2 빅데이터 수집 기술
2.1 데이터 수집기
✓ 많은 경우에는 서버에서 남기는 로그를 수집하게 됨.
•
클라이언트 앱 등에서 로그를 남기는 경우에도 서버에서 수합해서 로그를 남기는 구조
•
웹사이트를 크롤링하는 경우나, 센서 혹은 SNS에서 데이터를 모으는 경우에도 유사한 구조를 가짐
✓ 빅데이터 – 여러 대의 서버 에서 수많은 로그를 남기고 있을 것이고, 이를 효과적으로 수합하여 처리하는 도구들이 필요
✓ 다양한 소스와 출력을 지원하며, 성능과 안정성이 중요
2.1.1 Crawling
자동으로 웹 페이지에 있는 정보를 수집하는 것
1.
Web Crawling
•
웹 상에서 존재하는 데이터를 자동적으로 탐색하는 행위
2.
Web Scraping
•
웹 사이트 상에서 원하는 정보를 추출하는 방법
✓ Python
•
컴퓨터 프로그래밍에 익숙하지 않은 비전공자들도 통계 분야의 종사자들이 쓰기 쉽도록 라이브러리들이 발달되면서 급격히 발전
•
대표적인 크롤링 라이브러리 : Beautifulsoup, Requests 등
