최적화된 기술로 문제를 해결하고, 데이터를 통해 사용자 경험을 개선하는 개발자 윤건우 입니다.

[이름] 윤건우
[학력] 가천대학교 컴퓨터공학과 학사 (2024. 02 졸업)
[번호] 010-5129-3787
[이메일] ndbsrjsdn@naver.com

Java, Python 기반 백엔드 개발을 메인으로, 데이터 엔지니어링에 관심을 가지고 Docker, K8s등의 컨테이너 기술 및 인프라 관련 클라우드 서비스를 꾸준히 다뤄보며 개발하고 있습니다.

Java

Python
SpringBoot

FastAPI

MySQL

MongoDB

Redis
Kafka

AWS

Linux

Docker

LangGraph
•
리눅스마스터 2급 (2025.12)
•
SQLD (2023.07)
•
ADsP (2021.12)
•
OPIC IM1 (2023.03)
Programmers DevCourse Cloud BE 1st
사설 교육 | 클라우드 기반 백엔드 개발자 교육과정
2024.08 - 2024.12 | 수료
Kakao Enterprise SW Academy 3rd
사설 교육 | 실무형 SW 엔지니어 교육과정
2023.09 - 2024.02 | 수료
BOAZ 21st
대외 활동 | 데이터 엔지니어링 트랙
2023.07 - 2024.07 | 수료
NIA 공공 빅데이터 분석 청년 인턴십
대외 활동 | 공공데이터 활용 분석 프로젝트형 인턴십
2021.07 - 2022.02 | 수료
(주)동아일보사 백엔드 ND 인턴
[기간] 2026.01 - 재직중
1) 사내 대시보드 서버 유지보수
[활용 기술] Python(FastAPI), AWS(EC2, SES, RDS, ECR, DynamoDB), Docker, Grafana, Loki
•
FastAPI 서버를 유지보수하며 장애대응 및 다양한 최적화를 수행했습니다. 배포 방식을 변경하여 전체 빌드 처리 속도를 약 40% 감소시켰습니고 DB 커넥션 풀 최적화로 재배포시 3초간 콜드스타트 문제를 제거했습니다. 또한 레거시 서비스 마이그레이션을 수행하여 인스턴스 비용을 70% 감소시켰습니다.
•
자주 변하지 않는 조회수 순위별 기사 리스트, 기사 조회수 통계 데이터를 DynamoDB에 캐싱하고, 자주 쓰이는 join query의 핵심 키에 대한 인덱스를 생성하여 조회 속도를 98% 개선하고 250ms 내외의 API 응답 속도를 보장하도록 했습니다.
•
기존 인증코드 체계에서 보안 강화 및 사용자 로그 수집을 위한 로그인 기반 인증/인가 및 메일 시스템을 개발해, 불필요한 외부 요청을 차단하고 정제된 시스템 로그 분석을 수행했습니다.
2) 플랫폼별 실시간 데이터 수집 파이프라인 설계 및 운영
[활용 기술] Python, AWS(Lambda, EventBridge, SQS, RDS, DynamoDB, SNS), MCP, LLM, Slack
•
월별 조회수 분석 시 조회수 오차를 해결하기 위해 기간별 Payload를 적용한 배치 수집 람다를 개발했습니다. GA와 연동하는 과정에서 토큰 소모를 최적화하기 위해 요청 알고리즘을 수정하여 처리속도를 약 18배 개선했습니다.
•
실시간성이 중요한 데이터는 수집 시 캐시 업데이트를 먼저 한 후 SQS를 통해 데이터베이스에 저장하고, 외부 API 요청 속도가 필요한 경우 SQS의 속도 지연과 최대 메세지 수신 값을 조정하여 429 에러를 방지했습니다.
•
CloudWatch, SNS, Amazon Q, Slack을 연결하여, 발생한 에러에 대한 내용과 해결 방식을 함께 모니터링하는 알림 파이프라인을 개발했습니다. AWS MCP를 연결하여 관리자가 프롬프트로 내부 인프라 아키텍처를 확인하고 취약점을 자동으로 찾아내, HCL코드로 해결하는 시스템을 개발했습니다.
3) LLM 기반 기사 아젠다 추천 시스템 개발
[활용 기술] Python(FastAPI), LangGraph, PostgreSQL, Neo4j, NLP(spaCy), LLM(gpt-4o-mini), AWS, Docker
•
한국어 뉴스 기사에서 엔티티 추출 -> 프로파일링 -> 메타데이터 보강 -> 의제 분석을 자동화하는 멀티 스테이지 파이프라인을 LangGraph 기반으로 설계했습니다.
•
