
목차
1. 데이터 설명 및 보기
1-1. 데이터 불러오기
import pandas as pd
import matplotlib as mpl
import matplotlib.pylab as plt
import seaborn as sns
import numpy as np
file_path = 'StudentsPerformance/StudentsPerformance.csv'
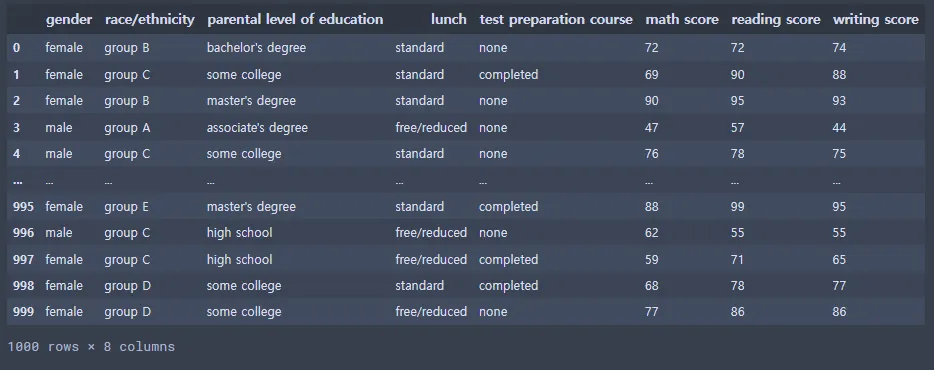
st_data = pd.read_csv(file_path)
st_data.drop(['Unnamed: 0'], axis = 1, inplace = True)
st_data
Python
복사
1-2. 데이터 백업
st_data_copy_backup = st_data.copy()
st_data.to_csv('StudentsPerformance/StudentsPerformance_backup.csv')
file_path = 'StudentsPerformance/StudentsPerformance_backup.csv'
st_data_csv_backup = pd.read_csv(file_path)
st_data_csv_backup.drop(['Unnamed: 0'], axis = 1, inplace = True)
st_data_csv_backup
Python
복사
st_data.info()
Python
복사
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1000 entries, 0 to 999
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 gender 1000 non-null object
1 race/ethnicity 1000 non-null object
2 parental level of education 1000 non-null object
3 lunch 1000 non-null object
4 test preparation course 1000 non-null object
5 math score 1000 non-null int64
6 reading score 1000 non-null int64
7 writing score 1000 non-null int64
dtypes: int64(3), object(5)
memory usage: 62.6+ KB
Plain Text
복사
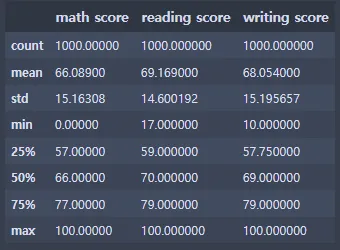
st_data.describe()
Python
복사
2. 데이터 기초 분석 및 탐색
데이터 재구조화
.map()을 사용하여 데이터프레임의 데이터를 다른 값으로 변경.
ex) df['변경할 열'] = df['변경할 열'].map({'데이터1':1, '데이터2':2})
gender 변수의 male, female → 0, 1
gender_dict = {'male':0, 'female':1}
st_data['gender'] = st_data['gender'].map(gender_dict)
Python
복사
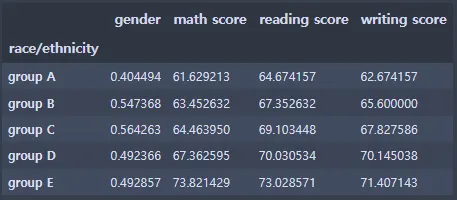
2-1. race/ethnicity 그룹 분석
st_data.groupby(['race/ethnicity']).mean()
Python
복사
race/ethnicity 변수의 group A, group B, group C, group D, group E → 0, 1, 2, 3, 4
race_dict = {'group A':0, 'group B':1, 'group C':2, 'group D':3, 'group E':4}
st_data['race/ethnicity'] = st_data['race/ethnicity'].map(race_dict)
Python
복사
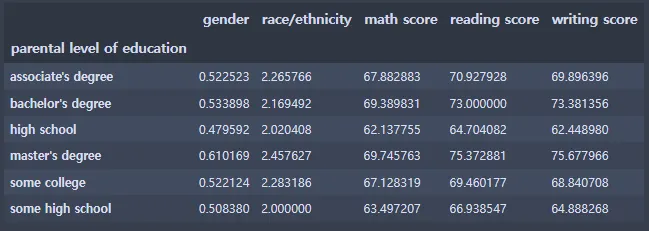
2-2. parental level of education 그룹 분석
st_data.groupby(['parental level of education']).mean()
Python
복사
parental level of education 변수의 값 변환
•
some high school : 0
•
high school : 1
•
some college : 2
•
bachelor's degree : 3
•
associate's degree : 4
•
master's degree : 5
eduLevel_dict = {'some high school':0, 'high school':1, 'some college':2, 'bachelor\'s degree':3, 'associate\'s degree':4, 'master\'s degree':5}
st_data['parental level of education'] = st_data['parental level of education'].map(eduLevel_dict)
Python
복사
2-3. lunch 그룹 분석
st_data.groupby('lunch').size()
Python
복사

lunch의 free/reduced, standard → 0, 1
lunch_dict = { 'free/reduced':0, 'standard':1}
st_data['lunch'] = st_data['lunch'].map(lunch_dict)
Python
복사
2-4. test preparation course 그룹 분석
st_data.groupby(['test preparation course']).mean()
Python
복사

preparation course의 none, completed → 0, 1
pre_dict = {'none':0, 'completed':1}
st_data['test preparation course'] = st_data['test preparation course'].map(pre_dict)
Python
복사
st_data
Python
복사
st_data.info()
Python
복사
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1000 entries, 0 to 999
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 gender 1000 non-null int64
1 race/ethnicity 1000 non-null int64
2 parental level of education 1000 non-null int64
3 lunch 1000 non-null int64
4 test preparation course 1000 non-null int64
5 math score 1000 non-null int64
6 reading score 1000 non-null int64
7 writing score 1000 non-null int64
dtypes: int64(8)
memory usage: 62.6 KB
Plain Text
복사
math score, reading score, writing score의 평균을 낸 컬럼 만들기
st_data['avg_score'] = (st_data['math score'] + st_data['reading score'] + st_data['writing score'])/3 #각각의 시험 점수의 평균값을 avg_score열에 넣는다.