2.1.2 Sqoop
✓ 관계형 데이터베이스(RDB)와 분산 파일시스템(HDFS) 사이에 양방향 데이터 전송을 위해 설계된 툴
✓ Hadoop과 관계형 데이터베이스 간에 데이터를 전송할 수 있도록 설계된 도구
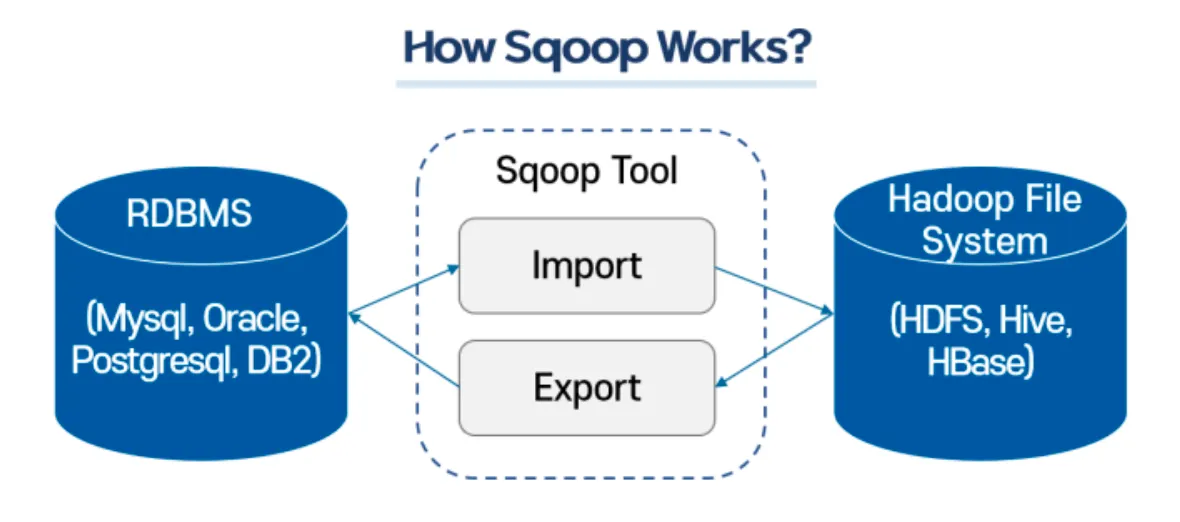
✓ 관계형 데이터베이스에서 읽어온 테이블을 HDFS에서 파일 셋으로 저장
•
병렬처리 방식으로 적재하기 때문에 적재한 후 HDFS에서 여러 개의 파일로 저장
•
스쿱을 사용하여 HDFS에 저장된 파일 셋을 읽고 관계형 데이터베이스로 적재하는 것도 가능
2.1.3 Flume
✓ 서버에서 발생하는 로그를 수집하여 빅데이터 저장도구인 Hadoop에 저장하는 데이터 수집 도구
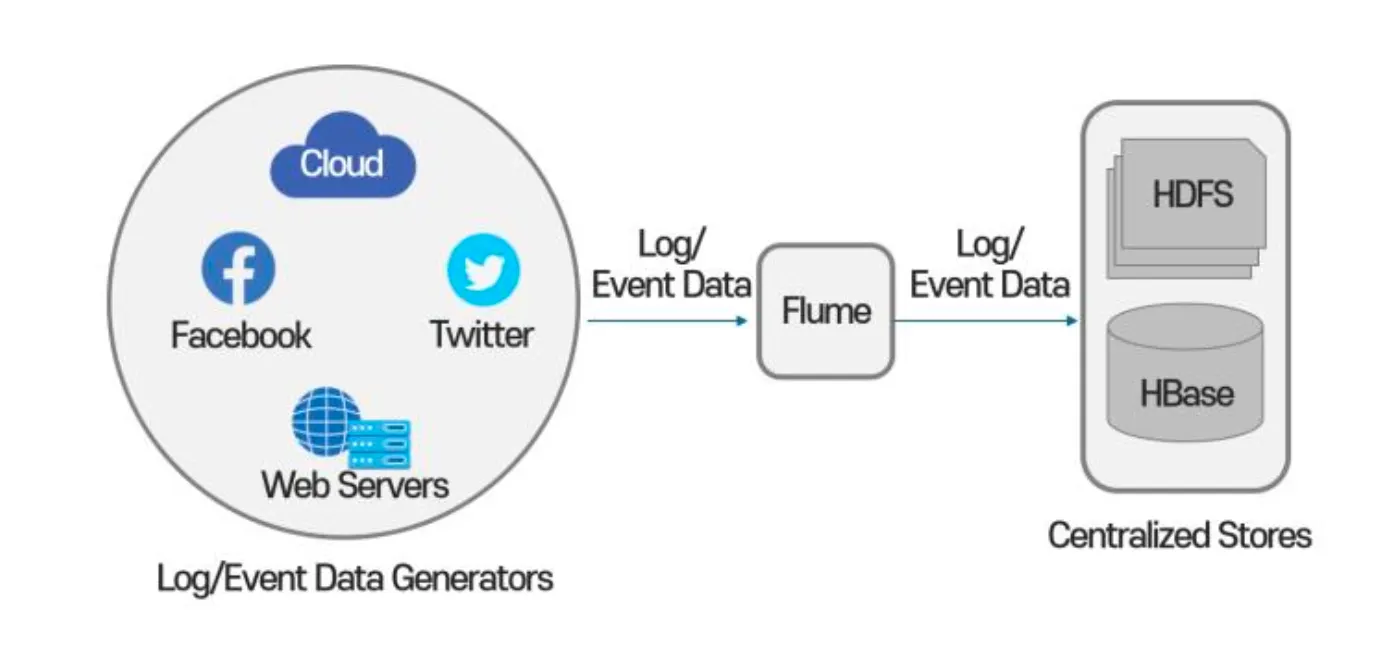
✓ Flume의 각 Agent 단위는 각각의 Source에 맞추어 Channel을 형성하고 쌓은 로그들을 Sink과정을 거쳐 HDFS에 저장함.
