최적화(Optimization)
최적화란 손실 함수(Loss Function) 값을 최소화하는 파라미터를 구하는 과정이다.
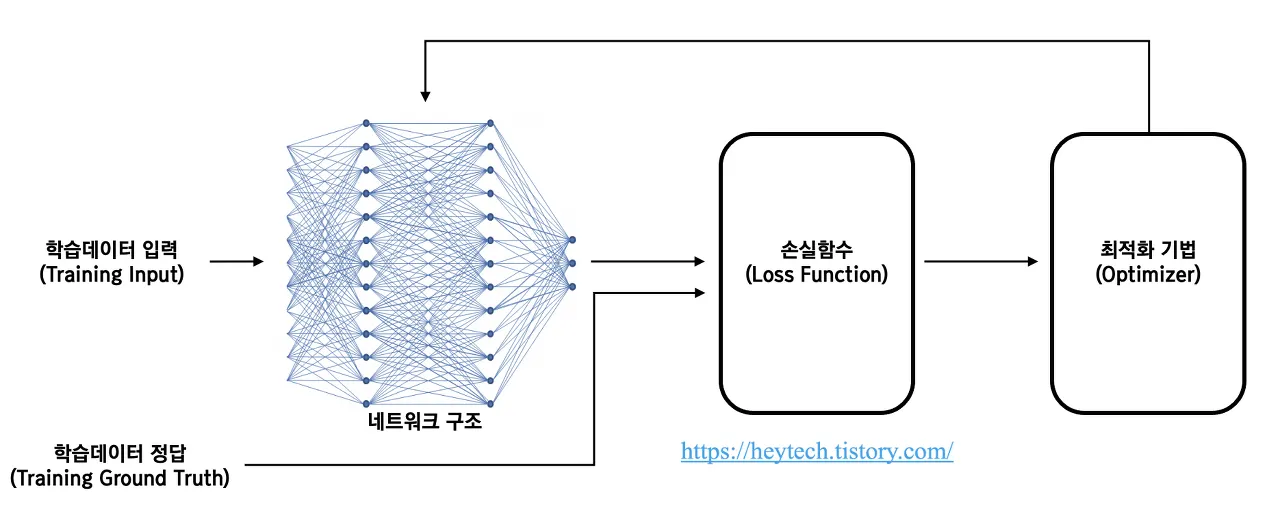
딥러닝에서는 학습 데이터를 입력하여 네트워크 구조를 거쳐 예측값()을 얻는다. 이 예측값과 실제정답()와의 차이를 비교하는 함수가 손실 함수이다.
즉, 모델이 예측한 값과 실젯값의 차이를 최소화하는 네트워크 구조의 파라미터(a.k.a., Feature)를 찾는 과정이 최적화이다.
모험가 이야기
책에서는 최적화를 해야하는 우리의 상황을 모험가에 비유한다.
색다른 모험가가 있습니다. 광활한 메마른 산맥을 여행하면서 날마다 깊은 골짜기를 찾아 발걸음을 옮깁니다. 그는 전설에 나오는 세상에서 가장 깊고 낮은 골짜기. ‘깊은 곳’을 찾아가려 합니다. 그것이 그의 여행 목적이죠. 게다가 그는 엄격한 ‘제약’ 2개로 자신을 옭아맸습니다. 하나는 지도를 보지 않을 것. 또 하나는 눈가리개를 쓰는 것입니다. 지도도 없고 보이지도 않으니 가장 낮은 골짜기가 광대한 땅 어디에 있는지 알도리가 없죠. 그런 혹독한 조건에서 이 모험가는 어떻게 '깊은 곳’을 찾을 수 있을까요? 어떻게 걸음을 옮겨야효율적으로 ‘깊은 곳을 찾아낼 수 있을까요?
이 어려운 상황에서 중요한 단서가 되는 것이 땅의 ‘기울기’이다.
기울기(Gradient)
기울기란 미분 가능한 개의 다변수 함수 를 각 축이 가리키는 방향마다 편미분한 것이다.
Gradient를 수식으로 나타내면 아래와 같다.
(은 으로, 미분 연산자로 생각하면 된다)
이처럼 Gradient는 스칼라 함수를 입력으로 받아 벡터장(Vector Field)을 생성하는 역할을 한다. 예를 들어, 함수 가 다음과 같이 주어졌다고 가정해 보자.
함수 를 와 축으로 각각 편미분하면 다음과 같다.
즉, 는 의 함수이자 모든 축에 대응되는 벡터를 생성할 수 있다는 것을 알 수 있다.
