


0. Abstract
•
SSD, discretizes the output space of bounding boxes into a set of default boxes over different aspect ratios and scales per feature map location
→ 각 feature map에서 다른 비율과 스케일의 default box로 bounding box의 output 공간을 나눈다.
feature map? grid
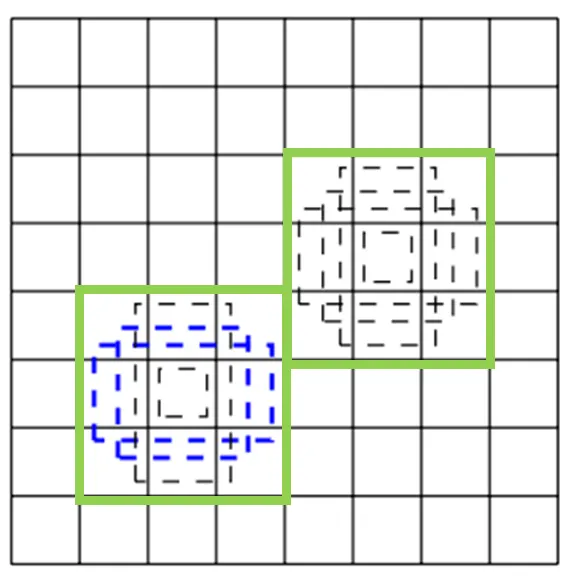
default box? 연두색 안 바운딩 박스로 논문에서는 한 셀당 4 또는 6으로 설정한다.
1. Introduction
•
object detection은 실시간으로 빠르게 처리해야 한다는 task를 가진다.
•
YOLO는 처리가 빠르지만 정확도가 낮음
•
Faster R-CNN은 연산량이 많고, 처리가 느리지만 정확도는 높음
→ 처리 속도와 정확도! 두 마리 토끼를 잡기 위하여 제안됨
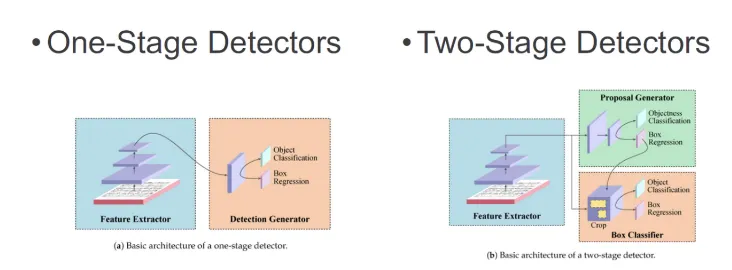
2. The Single Shot Detector(SSD)
•
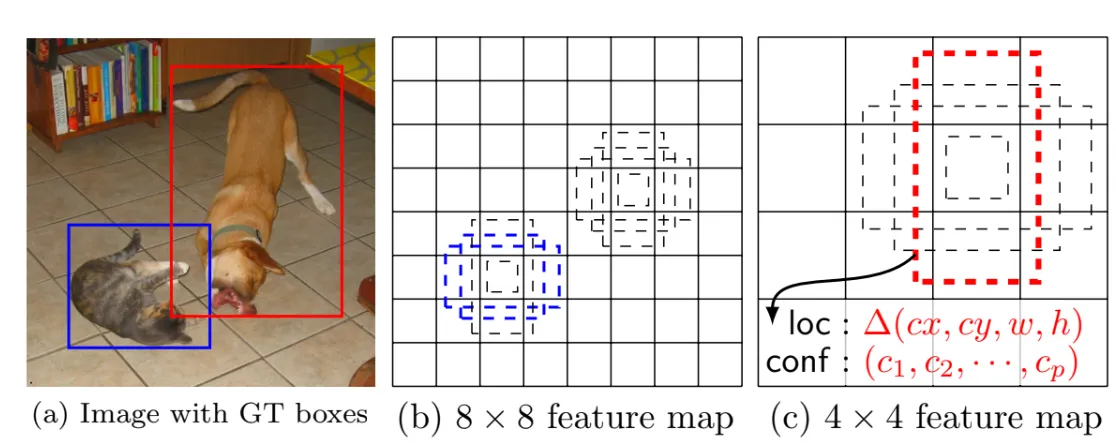
Input : image & ground truth box
•
Output(예측) : loc & conf ⇒ offsets & confidence for all object categories
◦
offsets : - default box의 좌표
▪
는 박스 중심 좌표
▪
는 박스의 너비와 높이
◦
confidence for all object categories : - class의 점수
•
loss : localization loss와 confidence loss의 가중합
•
feature map의 각 cell마다 서로 다른 scale과 aspect ratio를 가진 default box (anchor box)를 사용
•
현미경처럼 작은 feature map은 큰 물체를 탐지, 큰 feature map은 작은 물체를 탐지
2.1 Model
We use the VGG-16 network as a base, but other networks should also produce good results.