5개 언론사의 10만개 기사 데이터를 대규모로 처리하기 위해 asyncio기반 비동기 병렬 LLM 호출을 적용했고, 주요 엔티티들에 대한 사전 alias 매칭, 저빈도 엔티티 사전 필터링 등을 활용해 초기 대비 전체 LLM 호출 비용을 약 80% 절감했습니다. 또한 카테고리별로 차별화된 프롬프트 설계를 통해 각 메타데이터를 안정적으로 추출하게 했습니다.
•
엔티티 중심 지식 그래프를 Neo4j에 모델링하여 행동/발언/입장/관계로 구조화했습니다. 이슈 시나리오를 입력하여 과거 패턴 기반 시뮬레이션을 수행하여 각 엔티티의 추후 입장, 예상 반응 등을 추출해, 후속 기사 의제를 추천하는 사내 AI 서비스를 개발했습니다.
(주)B2EN AI 데이터 QA 인턴
[기간] 2022.07 - 2022.12 (6개월)
1) AI Hub의 공개데이터 정합성 QA
[활용 기술] AWS Athena SQL, AWS S3, SDQ for AI(자사 분석 툴)
•
•
S3에 적재된 데이터를 기반으로 AWS Athena Query를 활용하여 데이터를 조회하고 이상치에 대한 정보를 추출했습니다. 또한 개선 및 수정사항에 대해 TTA측에 해당 내용을 전달하는 리포트를 작성하는 등 데이터 품질 관리 업무의 전반적인 과정을 모두 수행했습니다.
2) 이미지 데이터 라벨링 플랫폼 MVP 개발
[활용 기술] Python(FastAPI), PostgresDB, PyTorch
•
데이터 라벨링 플랫폼의 초기 MVP를 개발했습니다. 라벨링 작업의 전체 흐름을 데이터 업로드 → 작업 할당 → 모델 추론 → 결과 수집 → label export로 정의하고, 각 단계에 대한 API를 개발하여 플랫폼의 초기 기능을 완성했습니다. 이후 추가 개발과 기능 고도화를 위해 서비스 구조도와 API 명세서 등을 작성하여 문서화하였습니다.
•
YOLO, U-Net등의 모델을 직접 튜닝하고 적합한 모델을 적용했습니다. 이를 위한 팀 내 딥러닝 스터디를 만들어 개발 기간 동안 Object Detection에 대한 학습을 진행했습니다.
League of Legends 패치노트 기반 챔피언 추천 서비스
[기간] 2023.12 - 2024.06 (6개월)
[인원] 4명 (Backend Engineer, Data Engineer, AI Engineer)
[개요] 리그 오브 레전드 패치노트 데이터 기반 유저 맞춤형 챔피언(게임 캐릭터) 개인화 추천 서비스
•
[뉴스레터 서비스] 공식 게임 업데이트 정보(패치노트)의 변동 사항을 기반으로 사용자가 자주 플레이하는 챔피언에 맞춰 뉴스레터 구독 서비스를 통해 업데이트 버전별 추천 챔피언을 안내해줍니다.
•
[사용자 전적 검색] Riot API와 연동하여 사용자의 지난 게임에 대한 전적을 검색합니다. KDA, 팀원 정보, 구매 아이템 정보 등 해당 게임에 대한 다양한 정보를 제공합니다.
[개발 환경 및 기술 스택]
•
Backend: SpringBoot 3.2.3 (Java 17), Kotlin 1.9.22
•
DB: MySQL(RDS), MongoDB
•
Data ETL: AWS Lambda, AWS S3, Python 3.10
•
Infra: AWS EC2, Apache Kafka
•
MLOps: MLFlow
•
CI/CD: Jenkins
[GitHub]  GitHubLP.GG
GitHubLP.GG
GitHubLP.GG주요 역할 및 기술 기여
•
Kotlin SpringBoot 기반 멀티모듈 아키텍처 설계 (API-Domain-Storage-Infra)
•
챔피언, 패치노트, 사용자 전적에 대한 데이터 ETL 파이프라인 자동화
◦
Riot DataDragon을 활용한 167개 챔피언 능력치 데이터베이스 구축
◦
AWS Lambda + EventBridge로 1시간 간격 패치노트 업데이트 확인 및 크롤링
◦
AWS S3, RDS 적재
•
Spring Security, JWT 활용 admin 모듈 개발
•
Riot 계정 연동 전적 검색 API 개발
•
분당 100건 전적 데이터 배치 처리 후, MongoDB 적재. Kafka를 활용해 ML 모델 분석과 RDBMS로 분산 처리
•
사용자 메일 구독 요청을 처리하기 위한 Brevo API 메일 서비스 개발
•
빅데이터 학술 컨퍼런스에서 해당 프로젝트 주제로 발표 수행


