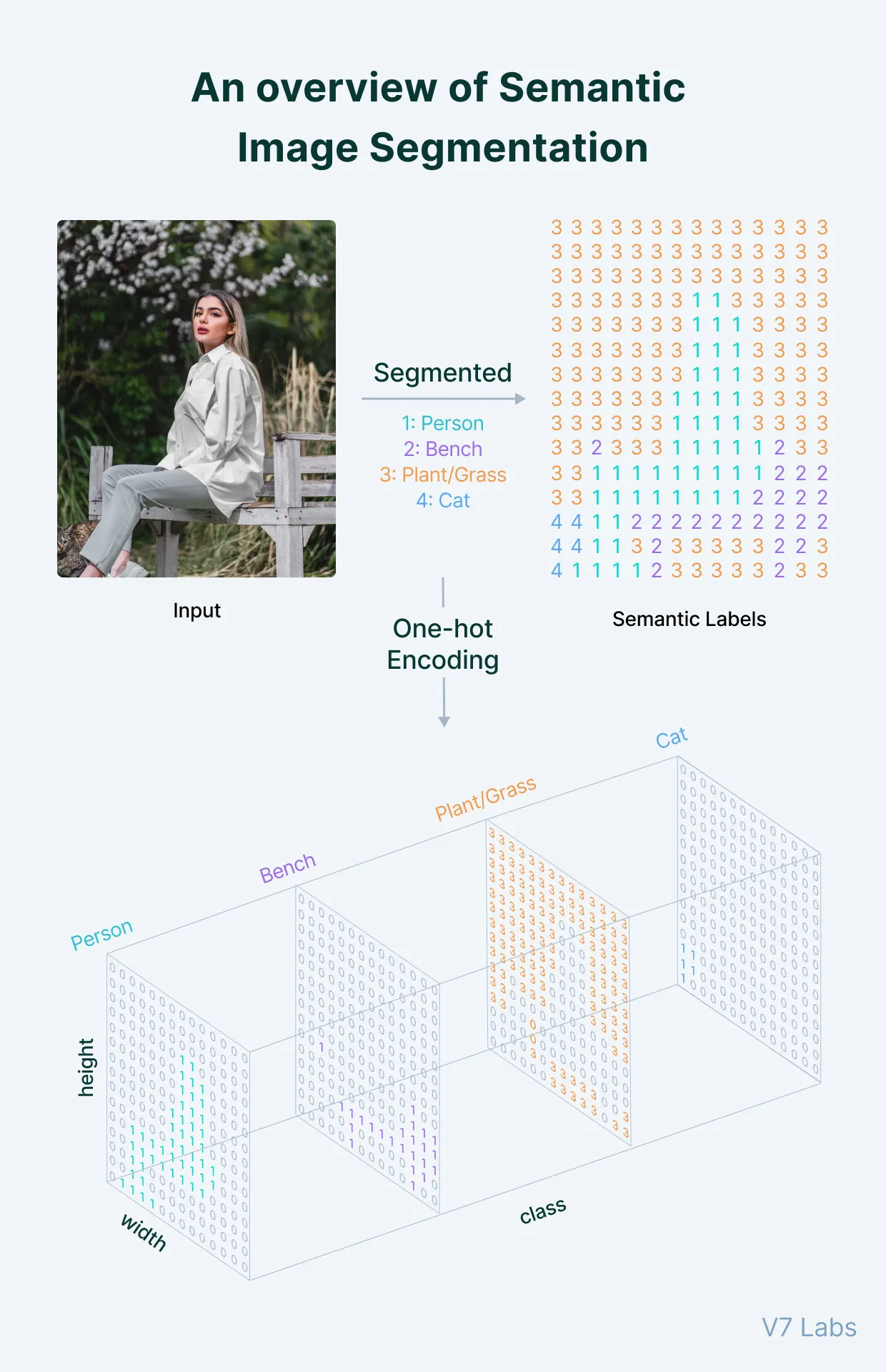
n channel binary format의 model output은 prediction의 2차원 one-hot encoding으로 표현된다.
segmentation을 수행하는 신경망은 일반적으로 encoder 다음에 bottleneck 구조가 있으며, bottleneck으로부터 decoder 혹은 upsampling layers가 있다.
Convolutional Encoder-Decoder Architecture
Semantic segmentation을 위한 encoder-decoder 구조는 SegNet을 통해 인기를 얻었다. SegNet은,
•
encoder
convolutional과 downsampling block을 조합하여 사용해 정보를 bottleneck 상태로 압축하고, input의 representation을 형성.
•
decoder
decoder는 입력 정보를 재구성하여 입력의 영역을 강조 표시하고 해당 클래스 아래에 그룹화하는 segment map을 형성.