•
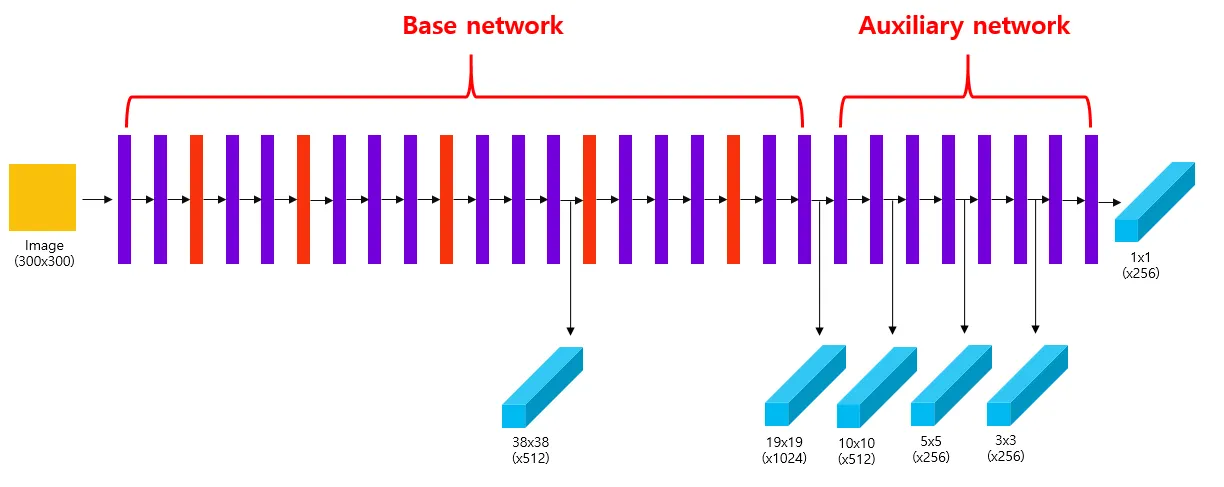
다양한 size의 feature map을 가지고 있다.
•
중간중간 1x1 conv Bottleneck을 적용
•
보조(Auxiliary network) 네트워크
2.1.1 Multi-scale feature maps for detection
•
다양한 size의 feature map을 가지기 때문에 다양한 크기의 객체를 탐지할 수 있다.
•
큰 특성맵(feature map)일수록 작은 객체를 탐지한다.