경사 하강법(Gradient Descent)
경사 하강법(Gradient Descent)이란 딥러닝 알고리즘 학습 시 사용되는 최적화 방법 중 하나이다.
딥러닝 알고리즘 학습 시 목표는 예측값과 정답값 간의 차이인 손실함수의 크기를 최소화시키는 파라미터를 찾는 것이다.
학습 데이터 입력을 변경할 수 없기 때문에, 손실 함수 값의 변화에 따라 가중치(weight) 혹은 편향(bias)을 업데이트해야 한다. 그럼 어떻게 최적의 가중치나 편향을 찾을 수 있을까?
최적의 가중치를 찾는 과정을 소개한다. 최적의 편향을 찾는 과정 역시 절차는 동일하다.
아래의 그림에서 가로축은 가중치를, 세로축은 손실 함수를 의미한다. 먼저 임의의 가중치를 선정한다. 운이 좋다면 손실 함수의 최솟값에 해당되는 가중치를 단번에 선택할 수도 있겠지만 그렇지 않을 확률이 훨씬 높다.
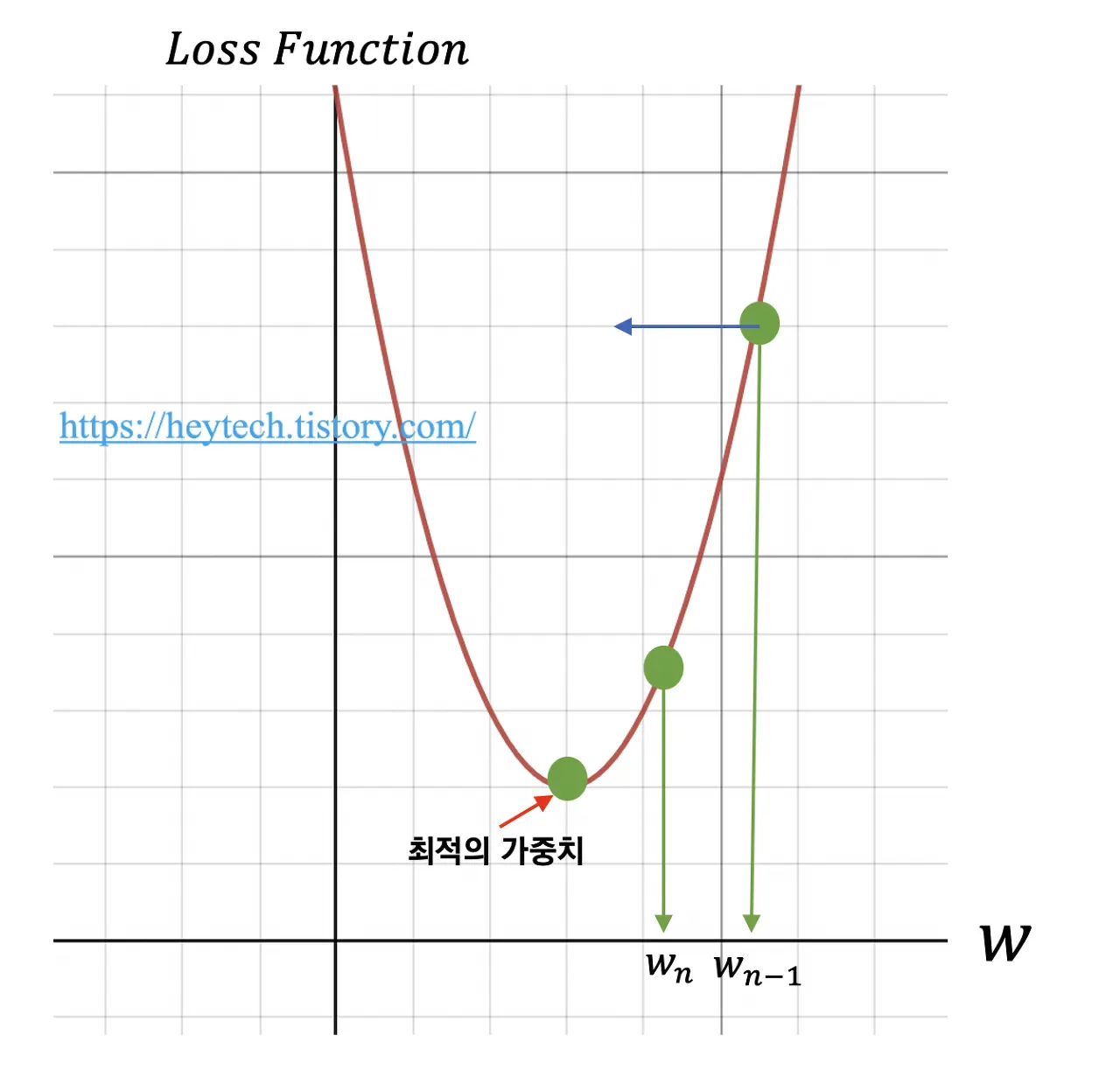
예를 들어, 을 임의의 가중치로 가정한다. 최적의 가중치를 찾기 위해서 목표 함수인 손실 함수를 비용 함수 에 대해 편미분하고, 이를 학습률(Learning rate)과 곱한 값을 앞서 선정한 에서 빼준다. 수식으로 나타내면 다음과 같다.