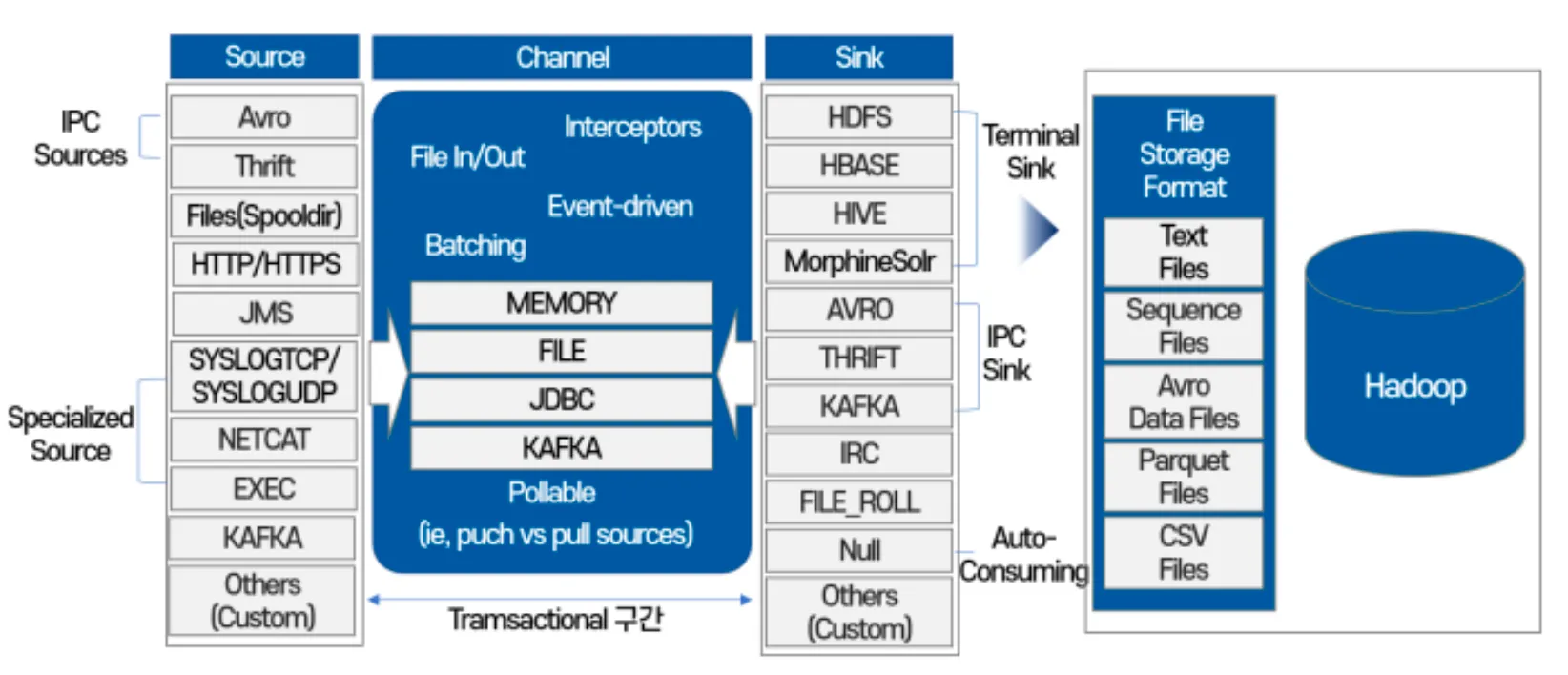
✓ 시스템 신뢰성, 시스템 확장성, 관리 용이성, 성능 확장성을 핵심 목표로 만들어짐.
→ 신뢰성: 장애가 나더라도 로그 유실 없이 전송할 수 있는 능력
✓ 스트림 지향의 데이터 플로우(Data Flow) 기반
→ 데이터 플로우: 하나의 데이터 스트림이 생성지에서 목표지로 전달되어 처리되는 방식
2.1.4 Apache Kafka
✓ 분산 스트리밍 플랫폼이며 데이터 파이프 라인을 만들 때 주로 사용되는 오픈소스 솔루션
✓ 대용량의 실시간 로그처리에 특화되어 있음.
✓ 데이터를 유실없이 안전하게 전달하는 것이 주목적인 메시지 시스템에서 Fault-Tolerant한 안정적인 아키텍처와 빠른 퍼포먼스로 데이터를 처리할 수 있음.
✓ 분산 처리가 가능한 고성능 메시지 큐
✓ Flume은 push 방식, kafka는 pub/sub 방식
✓ 메시지를 디스크에 저장하여 유실없이 처리가 가능하며, 다양한 응용이 가능
✓Flume은 여러가지 collector를 제공하지만 kafka는 메시징 만을 제공하므로 직접 구현해야 함
•
Pub/Sub 모델
◦
카프카는 메시징 서버로 동작
◦
메시징 시스템이란 메시지라고 불리는 데이터 단위를 publisher 또는 producer가 카프카에 토픽이라는 각각의 메시지 저장소에 데이터를 저장하면
subscriber 또는 consumer가 원하는 토픽에서 데이터를 가져가는 형식을 말하며, 이 처럼 메시징 시스템 서버를 두고 메시지를 보내고 받는 통신을 Pub/Sub 모델이라고 함.