#소수점으로 나온 값을 int형으로 바꿔서 소수점을 없앤다.
st_data['avg_score'] = st_data['avg_score'].astype(int)
Python
복사
st_data
Python
복사
밥을 먹고 시험 준비 과정도 거친 학생이 시험을 잘봄.
밥을 먹고 시험 준비 과정도 거친 학생에 대한 컬럼 만들기
s1 = st_data['lunch'] # lunch열 데이터를 s1에 저장
s2 = st_data['test preparation course'] # test preparation course열 데이터를 s2에 저장
st_data['lap'] = s1 + s2 # s1, s2에 있던 값들을 서로 더한 값을 데이터프레임에 lap열을 생성해 저장
st_data['lap'] = st_data['lap'].replace(1, 0) # 1값을 0으로 변경
st_data['lap'] = st_data['lap'].replace(2, 1) # 2값을 1로 변경
st_data
Python
복사
새로 생성한 lap 열을 그룹 분석
st_data.groupby(['lap']).mean()
Python
복사

컬럼의 공백을 언더바 대체, 이름 간략화
st_data = st_data.rename({'parental level of education':'parent_edu_level', 'test preparation course':'test_prepare', 'math score':'math_score', 'reading score': 'reading_score', 'writing score':'writing_score'}, axis = 'columns') #열의 이름 수정