2.1.2 Convolutional predictors for detection
•
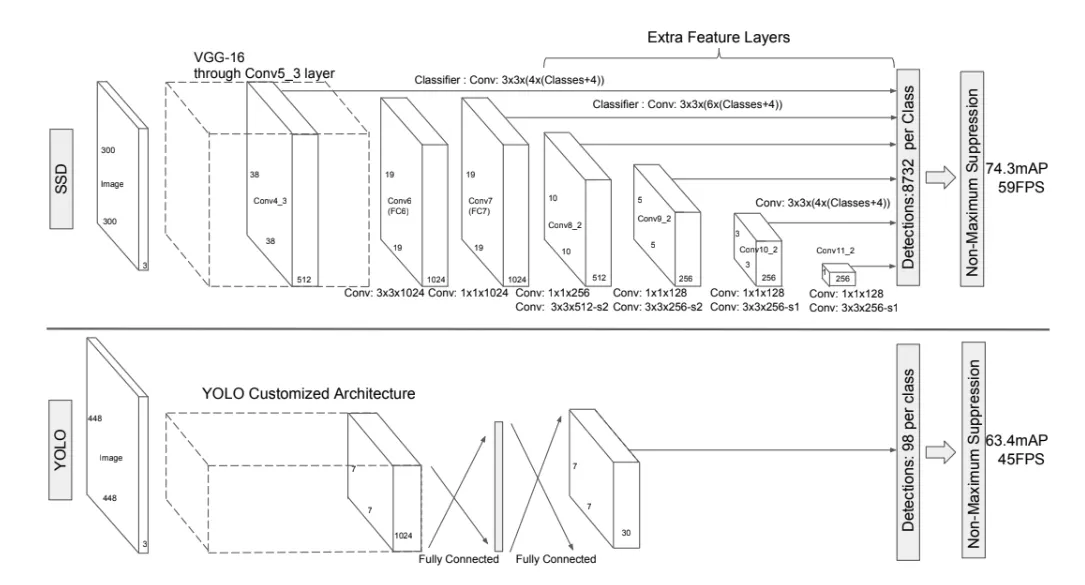
Multi-scale feature map VS Single scale feature map
◦
Multi-scale feture map인 SSD는 YOLO에 보다 높은 정확도를 가짐
•
single stage detection : classification과 localization문제를 동시에 해결하는 방법
◦
클래스 분류와 bbox 회귀를 동시에 진행
◦
SSD는 2-stage인 R-CNN보다 빠른 속도를 가짐
•
VGG16(base network)의 마지막에 여러 개의 Feature layers를 추가
→ base network + extra network(SSD논문에서는 4개의 network)
→ base network로 다른 모델을 적용해도 무방하다. (Ex. ResNet)
•
Convolutional Network 중간의 conv layer에서 얻은 feature map을 포함시켜, 총 6개의 서로 다른 scale의 feature map을 예측에 사용
