동시성 제어(Concurrency Control)는 다중 사용자가 동시에 데이터베이스에 접근하고 작업을 수행할 때 데이터의 일관성과 무결성을 유지하기 위한 기법이다.
배타 락 (Exclusive Lock)
데이터를 쓸 때 사용되며, 하나의 트랜잭션만 접근할 수 있다.
보안 및 일관성을 위해 쓰기 제어를 하고 싶음. 내가 그 데이터에 대한 관리자가 되고 싶음. 관리자만이 편집할 수 있게 함.
공유 락 (Shared Lock)
데이터를 읽을 때 사용되며, 여러 트랜잭션이 동시에 읽을 수 있다.
→ 은행에서 내 잔액을 읽을 때, 보고서를 작성할 때 등
따라서 누군가가 그 값을 편집하려 하면 실패함.
배타 락을 획득하려면 해당 값에 공유 락이 획득되어 있어서는 안된다. 그 반대도 마찬가지.
데드 락
두 개 이상의 프로세스나 클라이언트가 서로의 자원을 기다리며(잠금 해제를 기다리며) 무한정 대기하는 상태
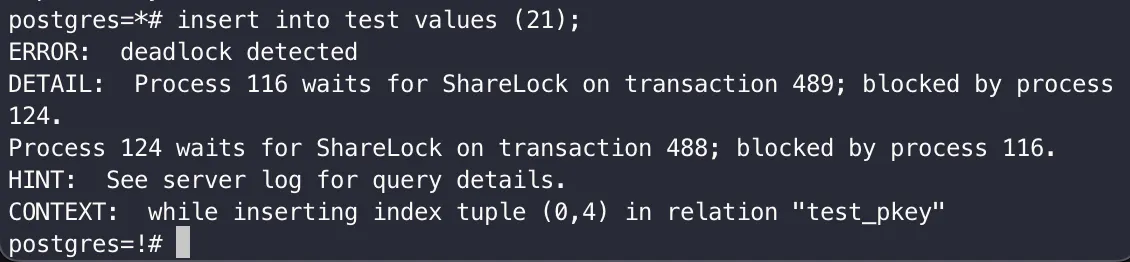
•
rollback한 경우
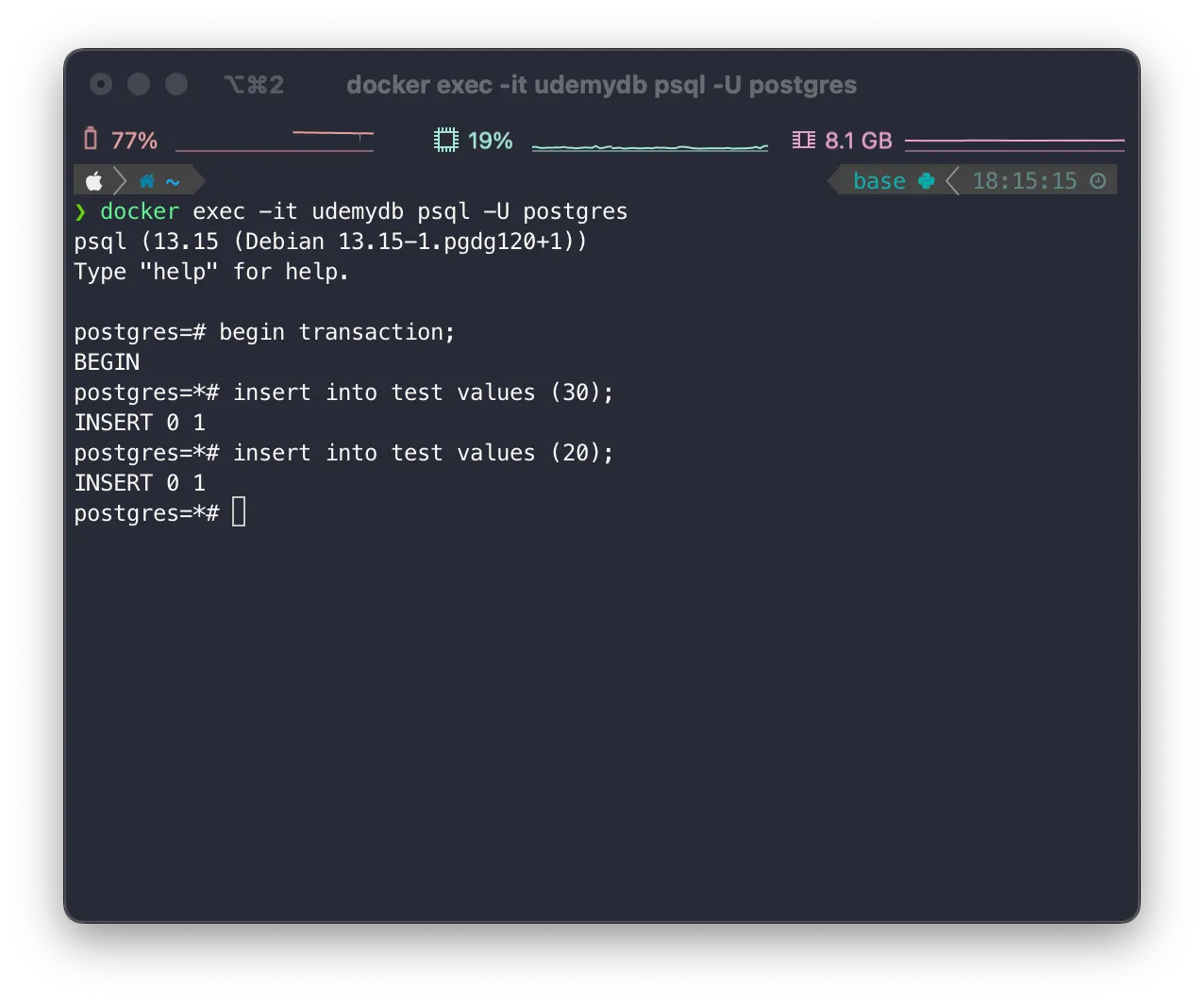
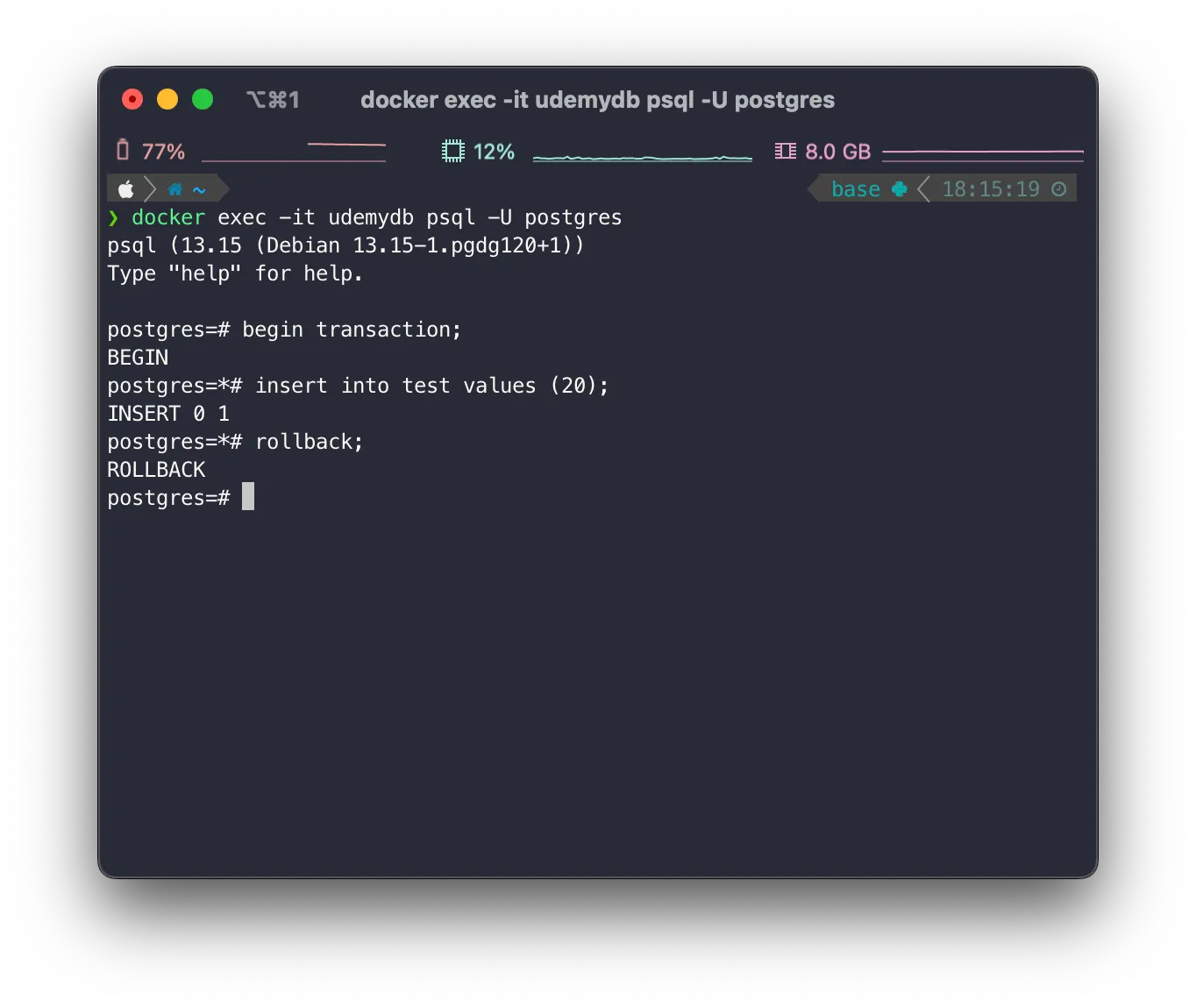
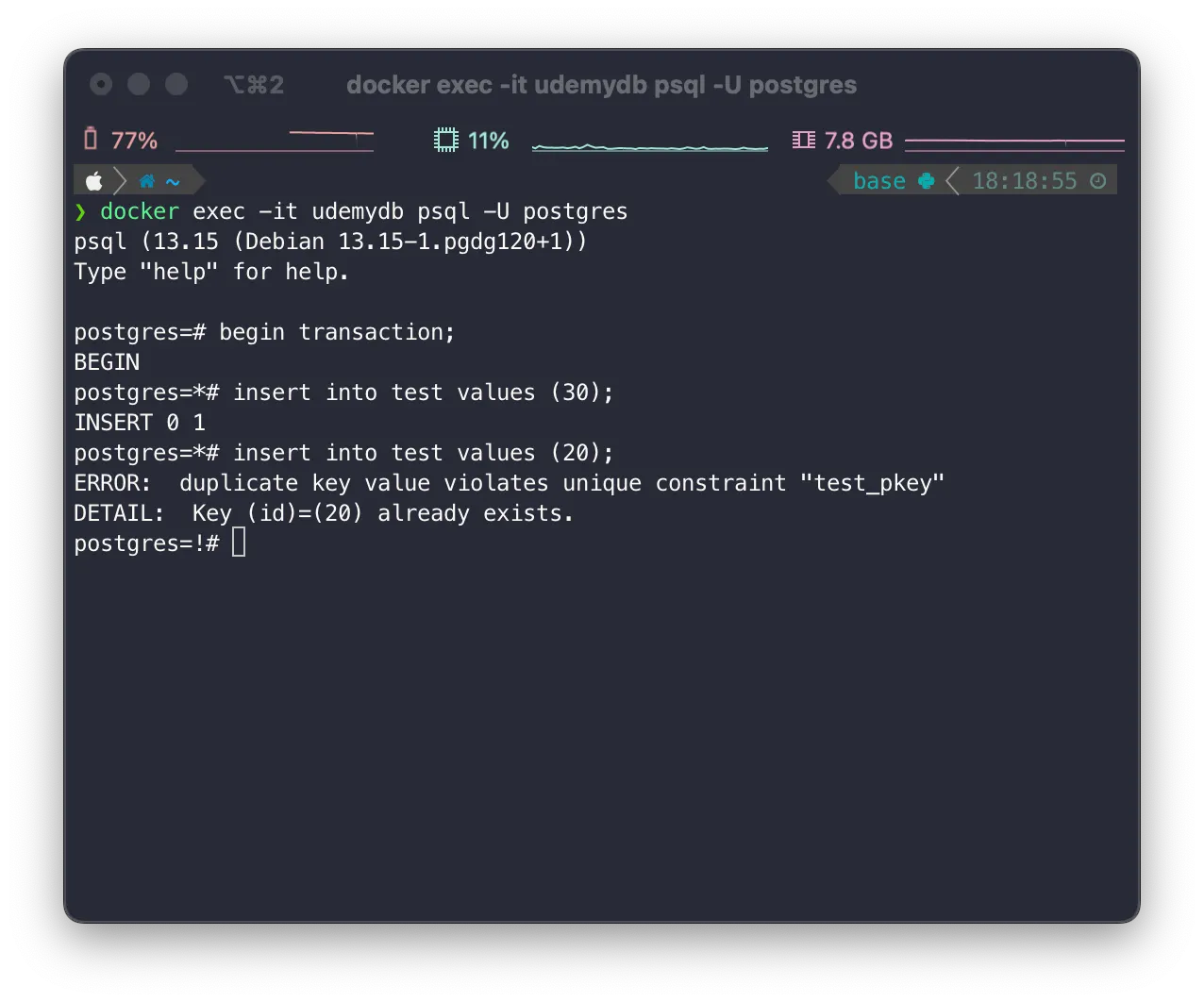
•
commit한 경우
2단계 잠금
ex) 이중 예약
업데이트 하려는 행에 대해 for update 사용해서 배타 락을 얻음. 그렇게 업데이트 후, commit하면 락이 해제됨. 이후 다른 트랜잭션에서 데이터를 읽을 수 있음.
postgres oracle 차이 → oracle은 for update에서 시간 지정을 할 수 있다.
postgres에는 일정 시간이 지나면 명령을 수행하고 데드락을 푸는 방법이 없다.
개발자는 중간에 디버거를 넣지 않고, 대기시간은 유한하다. 밀리초는 매우 짧기 때문에 사용자는 이를 인지하지 못할 것이다…?

