4 Hadoop Ecosystem
4.1 Hadoop 에코시스템의 이해
✓ Hadoop의 코어 프로젝트(Framework)는 HDFS, MapReduce이지만 그 외에도 다양한 서브 프로젝트들이 많음.
✓ Hadoop 에코시스템은 그 Framework를 이루고 있는 다양한 서브 프로젝트들의 모임
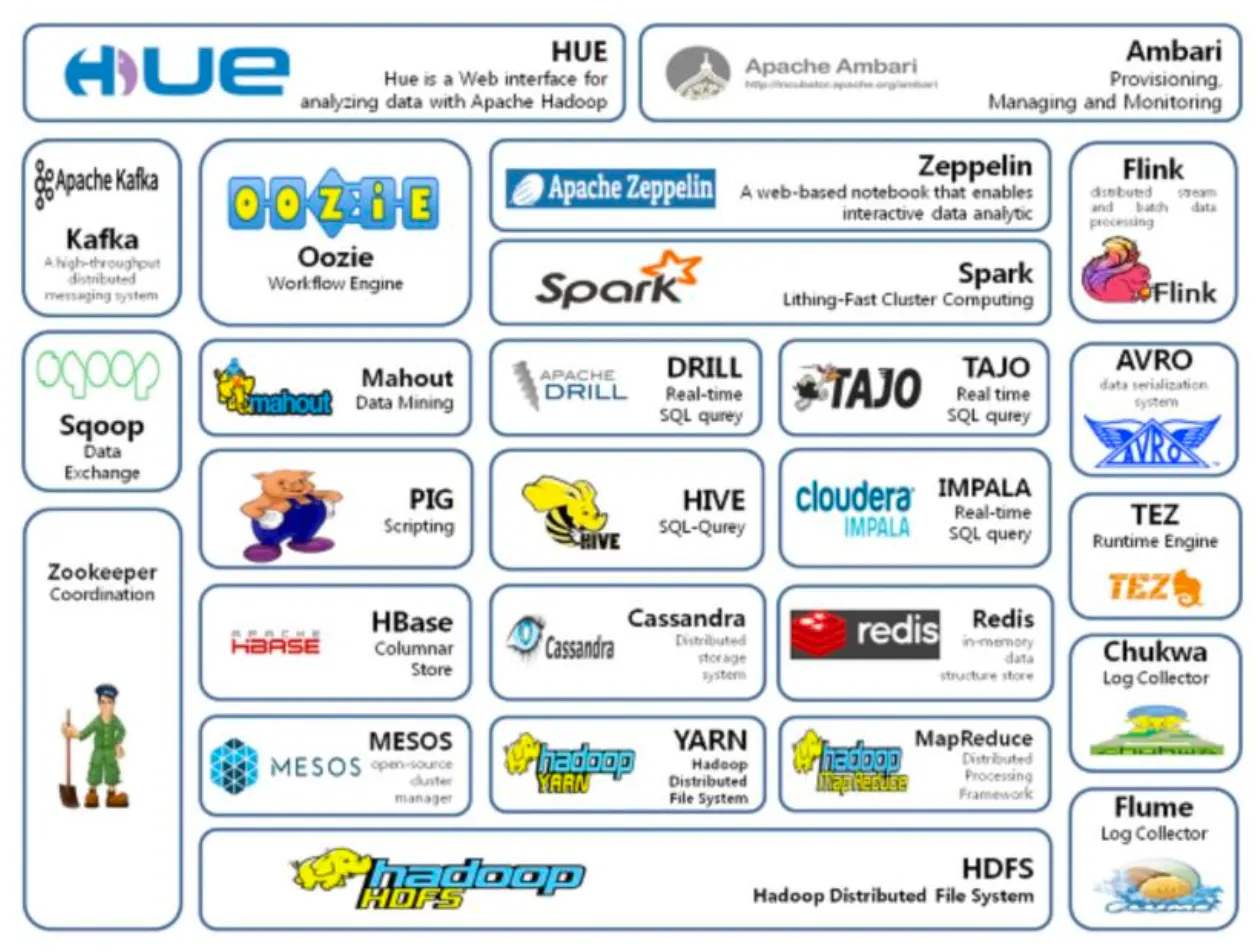
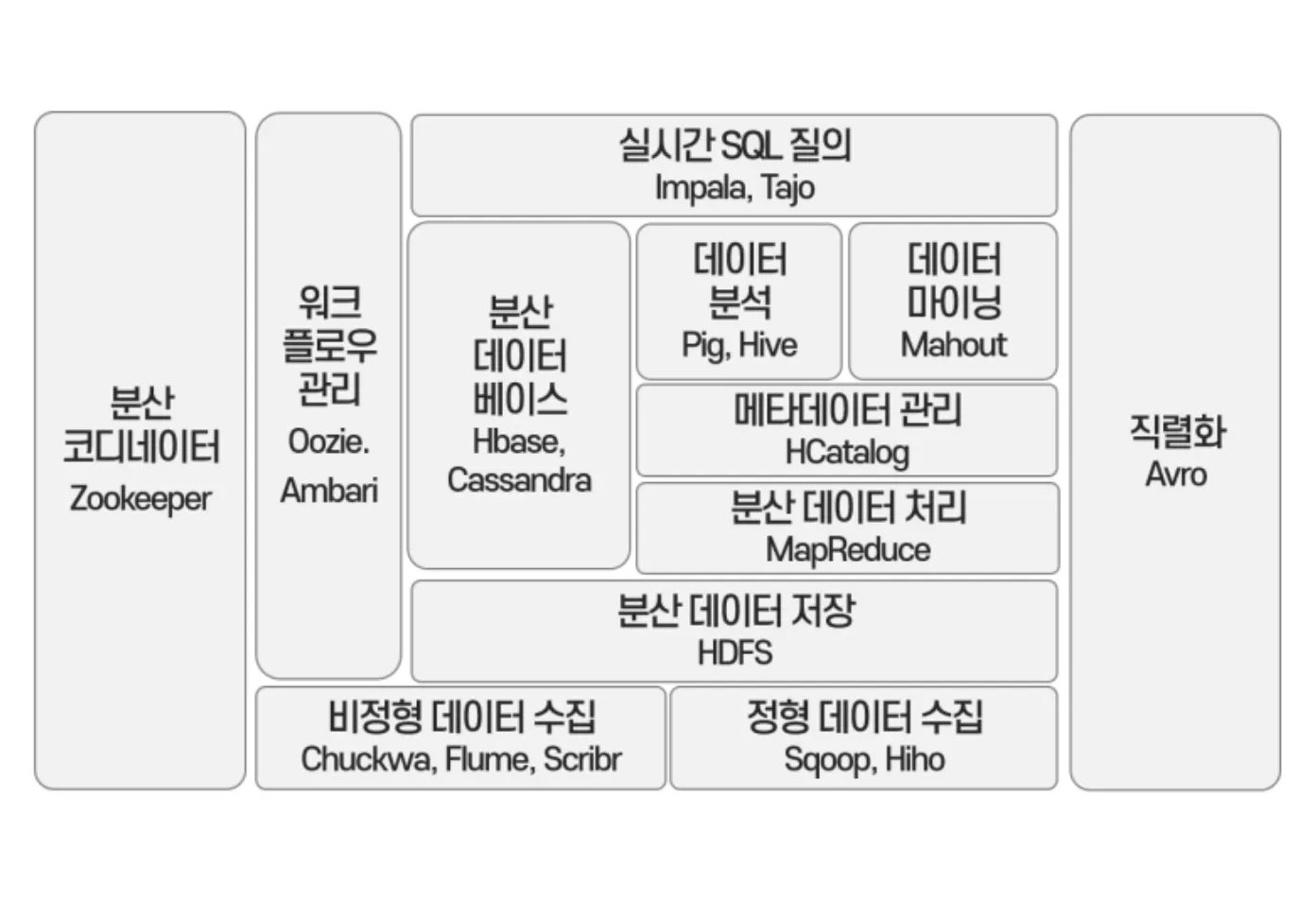
✓ 빅데이터 플랫폼 구축 전반에 있어 Hadoop의 에코시스템의 각 솔루션들이 무료로 기능들을 제공
기능 | 설명 |
수집 | Flume, Chuckwa, Scribr(비정형), Sqoop, Hiho(정형), Kafka(실시간) |
저장 | Hbase, Cassandra |
처리 / 분석 | Hive, Pig, Mahout, Impala, Tajo, Spark, Kafka |