•
feature map : 38*38, 19*19, 10*10, 5*5, 3*3, 1*1
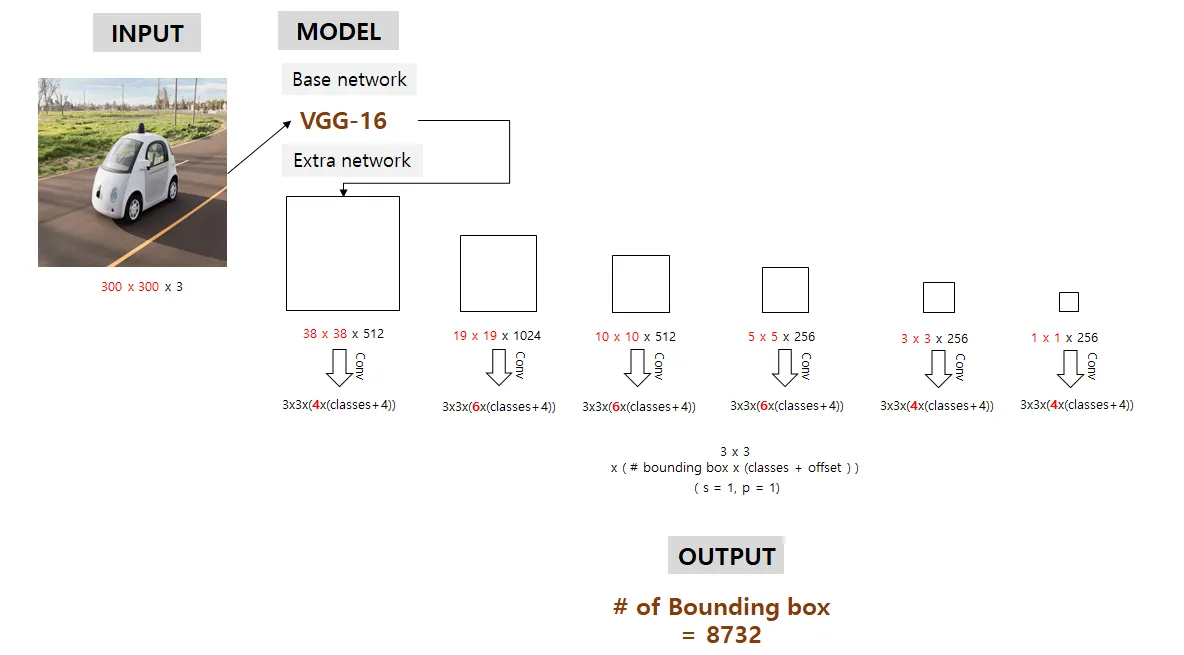
Conv4_3 : 38*38*4 = 5,776
Conv7 : 19*19*6 = 2,166
Conv8_2 : 10*10*6 = 600
Conv9_2 : 5*5*6 = 150
Conv10_2 : 3*3*4 = 36
Conv11_2 : 1*1*4 = 4
# of bounding box = 5,776 + 2,166 + 600 + 150 + 36 + 4 = 8,732
2.1.3 Default boxes and aspect ratios
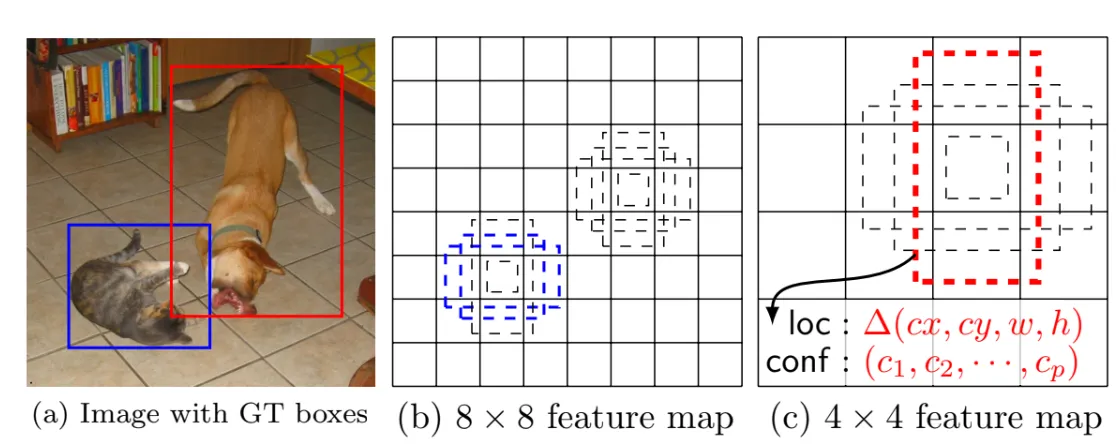
•
각 피처맵의 셀 (8x8인 경우 총 64개의 셀)에서 default bounding box를 만들고 그 default box와 대응되는 자리에서 예측되는 박스의 offset과 per-class scores(박스 안에 물체의 존재 유무)를 예측한다.