◦
Pub/Sub 모델은 비동기 메시징 전송 방식으로 발신자의 메시지에는 수신자가 정해져 있지 않은 상태로 발행함.
◦
이처럼 수신자는 발신자 정보가 없어도 원하는 메시지만 수신할 수 있으며 이런 구조로 인하여 높은 확장성을 확보할 수 있음.
•
Kafka의 특징
◦
Pub/sub 모델: publisher/subscriber 모델은 데이터 큐를 중간에 두고 서로 간 독립적으로 데이터를 생산하고 소비함. 이런 느슨한 결합을 통해서 어느 하나가 다운 되더라도 서로 간에 의존성이 없기 때문에 안정적임.
◦
고가용성 및 확장성: 카프카는 클러스터로 작동하여 fault-tolerant한 고가용성 서비스를 제공함. 그리고 서버를 수평적으로 늘려 안정성 및 성능을 향상시키는 스케일 아웃이 가능.
◦
분산 처리: 파티션이란 개념을 도입하여 여러 개의 파티션을 서버들에게 분산시켜 나누어 처리하여 메시지를 상황에 맞춰 빠르게 처리가 가능.
◦
디스크 순차 저장 및 처리: 메시지를 메모리 큐에 적재하는 기존 시스템과 다르게, 카프카는 메시지를 디스크에 순차적으로 저장하여 서버에 장애가 나더라도 메시지가 디스크에 저장되어 있어 유실 걱정이 없고, 순차적으로 저장되므로 디스크 I/O가 줄어들어 성능이 빨라짐.
2.1.5 오픈 API
✓ 누구나 사용할 수 있도록 공개된 API
✓ 주로 REST 방식으로 제공
✓ JSON, XML 형식의 결과
•
API의 특징
◦
응용프로그램 프로그래밍 인터페이스
◦
응용 프로그램에서 사용할 수 있도록 운영체제나 프로그래밍 언어가 제공하는 기능을 제어할 수 있게 만든 인터페이스