st_data
Python
복사
3. 데이터 클린징
3-1. 결측치 확인
import missingno as msno
st_data.isnull().sum()
Python
복사
gender 0
race/ethnicity 0
parent_edu_level 0
lunch 0
test_prepare 0
math_score 0
reading_score 0
writing_score 0
avg_score 0
lap 0
dtype: int64
Plain Text
복사
msno.matrix(st_data)
Python
복사

결측치 제거를 한 값을 새 데이터프레임 st_data2를 생성하여 넣음
결측치 제거를 위해 들어있는 행, 열 전체를 삭제하는 것은 데이터 삭제 또는 데이터 왜곡의 위험성이 있기에, 반드시 원본 데이터를 별도로 백업한 후 작업 진행.
st_data2 = st_data.dropna(axis=0)
Python
복사
3-2. 이상치 확인
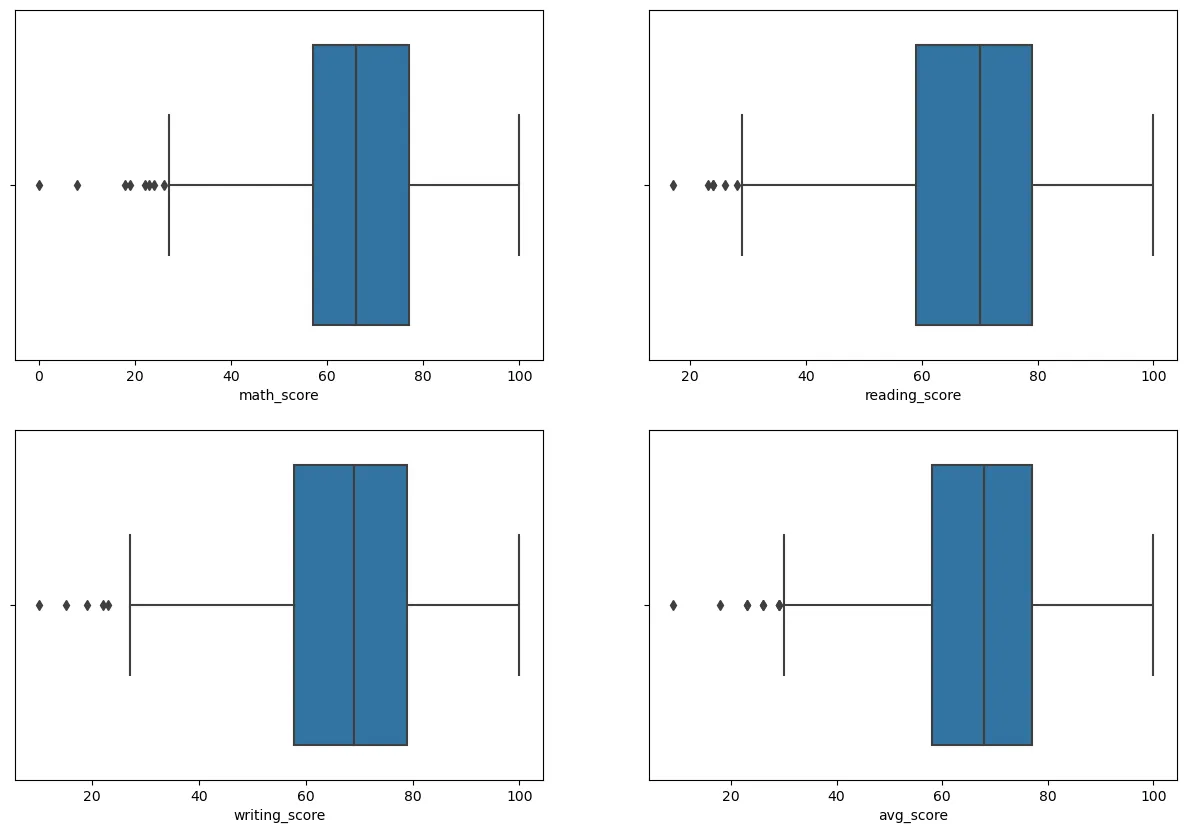
figure, ((ax1, ax2), (ax3, ax4)) = plt.subplots(nrows=2, ncols=2)
figure.set_size_inches(15, 10)
sns.boxplot(x = "math_score", data = st_data2, ax=ax1) # 첫번째 칸에 표 삽입