•
per-class scores는 확률이 아니라 박스에 사물이 있는지 없는지 나타내는 값
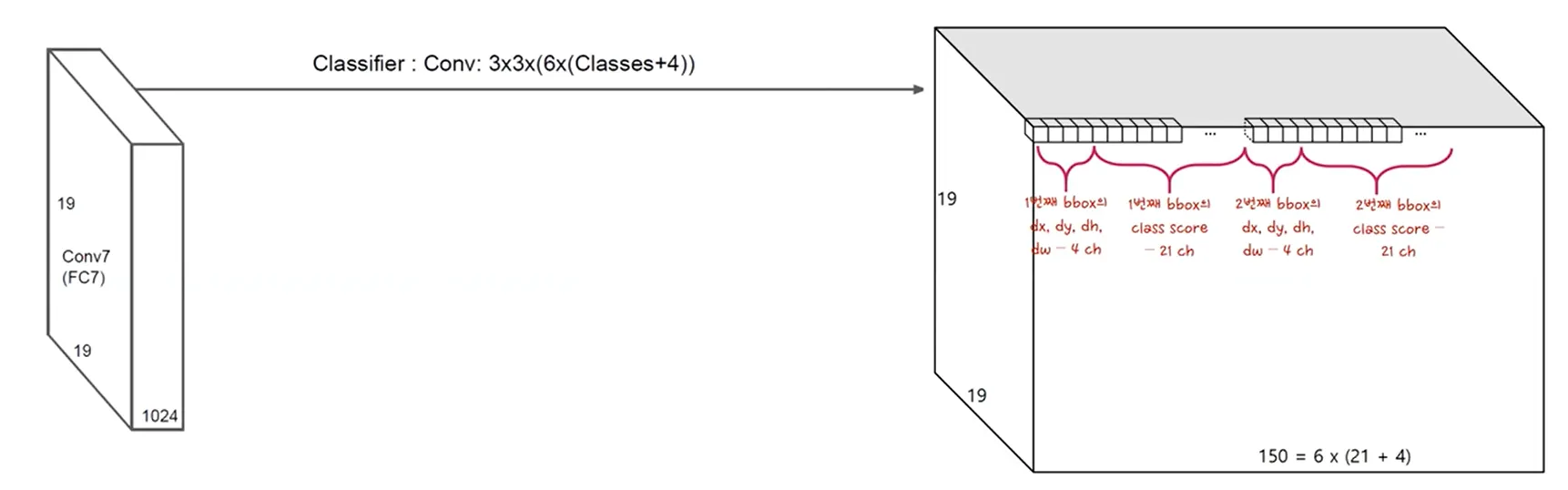
•
# of channels :
* : 4 또는 6
* : # of class score → # of class + 아무것도 바운딩 하지 않는 경우
* 4 : offsets (x, y, w, h)
•
# of feature map :
•
Faster R-CNN의 anchor boxes와 default boxes의 차이?
◦
여러개의 feature map을 사용한다!
◦
however we apply them to several feature maps of different resolutions
2.2 Training
2.2.1 Matching strategy
•
default box와 ground truth을 매칭하여 두 영역의 IoU가 한계점 즉, 0.5이상인 default box를 찾는다.
•
한 셀에서 IoU가 0.5 이상인 default box가 여러 개 나오면 IoU가 가장 큰 default box를 뽑는 것이 아닌 모든 default box를 뽑는다.
