목차
B-Tree는 이진 트리에서 발전되어 모든 리프노드들이 같은 레벨을 가질 수 있도록 자동으로 밸런스를 맞추는 트리이다. 또한 정렬된 순서를 보장하고, 멀티레벨 인덱싱을 통한 검색 속도 향상이 가능하다.
데이터베이스에서 대량의 데이터를 효율적으로 처리하기위해 인덱스는 꼭 필요하다. 인덱스는 특정 열 또는 컬럼에 대해 정렬된 구조로 데이터를 저장하며, 이를 통해 빠른 검색이 가능하고 특히 WHERE 절에서 조건에 따라 데이터의 위치를 빠르게 찾아준다. Index를 구현하는 자료구조인 B-Tree에 대해서 알아보자.
B-Tree
B-Tree는 이진 트리와 다르게 하나의 노드에 많은 수의 정보를 가지고 있을 수 있다. 최대 개의 자식을 가질 수 있는 B-Tree를 차 B-Tree라고 하며, 다음과 같은 특징을 갖는다.
•
노드는 최대 개부터 개 까지의 자식을 가질 수 있다.
•
노드에는 최대 개부터 개의 키가 포함될 수 있다.
•
노드의 키가 개라면 자식의 수는 개이다.
•
최소차수는 자식수의 하한값을 의미하며, 최소차수가 라면 을 만족한다. (최소차수 가 2라면 3차 B-Tree이며, key의 하한은 1개이다)
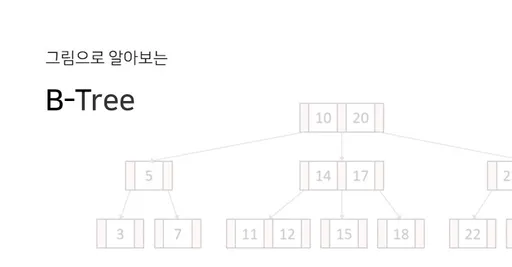
다음은 차수가 3인 B-Tree이다. 파란색 부분은 각 노드의 key를 나타내며, 빨간색 부분은 자식 노드들을 가리키는 포인터이다. key들은 노드 안에서 항상 정렬된 값을 가지며, 이진검색 트리처럼 각 key들의 왼쪽 자식들은 항상 key보다 작은 값을, 오른쪽은 큰 값을 가진다.

key 검색 과정
루트 노드에서 시작해서 하향식으로 검색을 수행한다. 검색하고자 하는 key를 라고 하였을 때 검색 과정이다.
1.
루트 노드에서 시작하여 key들을 순회하면서 검사
a.
만일 와 같은 key를 찾았다면 검색을 종료
b.
검색하는 값과 key들의 대소관계를 비교. 어떠한 key들 사이에 가 들어간다면 해당 key들 사이의 자식노드로 내려감
2.
해당 과정을 리프 노드에 도달할 때까지 반복. 만일 리프 노드에서도 와 같은 key가 없다면 검색을 실패


key 삽입 과정
key를 삽입하기 위해서는 1. 요소 삽입에 적절한 리프 노드를 검색하고, 2. 필요한 경우 노드를 분할해야한다.
리프 노드 검색은 하향식이지만 노드 분할의 과정은 상향식으로 이루어진다고 볼 수 있다. 삽입하고자 하는 값을
로 했을 때 삽입 과정이다.
1.
트리가 비어있으면 루트 노드를 할당하고 를 삽입. 만일 루트 노드가 가득 찼다면, 노드를 분할하고 리프 노드가 생성
2.
이후부터는 삽입하기에 적절한 리프 노드를 찾아서 를 삽입. 삽입 위치는 노드의 key값과 값을 검색 연산과 동일한 방법으로 비교하면서 탐색
이후 두 가지 케이스로 나뉜다.
Case 1. 분할이 일어나지 않는 경우
리프 노드가 가득 차지 않았다면, 오름차순으로 를 삽입한다.

Case 2. 분할이 일어나는 경우
만일 리프 노드에 key 노드가 가득 찬 경우, 노드를 분할해야 한다.
1.
오름차순으로 요소를 삽입. 노드가 담을 수 있는 최대 key 개수를 초과하게 됨
2.
중앙값에서 분할을 수행. 중앙값은 부모 노드로 병합하거나 새로 생성됨. 왼쪽 키들은 왼쪽 자식으로, 오른쪽 키들은 오른쪽 자식으로 분할
3.
부모 노드를 검사해서 또 다시 가득 찼다면, 다시 부모 노드에서 위 과정을 반복



key 삭제 과정
요소를 삭제하기 위해서는 1. 삭제할 키가 있는 노드 검색, 2. 키 삭제, 3. 필요한 경우, 트리 균형 조정을 해야한다.
삭제 과정을 이해하기 위해서 몇 가지 용어를 정의한다.
•
inorder predecessor : 노드의 왼쪽 자손에서 가장 큰 key
•
inorder successor : 노드의 오른쪽 자손에서 가장 작은 key
•
부모 key : 부모 노드의 key들 중 왼쪽 자식으로 본인 노드를 가지고 있는 key값이다. 단, 마지막 자식 노드의 경우에는 부모의 마지막 key이다.
Case 1. 삭제할 key 가 리프에 있는 경우
Case 1.1. 현재 노드의 key 개수가 최소 key 개수보다 크다면
다른 노드들의 영향 없이 해당 를 단순 삭제