sns.boxplot(x = "reading_score", data = st_data2, ax=ax2) # 두번째 칸에 표 삽입
sns.boxplot(x = "writing_score", data = st_data2, ax=ax3) # 세번째 칸에 표 삽입
sns.boxplot(x = "avg_score", data = st_data2, ax=ax4) # 네번째 칸에 표 삽입
Python
복사
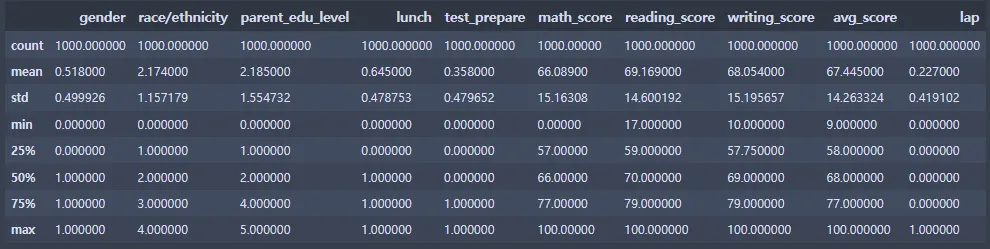
st_data2.describe()
Python
복사
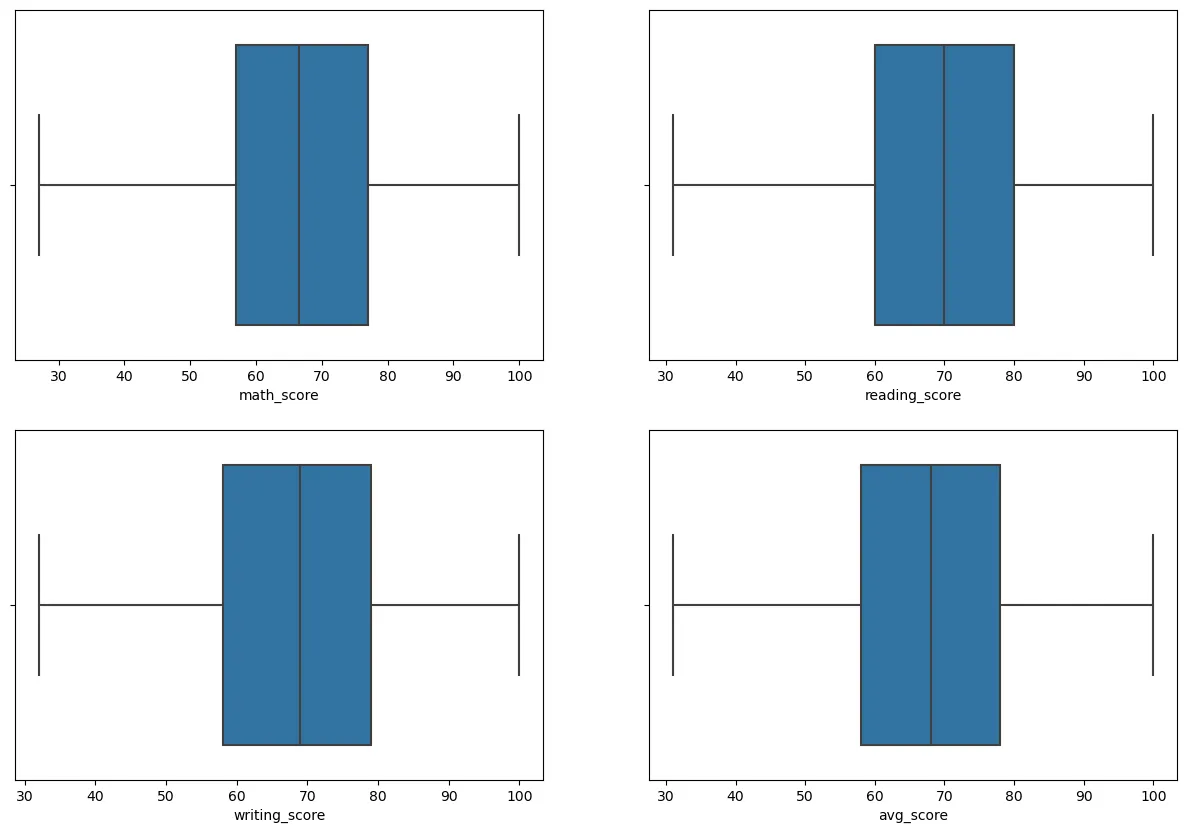
#st_data3 데이터프레임 생성하여 이상치 제거 이후의 데이터 삽입
st_data3 = st_data2[(st_data2["math_score"]>26) & (st_data2["reading_score"]>29)]
st_data3
Python
복사
figure, ((ax1, ax2), (ax3, ax4)) = plt.subplots(nrows=2, ncols=2)
figure.set_size_inches(15, 10)
sns.boxplot(x = "math_score", data = st_data3, ax=ax1)
sns.boxplot(x = "reading_score", data = st_data3, ax=ax2)
sns.boxplot(x = "writing_score", data = st_data3, ax=ax3)
