
인덱스는 데이터베이스 쿼리의 성능을 언급하면서 빼놓을 수 없는 부분이다.
각 인덱스의 특성과 차이는 상당히 중요하며, 물리 수준의 모델링을 할 때도 중요한 요소가 될 것이다.
8.1 디스크 읽기 방식
데이터베이스의 성능 튜닝은 어떻게 디스크 I/O를 줄이느냐가 관건이냐이기 때문에 사전 지식으로
"랜덤(Random) I/O", "순차(Sequential) I/O" 방식에 대해 이해해야 한다.
8.1.1 HDD와 SSD
컴퓨터에서 CPU나 메모리 같은 주요 장치는 대부분 전자식 장치지만 하드 디스크 드라이브는 기계식 장치다. 그래서 데이터베이스 서버에서는 항상 디스크 장치가 병목이 된다.
물리적 방식으로 데이터를 읽고 쓰는 HDD보다 플래시 메모리를 이용한 SSD가 훨씬 빠른 것은 익히 알고 있다.
데이터베이스 서버에서 순차 I/O 작업은 그다지 비중이 크지 않고 랜덤 I/O를 통해 작은 데이터를 읽고 쓰는 작업이 대부분이므로 SSD의 장점은 DBMS용 스토리지에 최적이라고 볼 수 있다.
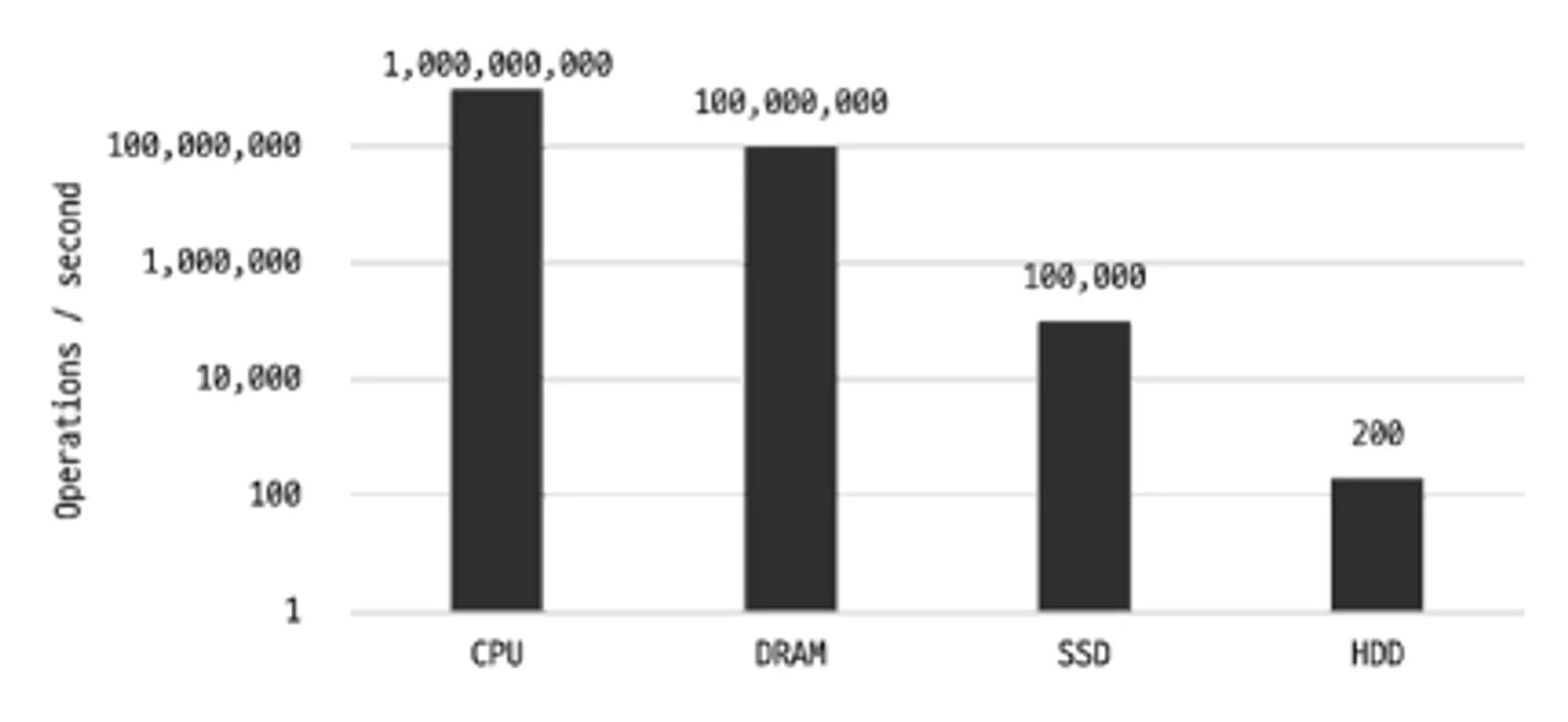
주요 장치의 초당 처리 횟수
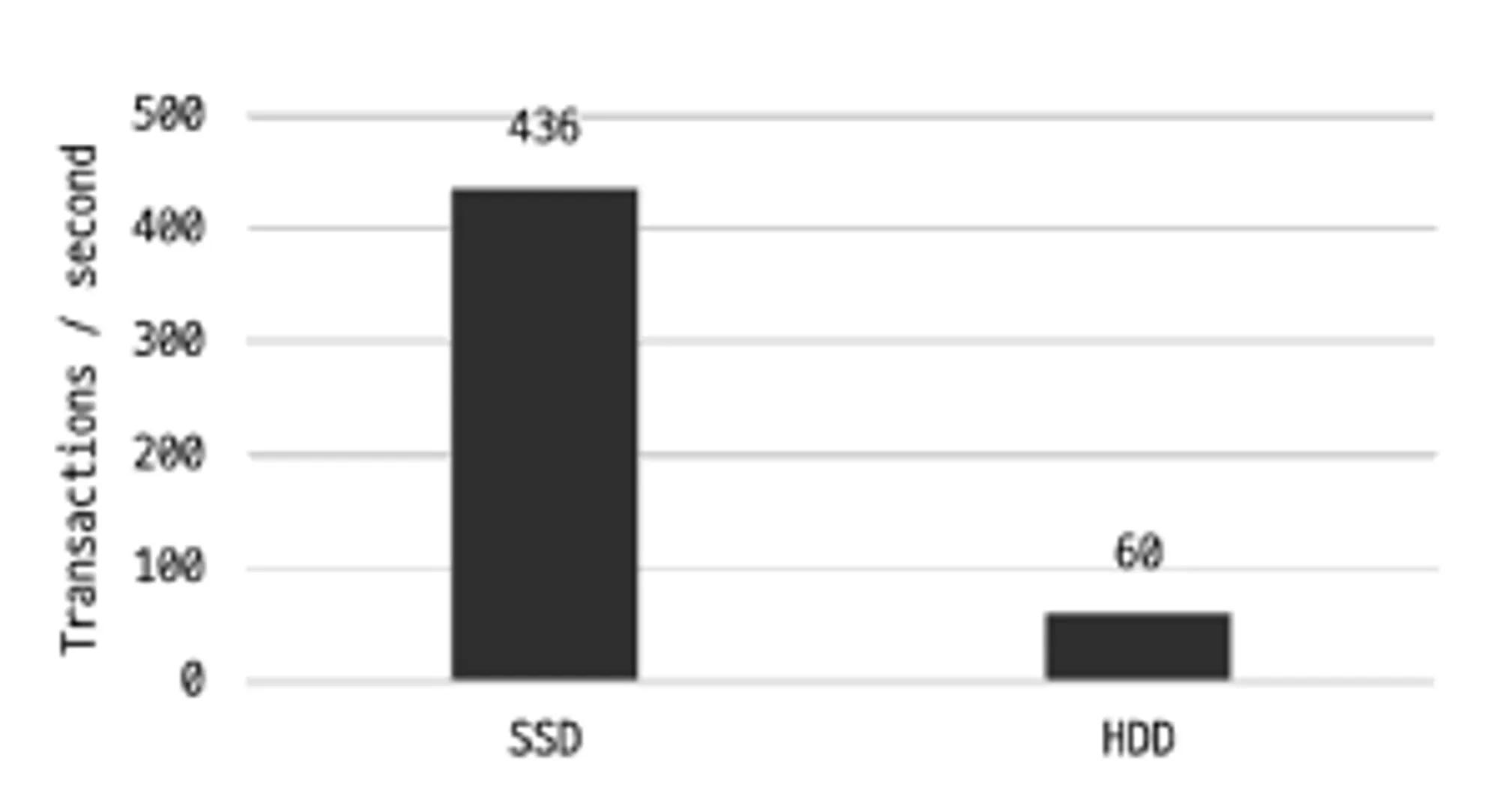
SSD와 HDD의 성능 벤치마크
8.1.2 랜덤 I/O와 순차 I/O
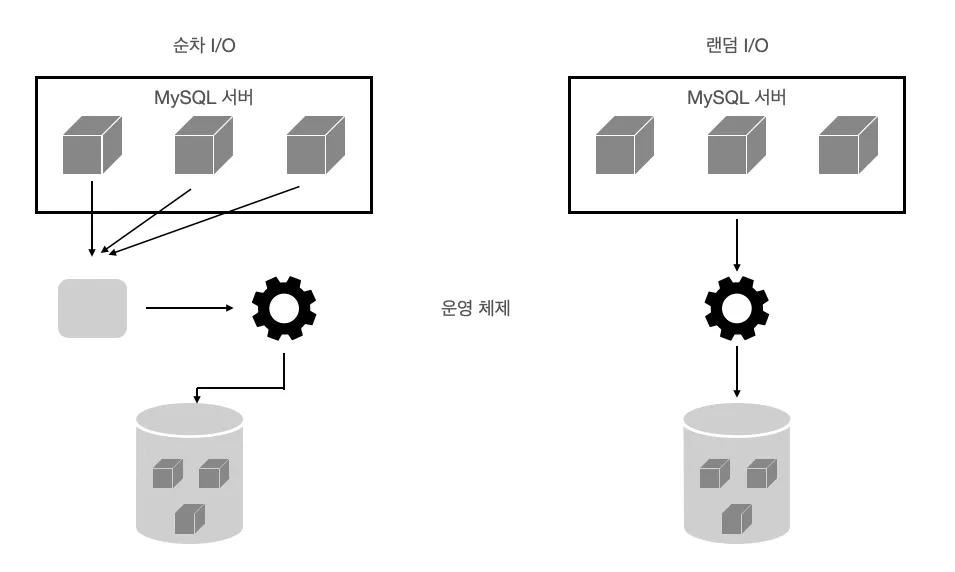
랜덤 I/O라는 표현은 하드 디스크 드라이브(HDD)의 플래터(원판)를 돌려서 읽어야 할 데이터가 저장된 위치로 디스크 헤더를 이동시킨 다음 데이터를 읽는 것을 의미한다.