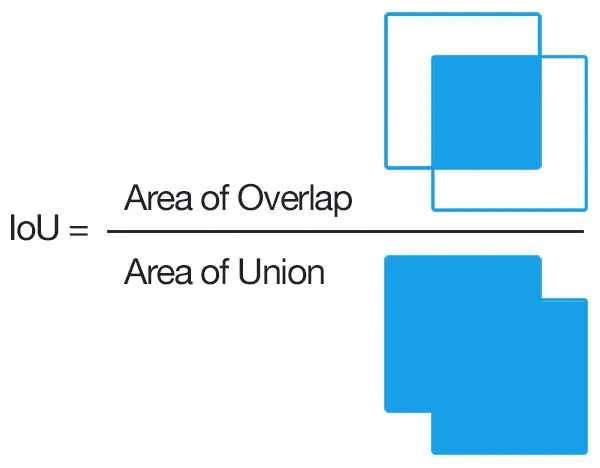
•
object detector가 예측한 바운딩 박스 중에서 정확한 바운딩 박스를 선택하도록 하는 기법

2.2.2 Training objective
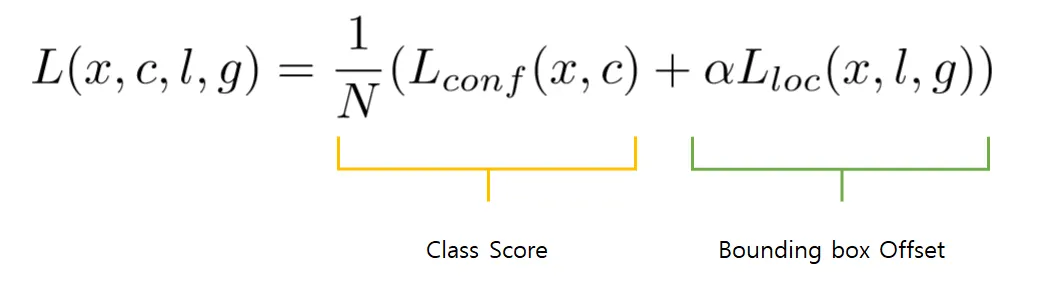
localization loss와 confidence loss의 가중합
: #of matched default boxes (IoU의 0.5 이상)
: predicted box
: ground truth box
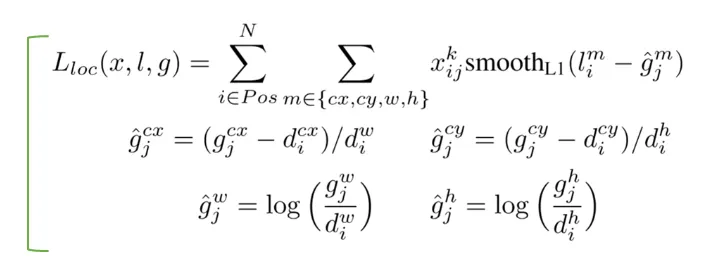
localization loss (loc) → Faster R-CNN와 유사
: default bounding box(의 중심점
: width
: height
: IoU의 결과가 0.5이상인 경우 1, 미만인 경우 0
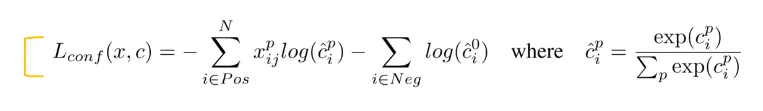
confidence loss (conf)
•
모든 class에 대한 loss를 softmax loss를 통해 계산
2.2.3 Choosing scales and aspect ratios for default boxes
•
각 feature map당 서로 다른 6개의 가 나옴
•
default box의 scale :
<각 feature map의 scale 구하는 공식>
•
= 0.2 , = 0.9
•
: 예측에 사용한 feature map의 수 (SSD의 경우 6개)
◦
첫 번째 feature map (38*38)의 : 0.2, 마지막 feature map (1*1)의 : 0.9
◦
feature map의 scale이 작아질수록 default box의 scale은 커짐
◦
feature map의 크기가 작아질수록 더 큰 객체를 탐지할 수 있음을 의미
•
(aspect ratio) : {}
•
(default box의 width) :
•
(default box의 height) :
2.2.4 Hard negative mining
•
대부분의 default box가 배경이므로 = 0 가 많음
•
positive와 negative가 균형이 맞지 않기 때문에 confidence loss를 높은 순으로 정렬해서 positive : negative 비율을 1 : 3으로 뽑음
⇒ 빠른 최적화와 안정적인 train 가능
2.2.5 Data augmentation
•
전체 input image 사용
•
최소 IOU(0.1, 0.3, 0.5, 0.7, 0.9)
•
Randomly sample a patch