서비스 아키텍처

멀티모듈 아키텍처

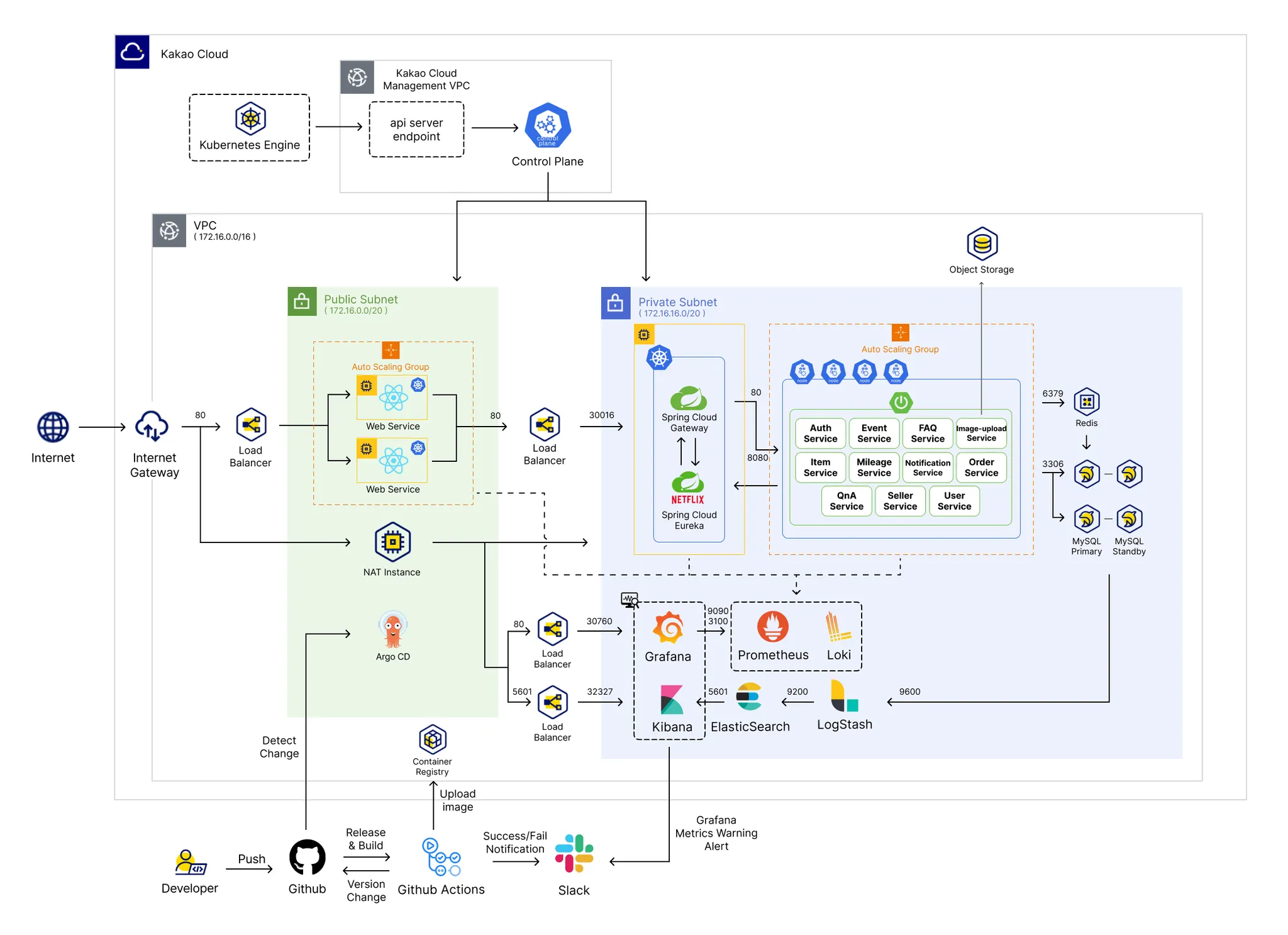
카카오 계열사 dktechin 자사 쇼핑몰 개발 프로젝트

[기간] 2023.11 - 2024.02 (4개월)
[인원] 9명 (PM, Back-end, Front-end, Infra)
[개요] dktechin 자사 쇼핑몰 개발 기업 실무 프로젝트
[개발 환경 및 기술 스택]
•
Frontend: React
•
Backend: SpringBoot 3.2.1 (Java 17)
•
DB: MySQL, Redis
•
Infra: Kakao Cloud, Docker, K8s
•
Monitoring: Elastic, Grafana, Loki, Prometheus
•
CI/CD: GitHub Actions, Argo CD
[GitHub]
주요 역할 및 기술 기여
•
상품 카탈로그 서비스, 리뷰 및 평점 서비스 담당. 각각의 CRUD API 설계 및 개발
◦
User - 상품 조회, 리뷰 조회, 등록
◦
Admin - 상품 조회, 등록, 수정, 삭제, 사용자별 리뷰 조회
◦
System - 재고 수량 자동 변경, 상품 필터링, 인기 상품 등록, 신상품 등록
•
MSA 환경에서의 대규모 웹 서버 운용을 위한 Kakao Cloud 기반 시스템 아키텍처 스케치
•
Feign과 Eureka Client 활용 마이크로 서비스간 통신
•
Circuit Breaker 패턴 적용으로 서비스 장애 격리 및 fallback 처리. 전체 시스템 가용성 향상
•
Specification으로 동적 쿼리 적용하여 다양한 옵션에 대한 상품 검색 필터링 기능 개발
•
Redis INCR 기반 조회수 집계로 인기 상품 조회 기능 개발
•
GitHub Actions Self-hosted Runner 활용하여 빌드 속도 4m → 50s 단축
•
Grafana, Loki, Prometheus 활용 로그 및 메트릭 수집 모니터링 환경 구축