sns.boxplot(x = "avg_score", data = st_data3, ax=ax4)
Python
복사
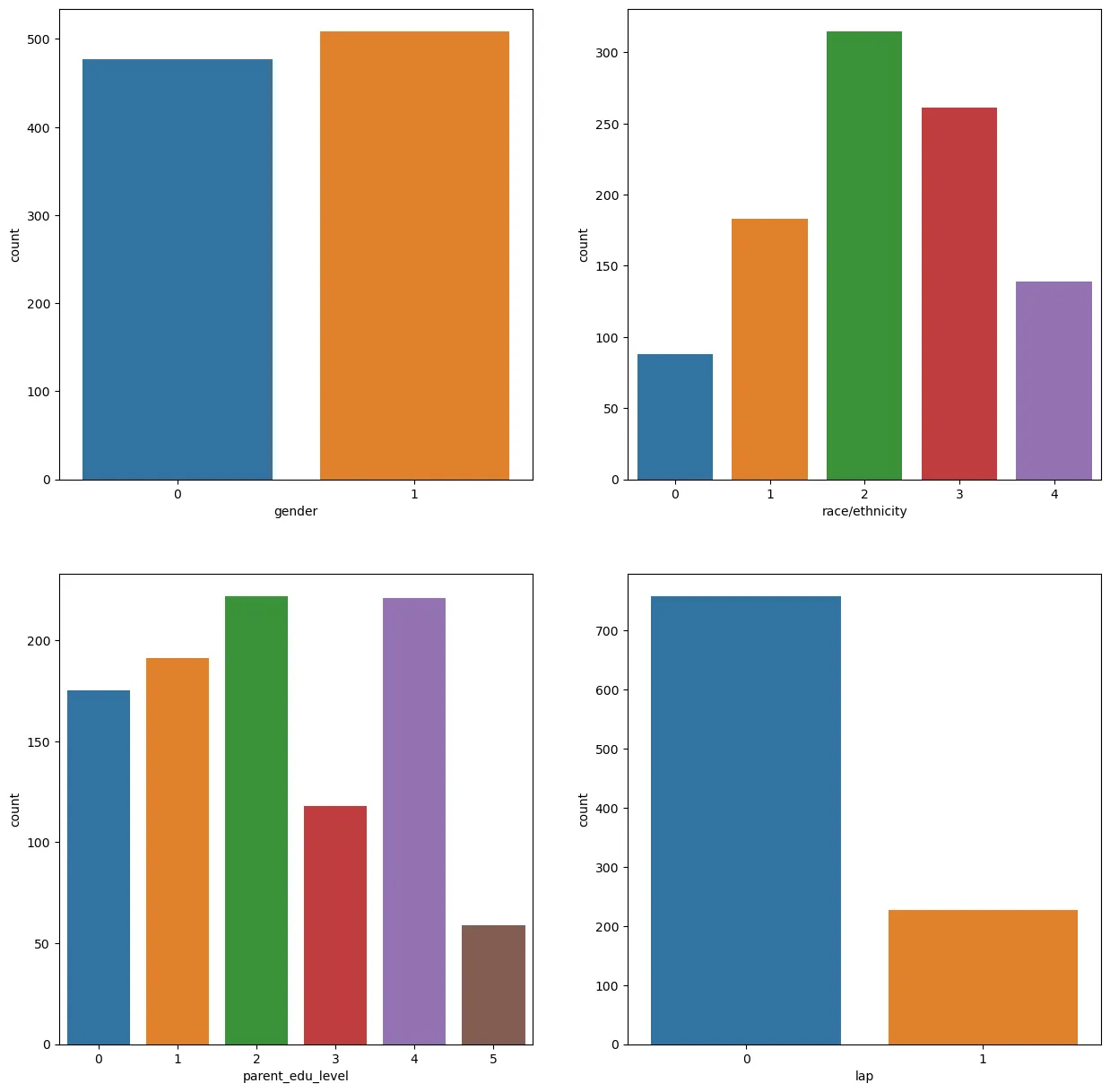
4. 데이터 시각화
figure, ((ax1, ax2), (ax3, ax4)) = plt.subplots(nrows=2, ncols=2) # 가로/세로 2칸으로
figure.set_size_inches(15, 15) # 그래프 크기 지정
sns.countplot('gender', data=st_data3, ax=ax1) # 첫번쨰칸 gender 컬럼 그래프
sns.countplot('race/ethnicity', data=st_data3, ax=ax2) # 두번쨰칸 race/ethinicty 컬럼 그래프
sns.countplot('parent_edu_level', data=st_data3, ax=ax3) # 세번쨰칸 parent_edu_level 컬럼 그래프
sns.countplot('lap', data=st_data3, ax=ax4) # 네번쨰칸 lap 컬럼 그래프
Python
복사
figure, ((ax1, ax2), (ax3, ax4)) = plt.subplots(nrows=2, ncols=2)
figure.set_size_inches(15, 15)
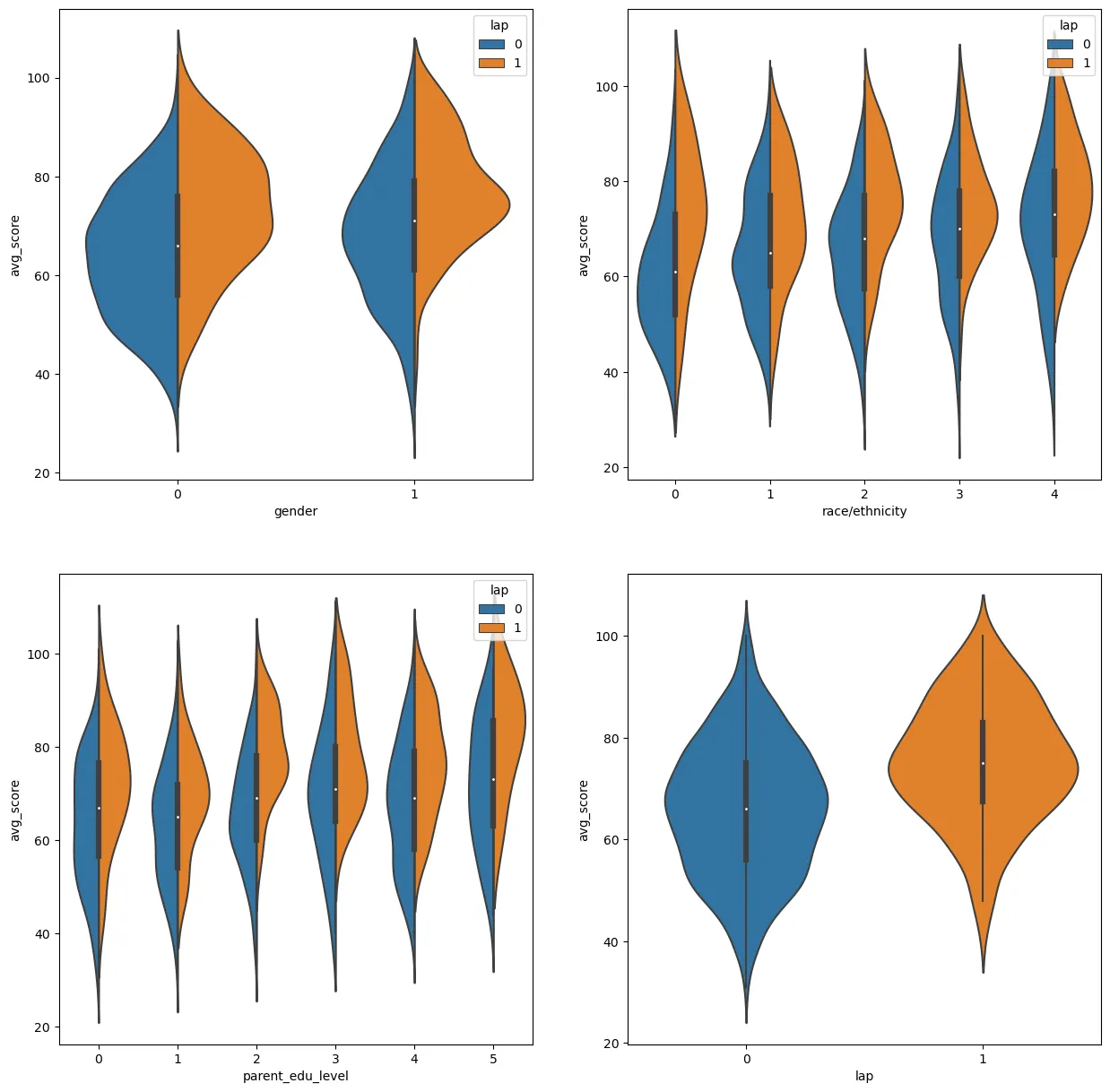
sns.violinplot('gender', 'avg_score', hue='lap', split=True, data=st_data3, ax=ax1)
