

다음 그림은 같은 Residual Block이지만 왼쪽은 BottleNeck 구조를 사용하지 않았고, 오른쪽은 BottleNeck 구조를 사용했다.
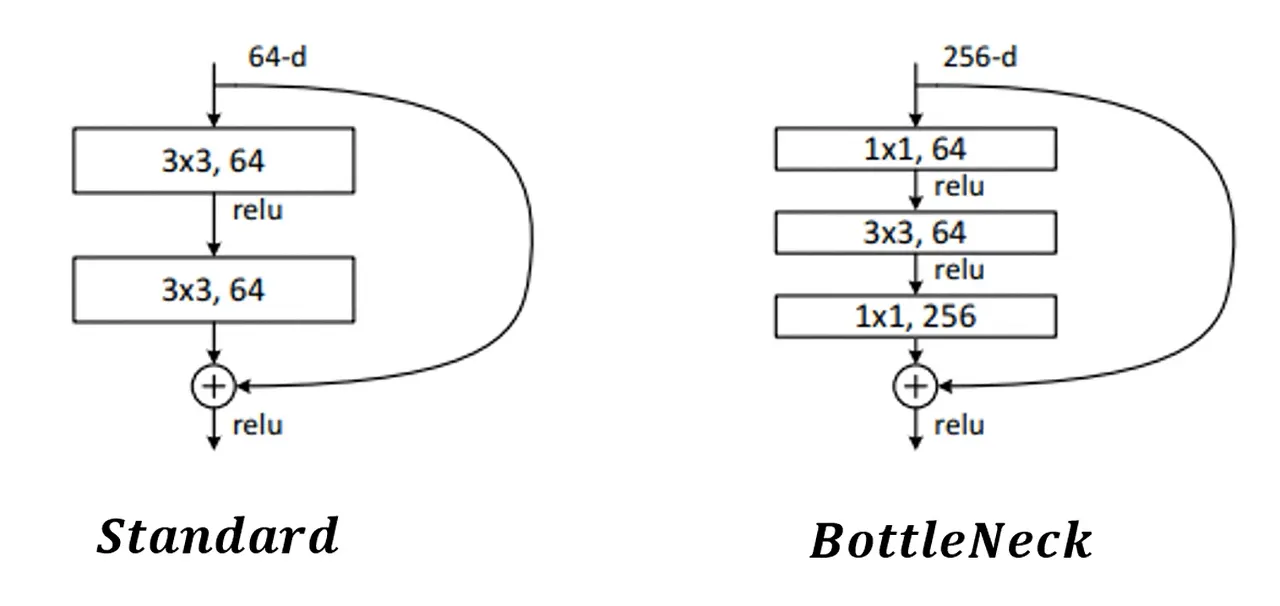
먼저 Convolution의 Parameters을 계산할 줄 알아야 하는데, 다음과 같다.

Convolution Parameters = Kernel Size x Kernel Size x Input Channel x Output channel
BottleNeck의 핵심은 1x1 Convolution이다. 1x1 Convolution의 Parameters는1 x 1 x Input Channel x Output Channel 이다. 대개 1x1 Convolution은 연산량이 작기 때문에 Feature Map(Output Channel)을 줄이거나 키울 때 사용된다.
BottleNeck 구조
1.
Input Channel = 256인 320x320 Input Image가 있다고 가정