관리 | Zookeeper(분산환경), Hcatalog(메타데이터), Oozie, Airflow, Ambari(워크플로우) |
4.1.1 맵리듀스 (MapReduce)
구글에서 대용량 데이터 처리를 분산 병렬 컴퓨팅에서 처리하기 위한 목적으로 제작
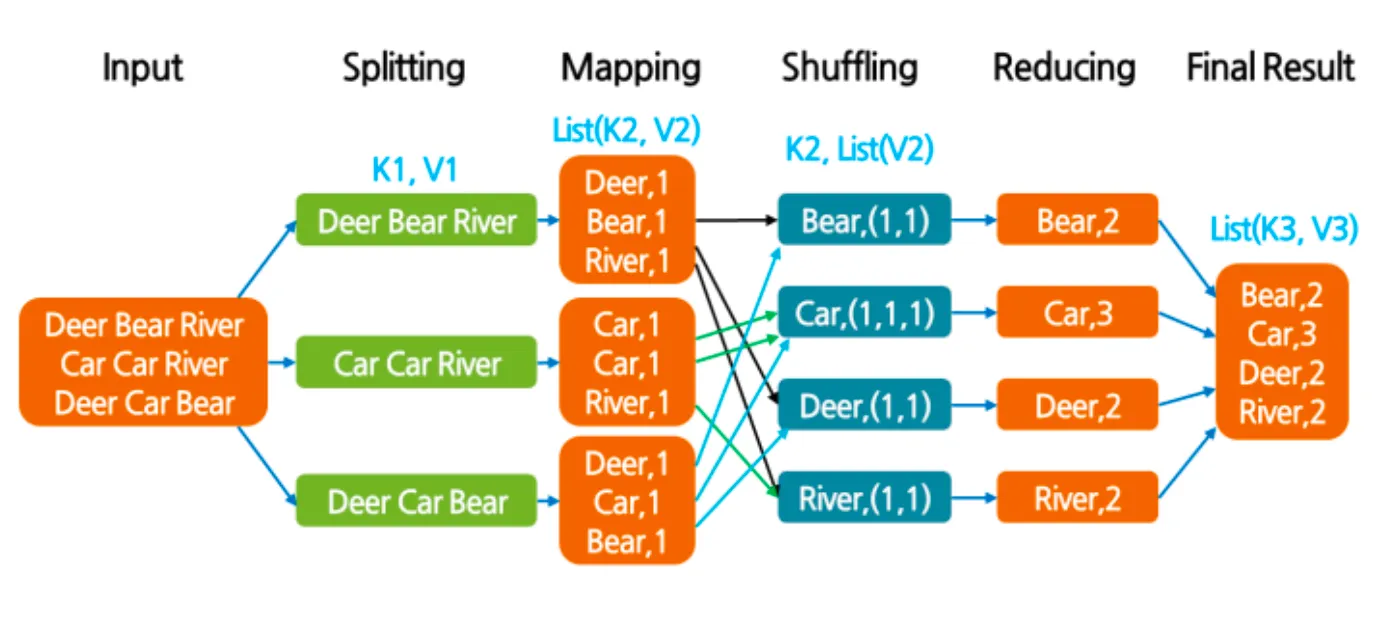
✓ 맵리듀스 프레임 단계
•
맵(Map) 단계: 분산된 데이터를 키(key)와 값(value)의 리스트로 모으는 단계
•
셔플(Shuffle and sort) 단계: 맵 단계에서 나온 중간 경과를 해당 리듀스 함수에 전달하는 단계
•
리듀스(Reduce) 단계: 리스트에서 원하는 데이터를 찾아서 집계하는 단계
✓ 맵리듀스 분산 병렬 처리 방식
1.
시스템(하둡)이 map() 함수들을 데이터에 배포
2.
Map() 함수는 데이터를 읽고 <key, value>를 출력함
3.
시스템(하둡)이 <key, value> 데이터를 그룹핑(shuffle and sort)
4.
시스템(하둡)이 그룹핑된 데이터를 reduce() 함수들에 배포
5.
Reduce() 함수는 <Key, value>를 읽고 결과를 출력
•
Word Count 문제 예시
4.1.2 하이브 (HIVE)
✓ 기존 SQL문법과 상당히 유사한 HiveQL을 사용하여 Hadoop에 저장된 빅데이터를 질의 처리
✓ MapReduce 코드는 작성하기 아주 불편하므로 큰 인기를 끔
✓ 하이브 구성요소
1.
UI
•
사용자가 쿼리 및 기타 작업을 시스템에 제출하는 사용자 인터페이스
•
CLI, Beeline, JDBC 등
2.
Driver
•
쿼리를 입력 받고 작업을 처리
•
사용자 세션을 구현하고, JDBC/ODBC 인터페이스 API 제공
3.
Execution Engine
•
컴파일러에 의해 생성된 실행 계획을 실행
4.
Metastore
•
DB, 테이블, 파티션 정보를 저장
5.
Compiler
•
메타 스토어를 참고하여 쿼리 구문을 분석하고 실행계획을 생성