순차 I/O는 3개의 페이지를 디스크에 기록하기 위해 1번 시스템 콜을 요청했지만 랜덤 I/O는 3개의 페이지를 디스크에 기록하기 위해 3번 시스템 콜을 요청한다. 디스크에 기록해야 할 위치를 찾기 위해 순차 I/O는 디스크의 헤드를 1번 움직였고, 랜덤 I/O는 디스크 헤드를 3번 움직인 것이다. 디스크에 데이터를 읽고 쓰는데 걸리는 시간은 디스크 헤더를 움직여서 읽고 쓸 위치로 옮기는 단계에서 결정된다. 즉, 디스크의 성능은 디스크 헤더의 위치 이동 없이 얼마나 많은 데이터를 한번에 기록하느냐에 의해 결정된다.
랜덤 I/O나 순차 I/O 모두 파일에 쓰기를 실행하면 반드시 동기화 또는 플러시 작업이 필요하다.
일반적으로 쿼리를 튜닝한다는 것은 랜덤 I/O 자체를 줄여주는 것이 목적이라고 할 수 있다. 랜덤 I/O를 줄인다는 것은 쿼리를 처리하는 데 꼭 필요한 데이터만 읽도록 쿼리를 개선하는 것을 의미한다.
인덱스 레인지 스캔은 데이터를 읽기 위해 주로 랜덤 I/O를 사용하며, 풀 데이터 스캔은 순차 I/O를 사용한다.
8.2 인덱스란?
•
DBMS에서 데이터베이스 테이블의 모든 데이터를 검색해서 원하는 결과를 가져오려면 시간이 오래 걸린다. 그래서 칼럼(또는 칼럼들)의 값과 해당 레코드가 저장된 주소를 키와 값의 쌍(key-value pair)으로 삼아 인덱스를 만들어둔다.
•
DBMS 인덱스의 가장 중요한 것은 정렬이다. 칼럼의 값을 주어진 순서로 미리 정렬해서 보관한다.
•
DBMS에서 인덱스는 데이터의 저장(Insert, Update, Delete) 성능을 희생하고 그 대신 데이터의 읽기 속도를 높이는 기능이다.
•
인덱스는 데이터를 관리하는 방식(알고리즘)과 중복 값의 허용 여부 등에 따라 여러 가지로 나눠볼 수 있다.
◦
역할별로 구분 - Primary key, Secondary key
▪
프라이머리 키는 그 레코드를 대표하는 칼럼의 값으로 만들어진 인덱스를 의미한다. 이 칼럼은 테이블에서 해당 레코드를 식별할 수 있는 기준값이 되기 때문에 이를 식별자라고도 부른다. 프라이머리 키는 NULL값을 허용하지 않으며 중복을 허용하지 않는다.
▪
프라이머리 키를 제외한 나머지 모든 인덱스는 세컨더리 인덱스(Secondary Index)로 분류한다. 유니크 인덱스는 프라이머리 키와 성격이 비슷하고 프라이머리 키를 대체해서 사용할 수도 있다고 해서 대체 키라고도 하는데, 별도로 분류하기도 하고 그냥 세컨더리 인덱스로 분류하기도 한다.
◦
데이터 저장 방식(알고리즘)별로 구분 - B-Tree Index, Hash Index
▪
B-Tree 알고리즘은 가장 일반적으로 사용되는 인덱스 알고리즘으로서, 상당히 오래 전에 도입된 알고리즘이며 그만큼 성숙해진 상태다. B-Tree 인덱스는 칼럼의 값을 변형하지 않고 원래의 값을 이용해 인덱싱하는 알고리즘이다.
▪
Hash 인덱스 알고리즘은 칼럼의 값으로 해시값을 계산해서 인덱싱하는 알고리즘으로, 매우 빠른 검색을 지원한다. 하지만 값을 변형해서 인덱싱하므로 전방(Prefix) 일치와 같이 값의 일부만 검색하거나 범위를 검색할 때는 사용할 수 없다. 주로 메모리 기반의 데이터베이스에서 많이 사용한다.
◦
데이터의 중복 허용 여부로 구분 - Unique Index, Non-Unique Index
◦
인덱스의 기능별로 구분 - 전문 검색용 Index, 공간 검색용 Index