sns.violinplot('race/ethnicity', 'avg_score', hue='lap', split=True, data=st_data3, ax=ax2)
sns.violinplot('parent_edu_level', 'avg_score', hue='lap', split=True, data=st_data3, ax=ax3)
sns.violinplot('lap', 'avg_score', data=st_data3, ax=ax4)
Python
복사
5. 상관분석
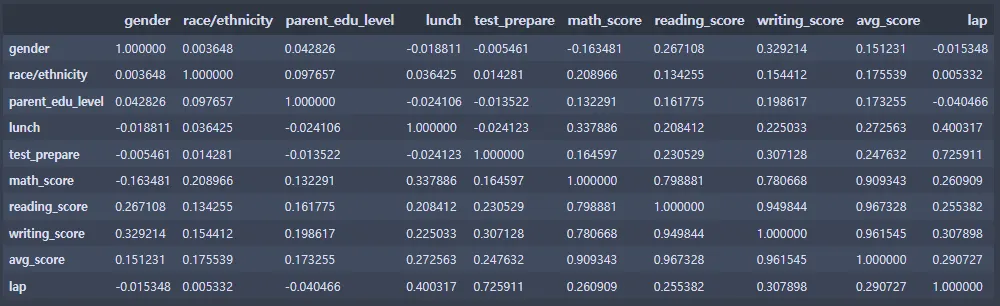
#상관관계 파악(상관계수)
corrMatt = st_data3[['gender', 'race/ethnicity', 'parent_edu_level', 'lunch', 'test_prepare', 'math_score', 'reading_score', 'writing_score', 'avg_score', 'lap']]
corrMatt = corrMatt.corr()
corrMatt
Python
복사
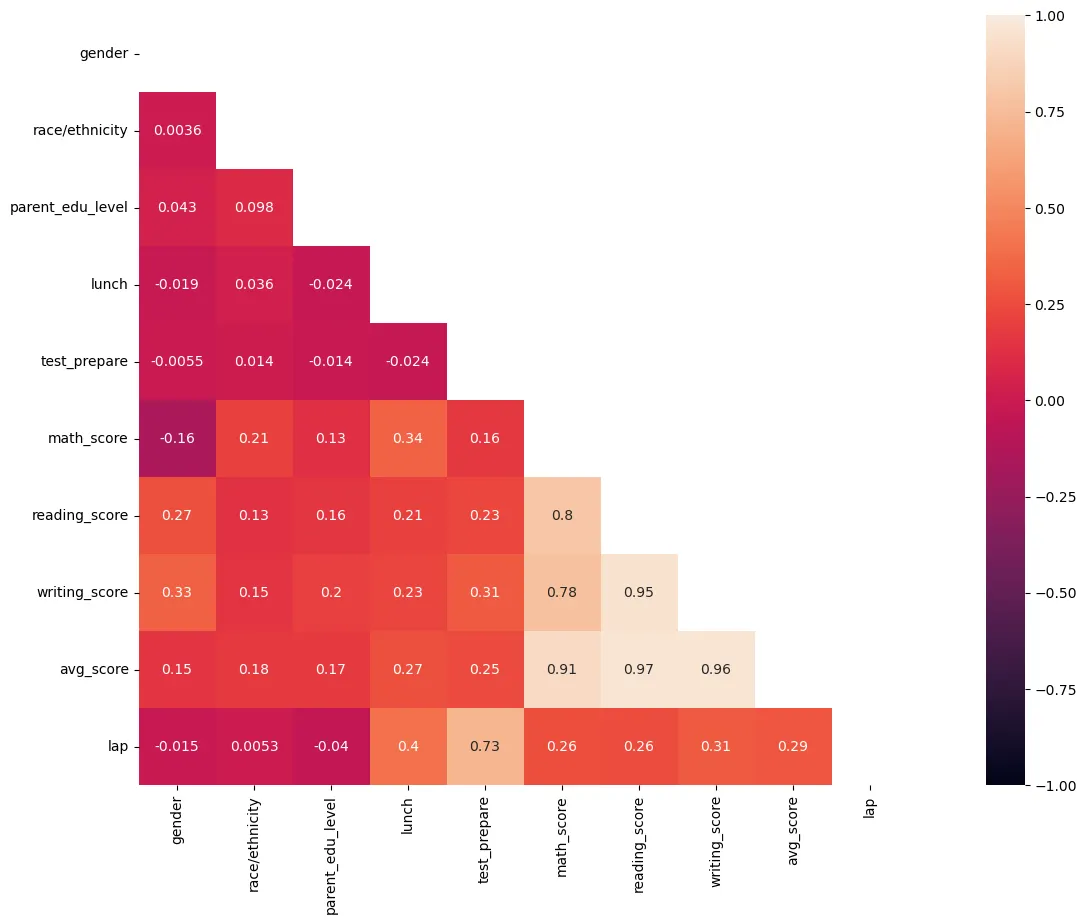
mask=np.zeros_like(corrMatt, dtype=np.bool)
mask[np.triu_indices_from(mask)] = True
figure, ax = plt.subplots()
figure.set_size_inches(20, 10)
#vmin값과 vmax값은 -1, 1값으로 지정하여야 보기 좋다.