위 수식을 통해 손실 함수의 값이 거의 변하지 않을 때까지(약)가중치를 업데이트하는 과정을 반복한다. 이처럼 손실 함수 그래프에서 값이 가장 낮은 지점으로(=손실 함수의 최솟값) 경사를 타고 하강하는 기법을 경사 하강법(Gradient Descent)이라고 부른다.
경사 하강법의 분류
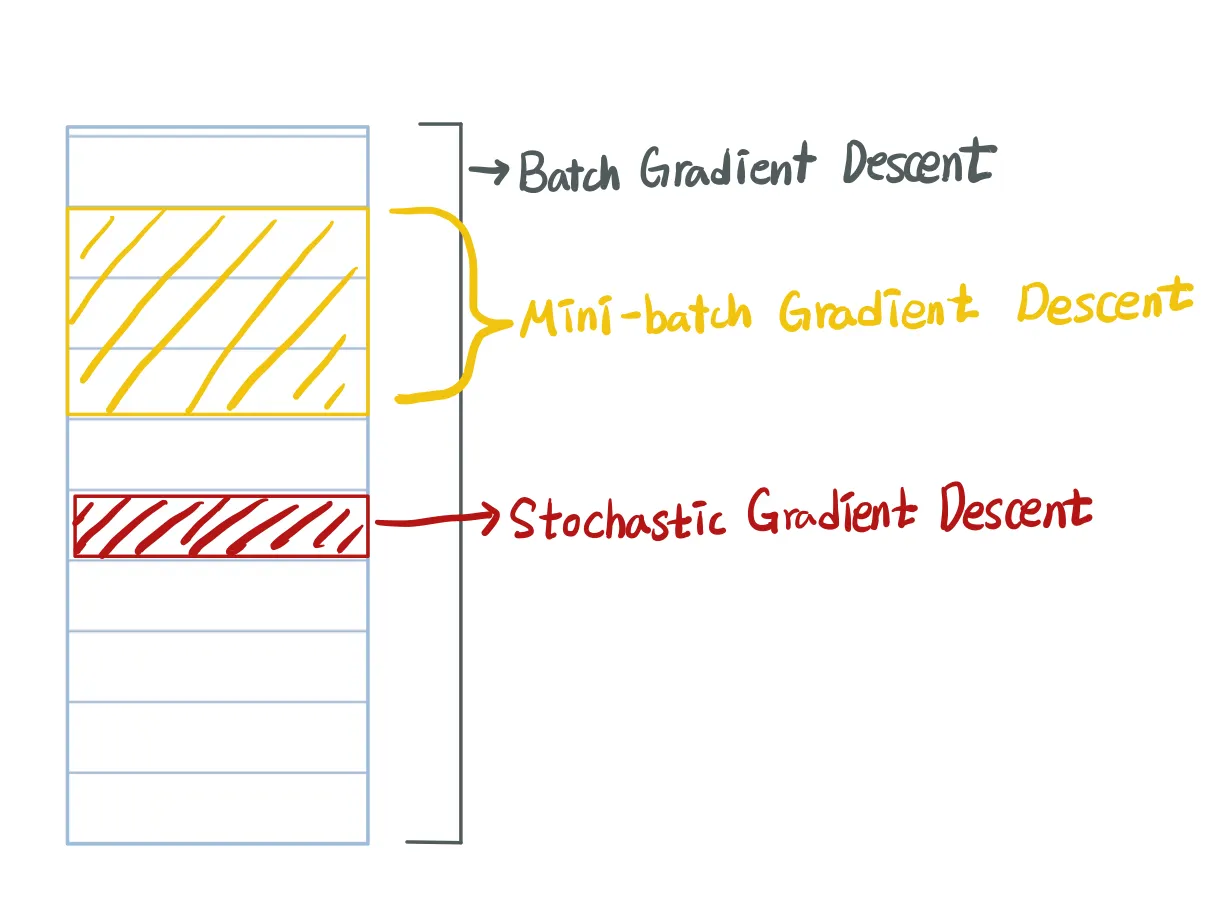
경사 하강법은 한 iteration에서 다룰 데이터 크기에 따라 세 가지로 나눌 수 있다.