Postgres와 MySQL의 힙 값 관리 (레코드 업데이트)
주요 차이점 요약
1.
스토리지 엔진:
•
PostgreSQL: 기본적으로 하나의 스토리지 엔진(MVCC) 사용.
•
MySQL: 여러 스토리지 엔진(InnoDB, MyISAM 등) 지원. InnoDB가 가장 널리 사용됨.
2.
MVCC 구현:
•
PostgreSQL: 힙 파일에 여러 버전의 레코드 저장. VACUUM 프로세스로 dead tuple 정리.
•
MySQL (InnoDB): Undo Log 사용하여 여러 버전의 레코드 관리. 자동 Purge 프로세스.
3.
클러스터드 인덱스:
•
PostgreSQL: 기본적으로 클러스터드 인덱스를 사용하지 않음.
•
MySQL (InnoDB): 클러스터드 인덱스를 사용하여 기본 키 기준으로 데이터 정렬.
4.
데이터 정리:
•
PostgreSQL: VACUUM 명령어를 통해 dead tuple을 명시적으로 정리.
•
MySQL (InnoDB): 자동 Purge 프로세스를 통해 dead tuple을 자동으로 정리.
오프셋 성능 개선
알고리즘을 활용해 id 값 기준으로 정렬(offset을 아예 사용안하는 방식), 인덱스로 페이지네이션하기, 물리적으로 파티셔닝해서 성능 개선 하는 방법도 있다.
연결 풀링
연결 풀링(Connection Pooling)은 데이터베이스 연결을 효율적으로 관리하고 성능을 최적화하기 위해 사용하는 기술이다. 데이터베이스와의 연결을 미리 여러 개 생성해두고, 필요할 때마다 이를 재사용하는 방식.
연결 풀링은 데이터베이스와의 연결 생성 및 해제의 오버헤드를 줄여준다.
매번 연결을 열고 닫는 방식보다 풀링이 훨씬 더 효율적이다. 특히 클라우드를 활용한 원격 DB와 같은 경우 이러한 장점이 더 두드러지게 나타날 수 있다.