B = Batch size
2.
Channel Compression (채널 압축)
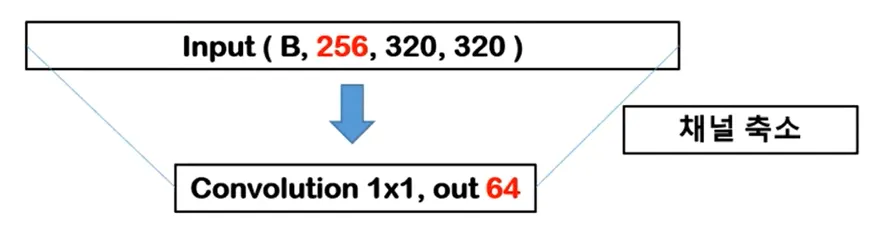
Input Channel = 256 → Output Channel = 64
256을 64로 채널을 강제로 축소한 이유는 오로지 연산량을 줄이기 위함이다. 1x1 Convolution은 Spatial(공간적인) 특징을 가지고 있지 않다. Convolution 연산이 공간적인 특징을 추출하기 위해선 Kernel Size가 최소 2이상 되어야 한다.
3.
특징 추출
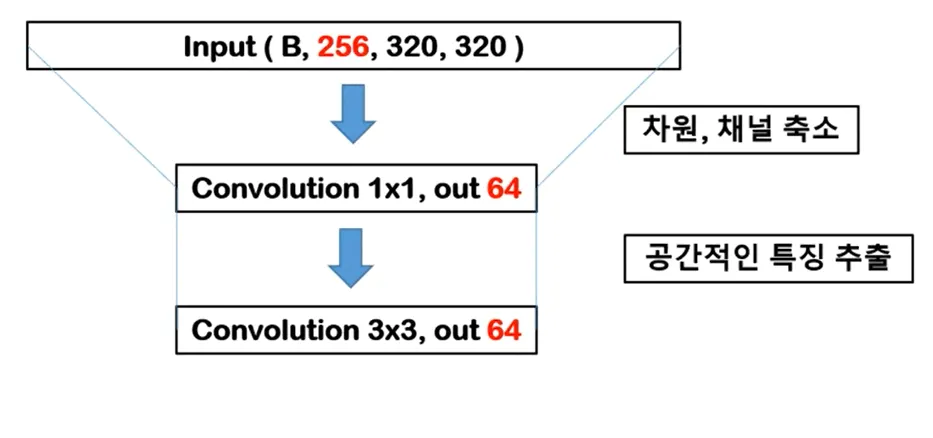
Input Channel = 64 → Output Channel = 64
3x3 Convolution은 특성을 추출하는 역할을 한다. 3x3 Convolution 연산은 = 3 x 3 x Input Channel x Output Channel 이다. ( 3 x 3 x 64 x 64 ) 3x3 Convolution은 1x1 Convolution 보다 9배 연산량이 많기 때문에, 1x1 Convolution에서 채널을 줄인 후에 3x3 Convolution에서 특성을 추출한다.
4.
Channel Increase (채널 증가)
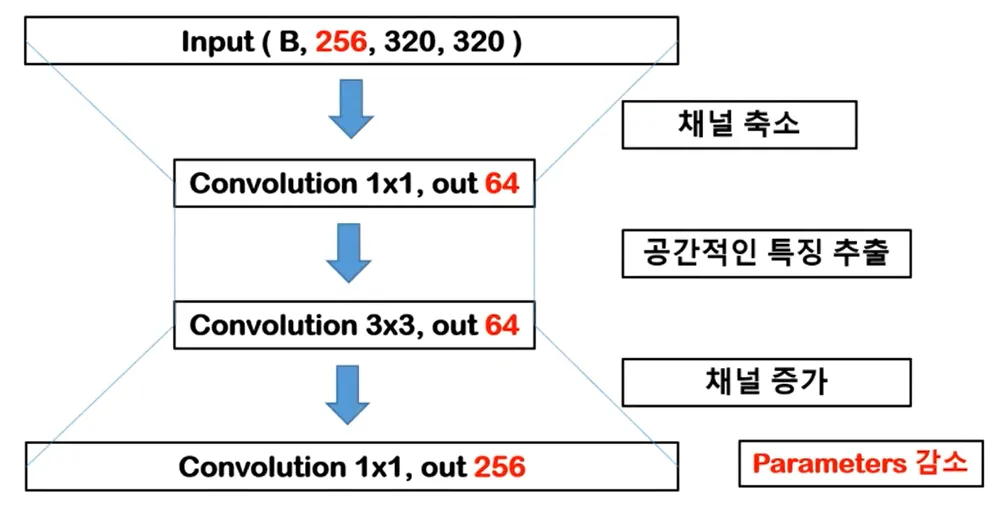
Input Channel = 64 → Output Channel = 256
CNN은 Feature Map의 특성이 많으면 많을수록 학습이 잘 되기 때문에, 1x1 Convolution으로 강제적으로 채널을 증가시켜준다. BottleNeck의 구조는 1x1 Convolution으로 장난을 치면서 연산량을 최소화하는 것이다.
하지만 강제로 채널을 줄이고 늘리는 것은 정보 손실을 일으킨다.
정보 손실은 모델의 정확성을 떨어뜨린다.
연산량과 정보손실은 서로 trade off 관계이기 때문에 서로의 합의점을 찾는 것이 중요하다.
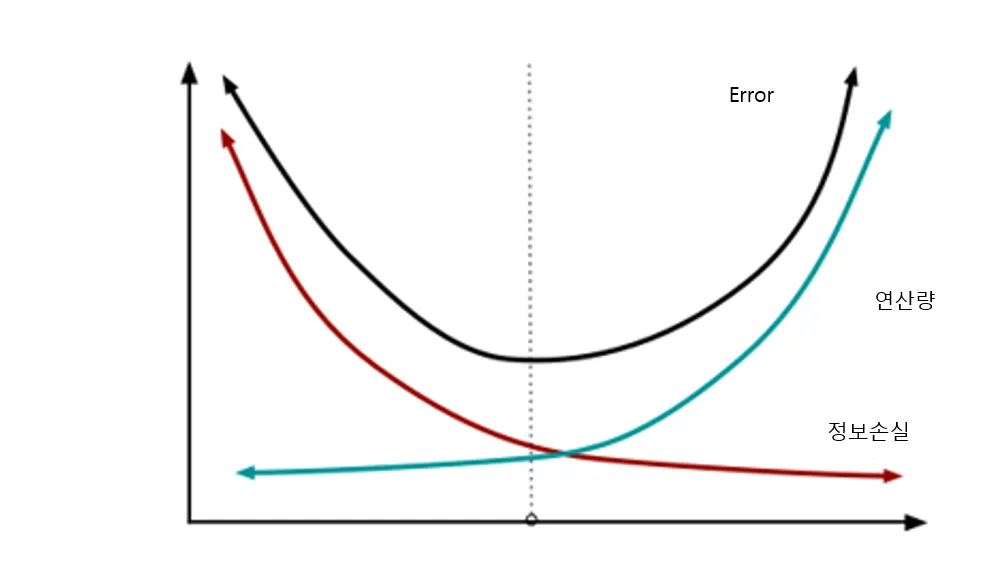
BottleNeck은 Standard Residual Block보다 layer의 수는 더 많아졌지만 연산량은 줄어들었다. 그리고 layer가 많아짐은 곧 활성화 함수가 기존보다 더 들어간다는 의미이고 이는 더 많은 비선형성이 들어가게 되면서 Input을 다양하게 가공할 수 있음을 나타낸다.