•
Batch Gradient Descent(BGD) : 전체 데이터 셋에 대한 에러를 구한 뒤, 기울기를 한 번만 계산하여 모델의 parameter를 업데이트 하는 방법
•
Stochastic Gradient Descent(SGD) : 임의의 하나의 데이터에 대해서 에러를 구한 뒤 기울기를 계산하여, 모델의 parameter를 업데이트 하는 방법. (확률적 경사 하강법)
•
Mini-batch Gradient Descent(MGD) : 전체 데이터 셋에서 뽑은 Mini-batch의 데이터에 대해서 각 데이터에 대한 기울기를 구한 뒤, 그것의 평균 기울기를 통해 모델의 parameter를 업데이트 하는 방법
MGD에 대한 설명
training data가 5,000,000개가 있고 mini-batch size를 1000개로 잡는다면,
각 mini-batch는 1000쌍의 x,y로 이루어지며 총 mini-batch set은 5000개가 된다.
이를 mini-batch의 데이터의 기울기를 모두 구하여 평균한 후, 가중치 업데이트를 진행하는 for문으로 구성한다. for문이 모두 돌았을때, 즉 (전체 데이터 수)/(mini-batch size) = 5,000,000/1000 = 5000번의 iteration이 완료되는 것이 1epoch이다.
전체 데이터가 m개 일 때,
•
mini-batch size = m → Batch Gradient Descent
•
mini-batch size = 1 → Stochastic Gradient Descent
•
mini-batch size = n < m → Mini-batch Gradient Descent

각 방식의 장단점
BGD - 전체 데이터에 대하여 오차를 계산.
•
장점 : loss가 안정적으로 수렴 (cost function의 optimal로 안정적으로 수렴)
•
단점 : 한 iteration에 모든 데이터셋을 사용하기 때문에 학습이 오래 걸림, local optimal을 빠져나오기 힘듦
SGD - 한 번의 iteration마다 한 개의 sample로 gradient descent 하기에, 그나마 최적의 local minimum에 도달함.
•
장점 : local minimum에 빠질 위험이 적음
•
단점 : 다른 optimal을 찾지 못할 가능성이 있음, 다른 알고리즘에 비해 속도가 느림.
MGD - 한 번의 iteration마다 n(1<n<m)개의 데이터를 사용함.
•
BGD와 SGD의 장점을 합친 알고리즘. MGD를 사용할 때는 mini-batch size를 잘 설정해야 함.
→ small training set (대략 m < 2000) : BGD 사용
→ Typical mini-batch size :
1.
64, 128, 256, 512… 컴퓨터는 2진수로 계산되기 때문에 batch size는 대체로 으로 설정.
2.
mini-batch 쌍이 GPU/CPU에 모두 들어가게 설정.
경사 하강법의 한계
경사 하강법은 크게 2가지 한계점이 있다.
•
첫째, Local Minimum에 빠지기 쉽다는 점
•
둘째, 안장점(Saddle point)을 벗어나지 못한다는 점
각각에 대해 알아보자.
Local Minimum 문제
경사 하강법은 비볼록 함수의 경우, 파라미터의 초기 시작 위치에 따라 최적의 값이 달라진다는 한계가 있다.
•
볼록 함수(Convex Function)
아래 그림과 같이 아래 또는 위로 볼록한 함수를 볼록 함수라고 한다. 이러한 볼록 함수는 초기 파라미터 값이 어떻게 설정되어도 경사 하강법을 활용하면 최적의 값에 도달할 수 있다. 다만, 현실에서는 대부분의 함수가 비볼록 함수 형태이다.
