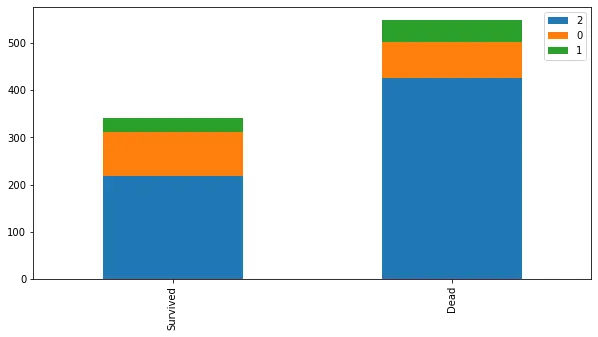import pandas as pd
import matplotlib as mpl
import matplotlib.pylab as plt
import seaborn as sns
import numpy as np
# 상대경로
file_path = 'titanic/train.csv'
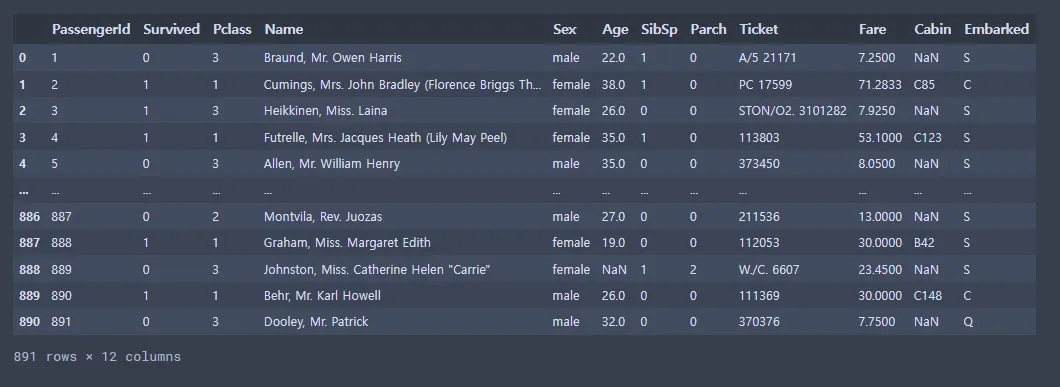
titanic_data = pd.read_csv(file_path, encoding='CP949')
titanic_data
Python
복사
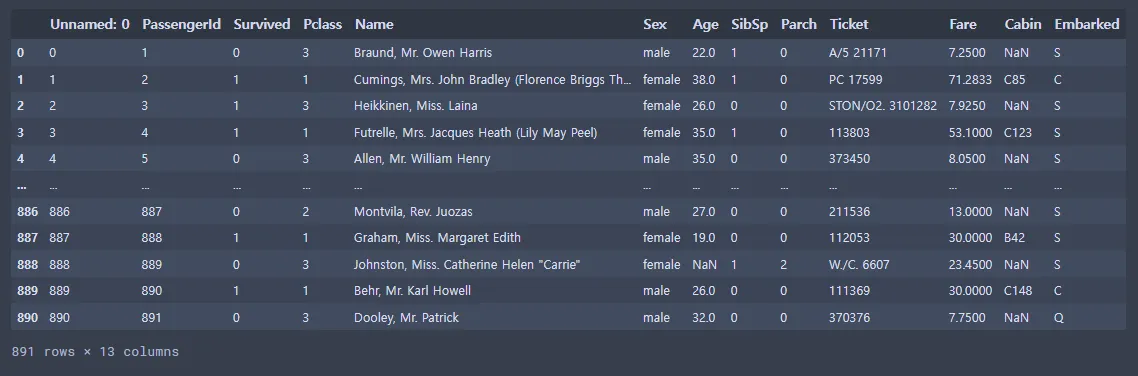
# 백업 파일 생성
titanic_data_copy_backup = titanic_data.copy()
titanic_data.to_csv('titanic/train_backup.csv')
file_path = 'titanic/train_backup.csv'
titanic_data_csv_backup = pd.read_csv(file_path)
titanic_data_csv_backup
Python
복사
titanic_data.info()
Python
복사
컬럼별 데이터 구성 및 타입 확인
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
Plain Text
복사
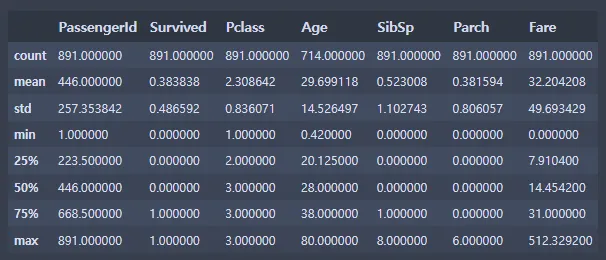
titanic_data.describe()
Python
복사
sex_dict = {'male':0, 'female':1}
titanic_data['Sex'] = titanic_data['Sex'].map(sex_dict)
Python
복사
형변
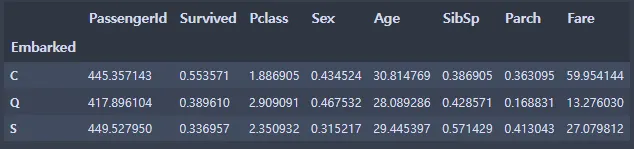
titanic_data.groupby(['Embarked']).mean()
Python
복사
평균값
Embarked_dict = {'C':0, 'Q':1, 'S':2}
titanic_data['Embarked'] = titanic_data['Embarked'].map(Embarked_dict)