sns.heatmap(corrMatt, mask=mask, vmin=-1, vmax=1, square=True, annot=True)
Python
복사
6. 회귀분석
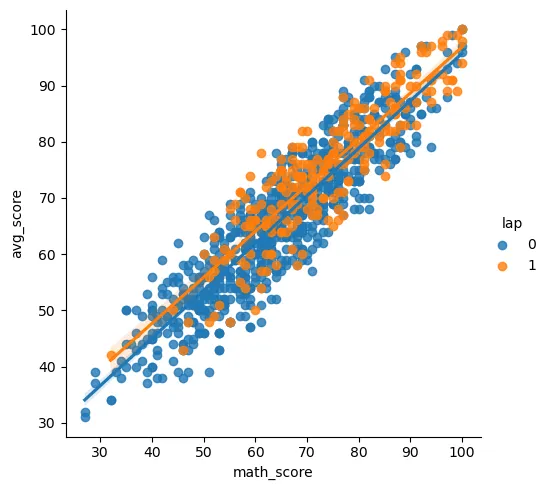
sns.lmplot('math_score', 'avg_score', hue='lap', data=st_data3)
Python
복사
sns.lmplot('reading_score', 'avg_score', hue='lap', data=st_data3)
Python
복사
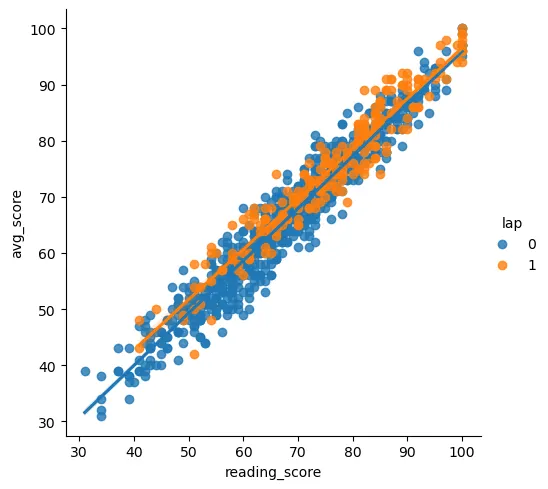
sns.lmplot('writing_score', 'avg_score', hue='lap', data=st_data3)
Python
복사
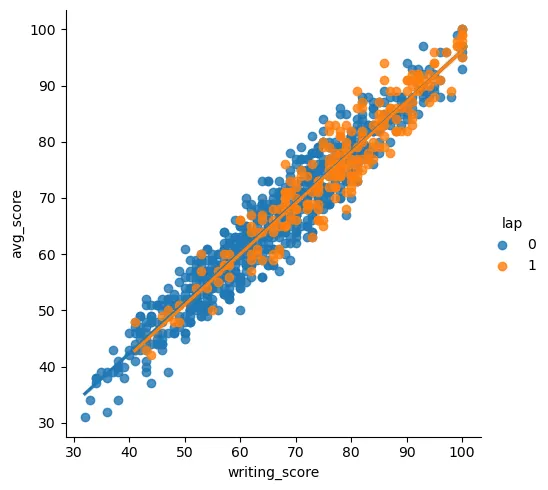
# 단순선형회귀 모형
import statsmodels.api as sm
st_reg=sm.OLS.from_formula("lap ~ math_score + reading_score + writing_score", st_data3).fit()
st_reg.summary()
Python
복사
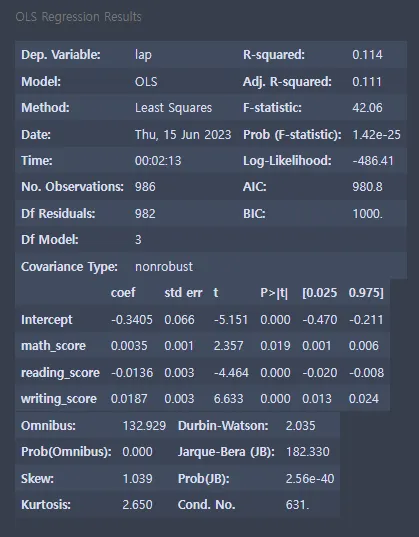
1.
R-square R-square의 값이 0.114이다. R-square 값은 0~1 사이에 있으므로 설명력이 없지 않는 상태이다.
2.
회귀모형 coef 계수를 살펴보면 intercept는 -0.3466, math_score는 0.0036, reading_score는 -0.0130, writing_score는 0.0181이다.