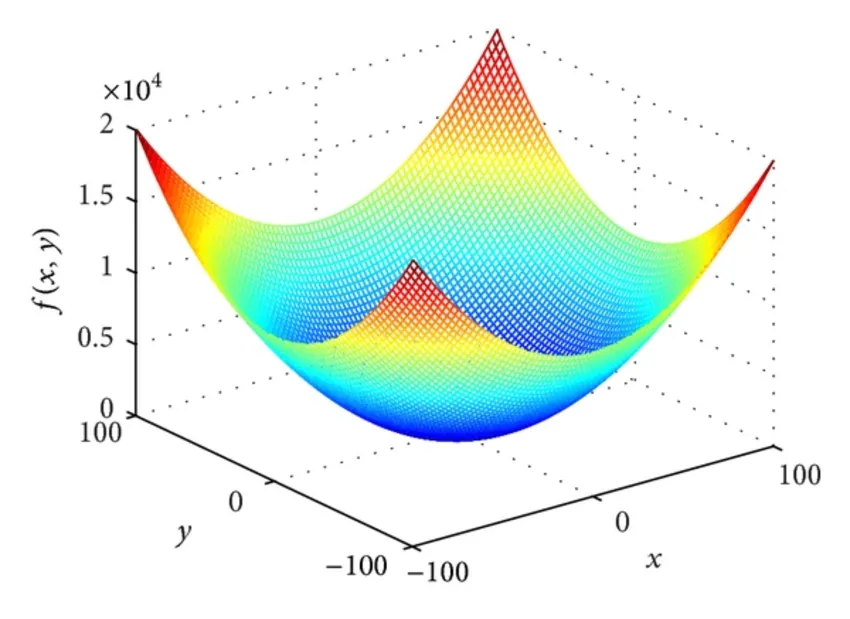
•
비볼록 함수(Non-Convex Function)
아래 그림과 같은 비볼록 함수는 경사 하강법 사용 시 파라미터 값의 시작 위치에 따라 최적의 값이 달라진다는 한계가 있다.
즉, Local Minimum에 빠질 수 있고 심지어는 최적의 값이라고 판단한 값이 Global minimum인지, Local minimum인지 구분할 수 없다는 한계가 있다.
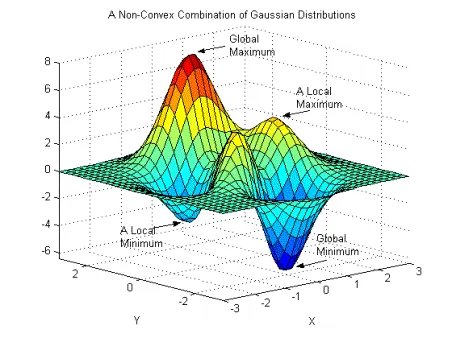
아래의 그림과 같이 Global minimum은 목표 함수 그래프 전체를 고려했을 때 최솟값을 의미하고, Local minimum은 그래프 내 일부만 고려했을 때 최솟값을 의미한다. 즉, 경사 하강법으로 최적의 값인 줄 알았던 값이 Global minimum보다 큰 경우를 Local minimum이라고 할 수 있다.

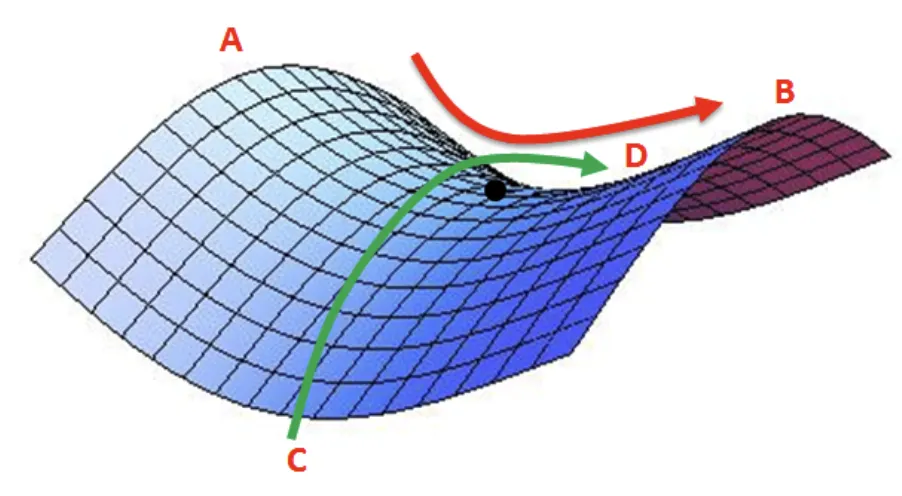
Saddle Point 문제
경사 하강법의 두 번째 한계점은 안장점(Saddle Point)을 벗어나지 못한다는 것이다. 아래 그림의 검정색 점이 안장점이다. 말(horse)의 안장과 비슷한 모양 위에 있는 점이라 안장점이라고 이름 붙여졌다고 한다. 안장점은 기울기가 0이지만 극값이 아닌 지점을 의미한다.
아래 그림과 같이, A-B 사이에서 검은색 점은 최솟값(minima)이지만, C-D 사이에서 검은색 점은 최댓값(maximam)이다. 따라서 해당 지점은 미분이 0이지만 극값을 가질 수 없다. 경사 하강법은 미분이 0
일 경우 더 이상 파라미터를 업데이트하지 않기 때문에, 이러한 안장점을 벗어나지 못하는 한계가 있다.