Python
복사
형변환
titanic_data
Python
복사
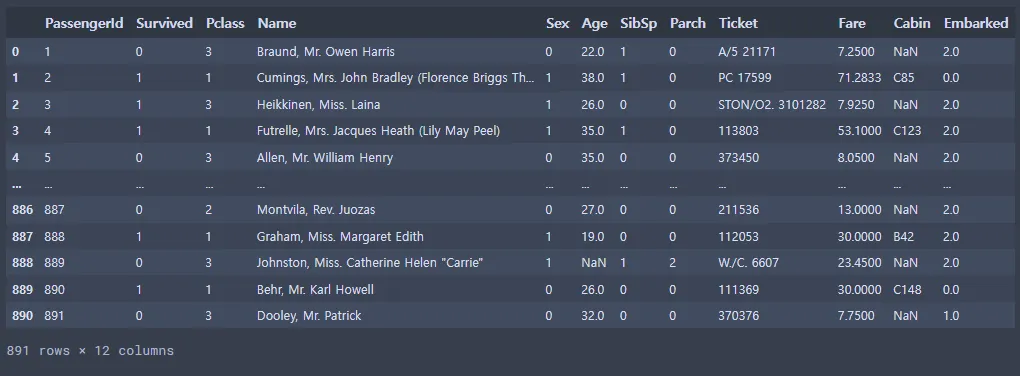
import missingno as msno
titanic_data.isnull().sum()
Python
복사
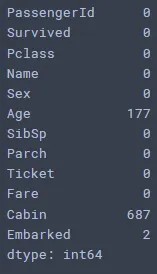
Age, Cabin, Embarked 컬럼에 결측치 확인
msno.matrix(titanic_data)
Python
복사

titanic_data = titanic_data.drop(labels=['Ticket', 'Cabin'], axis=1)
Python
복사
titanic_data['Age'] = titanic_data['Age'].fillna(titanic_data['Age'].median())
titanic_data['Embarked'] = titanic_data['Embarked'].fillna(titanic_data['Embarked'].mode()[0])
Python
복사
Age 컬럼은 중간값, Embarked 컬럼은 최빈값으로 채우기
titanic_data.isnull().sum()
Python
복사
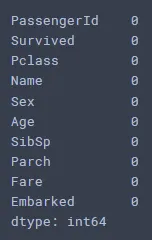
titanic_data['Age'] = titanic_data['Age'].astype(np.int64)
titanic_data['Embarked'] = titanic_data['Embarked'].astype(np.int64)
Python
복사
titanic_data.info()
Python
복사
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null int64
5 Age 891 non-null int64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Fare 891 non-null float64
9 Embarked 891 non-null int64
dtypes: float64(1), int64(8), object(1)
memory usage: 69.7+ KB