3.
P > |t|(유의확률) P > |t|의 값은 전부 0.05보다 작은 값이 나왔고, 이는 math_score, reading_score, writing_score 변수가 lap 변수에 유의미하게 영향을 미친다는 의미이다.
4.
Durbin-Watson 검정 Durbin-Watson의 값은 2.044이므로, 1.5~2.5 사이이므로 회귀모형이 적합하다.
5.
No.observations No.observations(더빈왓슨, DW검정)값은 971이다. 971개의 데이터 쌍을 가지고 회귀분석을 실시하였다.
6.
Df Residuals Df Residuals값은 967이다.
7. 머신러닝
from sklearn import model_selection
from sklearn import metrics
from sklearn import datasets
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
Python
복사
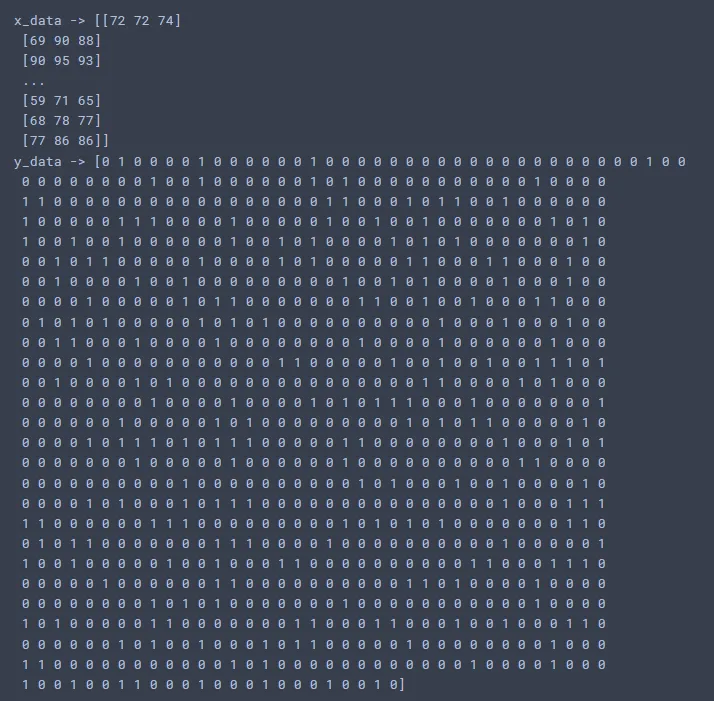
x_data=st_data3.iloc[:, 5:8]
y_data=st_data3.iloc[:,-1]
x_data=x_data.values
y_data=y_data.values
print("x_data ->",x_data)
print("y_data ->", y_data)
Python
복사
x_train,x_test,y_train,y_test = model_selection.train_test_split(x_data,y_data,test_size=0.3)
Python
복사
# 로지스틱 모델링
estimator=LogisticRegression(penalty='l2',dual=False,tol=0.0001,C=1.0,fit_intercept=True,intercept_scaling=1,class_weight=None,verbose=0,warm_start=False,n_jobs=1)
estimator.fit(x_train,y_train)
Python
복사
LogisticRegression(n_jobs=1)
# train 학습
y_predict = estimator.predict(x_train)
score=metrics.accuracy_score(y_train,y_predict)
print('train score: ',score)
Python
복사
train score: 0.7666666666666667
# test 평가
y_predict = estimator.predict(x_test)
score=metrics.accuracy_score(y_test,y_predict)
print('test score: ',score)
Python
복사
test score: 0.8040540540540541
8. 결론
•
lunch 변수의 그룹 분석으로 알 수 있었던 것은 표준 양으로 밥을 먹었던 학생의 평균 점수가 높다는 것이었다.
•
동시에, test preparation course 변수를 그룹 분석 한 결과, 시험 준비 코스를 했던 학생의 평균 점수가 더 높게 나왔다.
•
그러므로 시험 점수가 높은 학생들은 표준 양의 밥을 먹고, 시험 준비 코스도 하였을 것이라는 예상을 하였고, lunch 변수와 test_prepare(원 이름: test preparation course)변수의 값이 모두 1일때만 1의 값을 가지는 lap 변수를 만들어 내었다.
•
표준 양의 밥을 먹고, 시험 준비 코스를 거친 학생이 점수가 더 높게 나온다는 사실을 시각화에서 확인 할 수 있었다.
•
lunch 변수와 test_prepare(원 이름: test preparation course) 변수가 상관관계에서 뚜렷한 상관관계를 나타내었다.
•
로지스틱 회귀 분석을 해본 결과, 73%의 정확도로 시험 점수가 높으면 표준 양의 밥을 먹고, 시험 준비(연습) 코스를 한 학생일 가능성이 높다는 예측을 이루어 내었다.
•
이상치 데이터를 좀 더 조절하면 정확도가 더 높게 나올것으로 예상된다.
•
시험을 잘 본 학생들은 대체로 표준 양의 밥을 먹고, 시험 준비 코스도 하였다.
•
그렇기 때문에, 밥도 잘먹고, 시험 준비도 잘해야 좋은 점수를 받을 가능성이 있다.