Decoder의 마지막 부분에서는 (0, 1) 범위의 output으로 표현하기 위해서 sigmoid activation을 가진다.
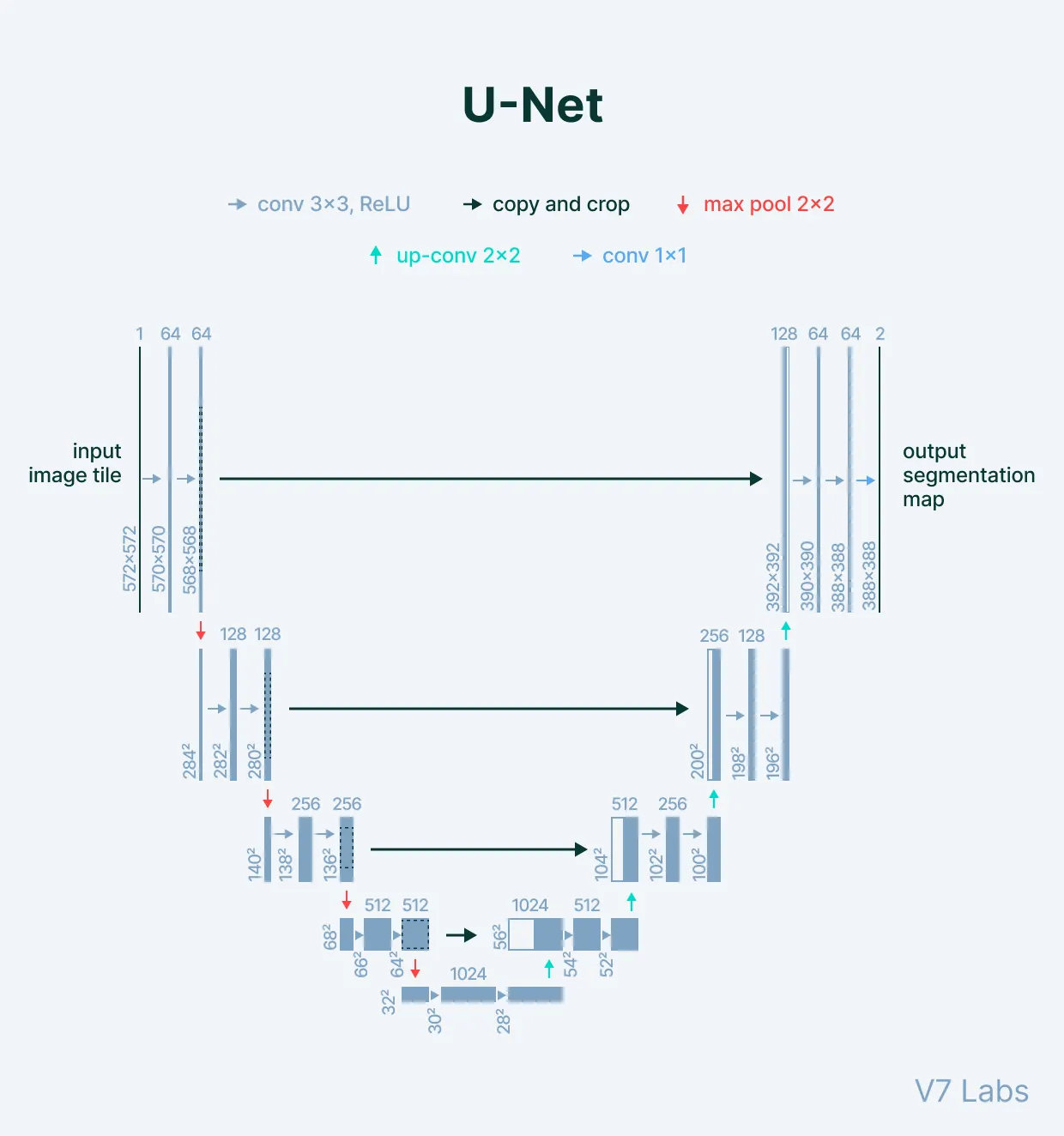
U-Net
U-Net에 대해 간단히 설명하자면 일반적인 encoder-decoder 구조의 downsampling layer에서 확인되는 information loss에 대한 해결책으로 skip connection을 도입했다.
Skip connection은 bottleneck layer를 거치지 않고 encoder에서 decoder로 직접 이동하는 연결을 말한다. 이는, 다양한 level의 encoded representations가 캡쳐되어 decoder의 feature map에 concatenate 되게 한다.
결론적으로 pooling 및 downsampling을 통해 발생하는 data loss를 줄이는데 도움이 된다.
자세한 설명은 U-Net 페이지에서 다룬다.