Case 1.2. 왼쪽 또는 오른쪽 형제 노드의 key가 최소 key 개수 이상이라면
1.
부모 key 값으로 를 대체
2.
최소키 개수 이상의 키를 가진 형제 노드가 왼쪽 형제라면 가장 큰 값을, 오른쪽 형제라면 가장 작은 값을 부모 key로 대체

Case 1.3. 왼쪽, 오른쪽 형제 노드의 key가 최소 key 개수이고, 부모노드의 key가 최소개수 이상이면
1.
를 삭제한 후, 부모 key를 형제 노드와 병합
2.
부모 노드의 key 개수를 하나 줄이고, 자식 수 역시 하나를 줄여 B-Tree를 유지

Case 1.4. 자신과 형제, 부모 노드의 key 개수가 모두 최소 key 개수라면
부모 노드를 루트 노드로 한 부분 트리의 높이가 줄어드는 경우이기 때문에 재구조화. case3의 2번 과정으로 이동
Case 2. 삭제할 key k가 내부 노드에 있고, 노드나 자식에 키가 최소 키수보다 많을 경우
1.
현재 노드의 inorder predecessor 또는 inorder successor와 의 자리를 변경
2.
리프 노드의 를 삭제하게 되면, 리프 노드가 삭제 되었을 때의 조건으로 변함. 삭제한 리프 노드에 대해서 case 1 조건으로 이동

Case 3. 삭제할 key 가 내부 노드에 있고, 노드에 key 개수가 최소 key 개수만큼, 노드의 자식 key 개수도 모두 최소 key 개수인 경우
삭제할 key 가 있는 노드도 최소, 자식노드들도 최소의 key 개수를 가지므로, 를 삭제하면 트리의 높이가 줄어들어 재구조화가 일어나는 케이스이다. 재구조화의 과정은 다음과 같다.
1.
를 삭제하고, 의 양쪽 자식을 병합하여 하나의 노드로 만듦.
2.
의 부모 key를 인접한 형제 노드에 붙임. 이후, 이전에 병합했던 노드를 자식 노드로 설정.
3.
해당 과정을 수행하였을 때 부모 노드의 개수에 따라 이후 수행 과정이 달라짐.
a.
만일 새로 구성된 인접 형제 노드의 key가 최대 key 개수를 넘어갔다면, 삽입 연산의 노드 분할 과정을 수행.
b.
만일 인접 형제 노드가 새로 구성되더라도 원래 의 부모 노드가 최소 key의 개수보다 작아진다면, 부모 노드에 대하여 2번 과정부터 다시 수행.


Index
인덱스는 어떻게 구현할까? 데이터 저장방식에 따라 크게 2가지 방법으로 구현한다. Hash Map과 B+Tree이다.
Hash Map
기본적으로 key-value 구조를 가지며 key 값에 검색할 데이터 컬럼을 넣은 후, value 값에 테이블에 저장되어 있는 위치를 저장한다. 때문에 해시테이블의 시간복잡도는 O(1)이 되며, 매우 빠르다. 하지만 함정이 있다. 바로 (=) 연산에만 적용된다는 점이다.
해시 값은 값이 조금이라도 변하면 완전 다른 값이 된다. 때문에 값 끼리의 비료가 불가능하다. index 특성상 부등호나 %, _ 등의 문자열이 들어가는 경우가 많은데, 이에 적용할 수 없으니 사용하지 않는다.
B+Tree
트리 구조를 가지며 하나의 노드가 여러개의 데이터를 가질 수 있는 B-Tree를 index에서 사용하기 적합하게 확장한 새로운 자료구조이다.
B-Tree vs B+Tree
항목 | B-Tree | B+Tree |
키 저장 위치 | 내부 노드와 리프 노드 | 모든 키는 리프 노드에만 저장 |
데이터 저장 위치 | 키와 데이터를 함께 저장 | 데이터는 리프 노드에만 저장 |
리프 노드 간 연결 | 없음 | 모든 리프 노드가 연결됨 (Linked List 형태) |
검색 효율 | 일반 탐색 트리처럼 동작 | 리프 노드만 보면 돼서 범위 검색이 빠름 |
트리 높이 | 상대적으로 낮을 수 있음 | 리프에 몰아넣기 때문에 조금 더 높을 수 있음 |
대표 사용처 | 이론적 구조 또는 간단한 구조 | 대부분의 DBMS 인덱스에서 사용 |