Plain Text
복사
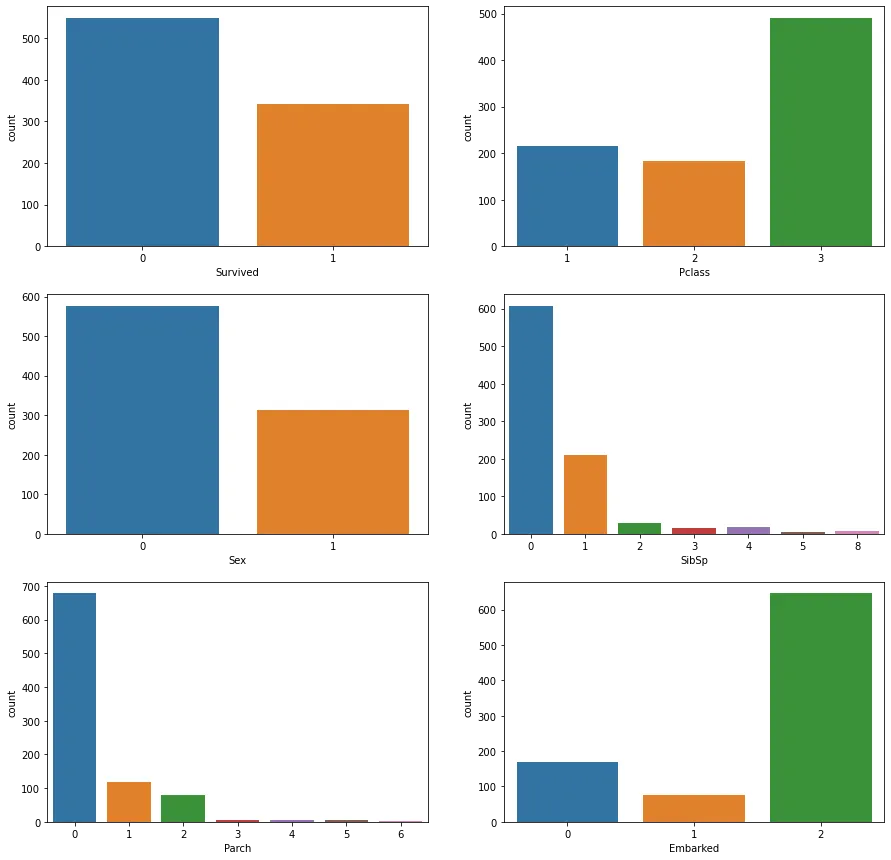
# 표를 2x2로 배열하고, 한 표당 15의 크기로 지정
figure, ((ax1, ax2), (ax3, ax4), (ax5, ax6)) = plt.subplots(nrows=3, ncols=2)
figure.set_size_inches(15, 15)
sns.countplot('Survived', data=titanic_data, ax=ax1)
sns.countplot('Pclass', data=titanic_data, ax=ax2)
sns.countplot('Sex', data=titanic_data, ax=ax3)
sns.countplot('SibSp', data=titanic_data, ax=ax4)
sns.countplot('Parch', data=titanic_data, ax=ax5)
sns.countplot('Embarked', data=titanic_data, ax=ax6)
Python
복사
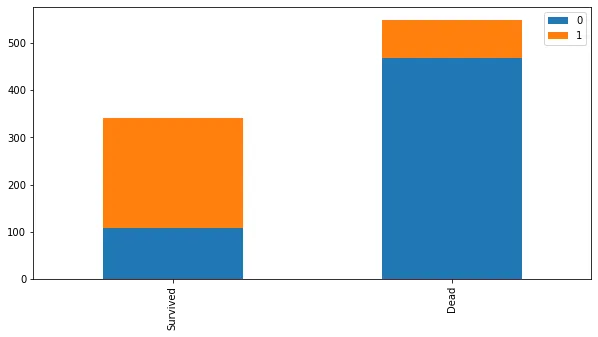
def bar_chart(feature):
survived = titanic_data[titanic_data['Survived']==1][feature].value_counts()
dead = titanic_data[titanic_data['Survived']==0][feature].value_counts()
df = pd.DataFrame([survived,dead])
df.index = ['Survived','Dead']
df.plot(kind='bar',stacked=True, figsize=(10,5))
Python
복사
bar_chart('Sex')
Python
복사
bar_chart('Pclass')
Python
복사
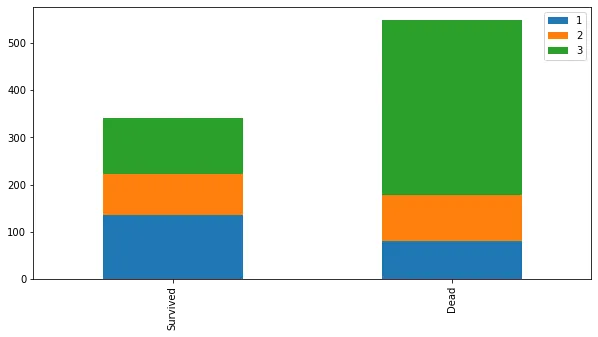
bar_chart('SibSp')
Python
복사
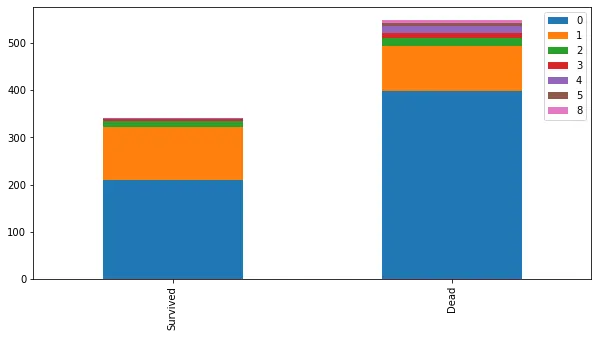
bar_chart('Parch')
Python
복사
bar_chart('Embarked')
Python
복사