◦
이종 시스템 간에 응용 프로그래밍이 가능하도록 정의된 명세
2.2 데이터 저장소
✓ 데이터의 흐름은 수집 → 저장이지만, 저장소가 없다면 수집기의 동작을 제대로 확인할 수가 없기 때문에 저장소 준비가 우선임
•
Hadoop HDFS 사용
•
HDFS의 대안은 많지 않음. MapR File System 정도가 (유료) 있음
✓ 데이터를 파일로 그대로 저장하는 방법
•
HBase 등의 분산 데이터베이스들
•
고전적인 RDBMS와 분산 데이터베이스를 혼용하기도 함
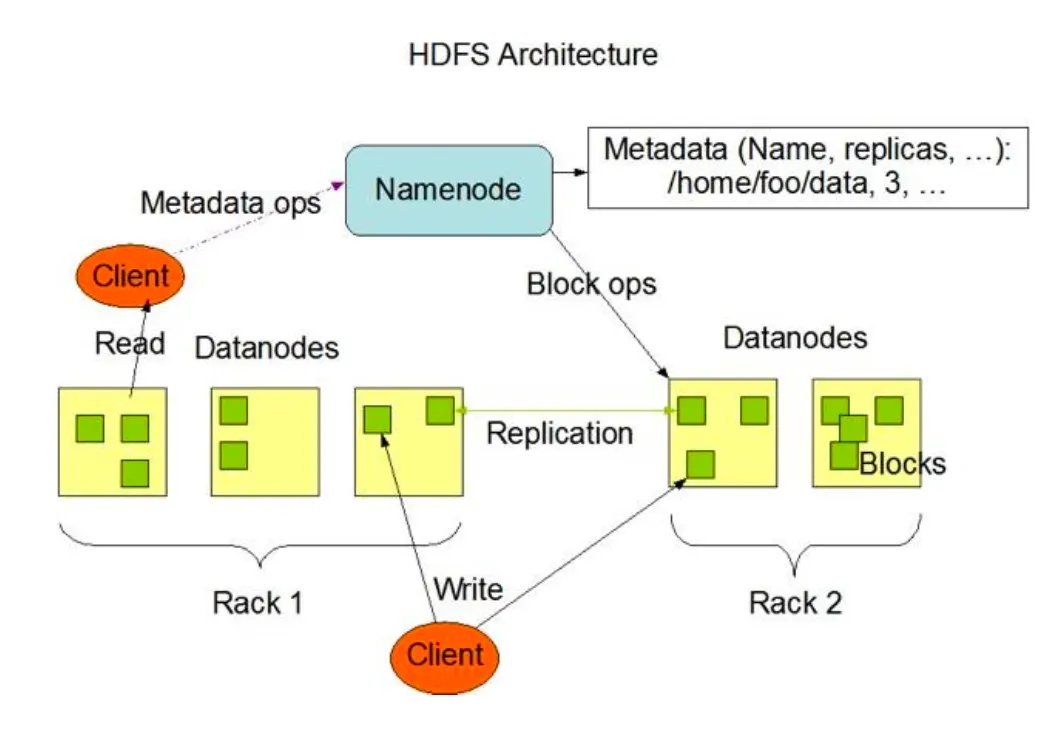
2.2.1 HDFS(Hadoop Distributed File System)
✓ 구글의 GFS논문의 오픈소스 구현체
✓ 대용량 파일 읽기 및 쓰기 작업에 최적화된 특별한 파일 시스템
✓ 로컬 파일 시스템과 HDFS는 분리되어 있음
✓ 사용자는 필요한 파일을 로컬 파일 시스템에서 HDFS로 내보냄
✓ HDFS에서 로컬 파일 시스템으로 가져와서 작업해야 함
✓ HDFS에 파일을 저장하면 파일 데이터를 슬라이스로 분할하여 하둡 클러스터의 여러 노드에 이중으로 저장함
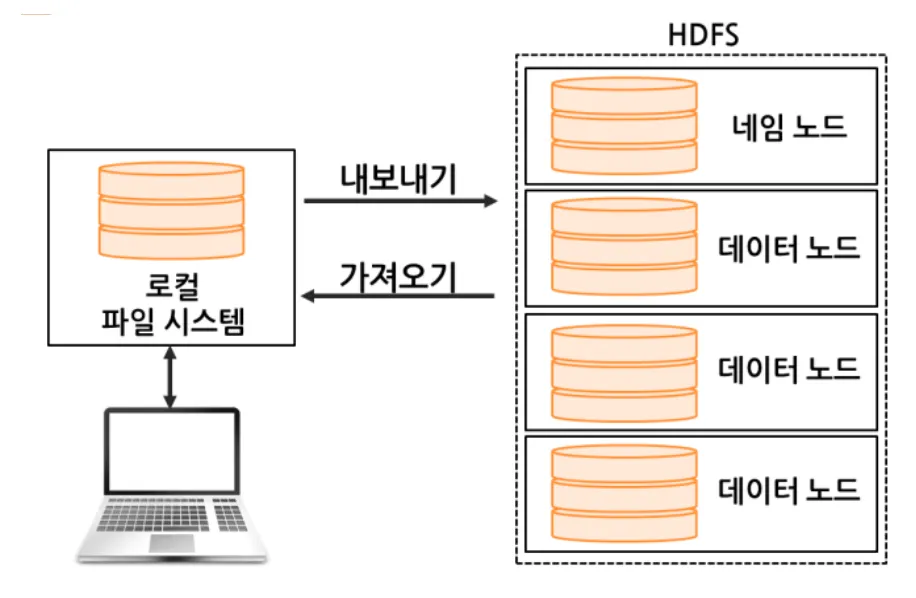
✓ 파일을 기본적으로 64MB 혹은 128MB 블록 단위로 나누어 여러 개의 데이터 노드에 분산 저장함.
✓ 복제본 의 수는 시스템에서 설정할 수 있음(디폴드:3)
✓ 파일의 메타정보는 마스터 노드의 네임 노드가 관리하고 실제 블록 데이터는 작업 노드인 데이터 노드에 분산 저장됨
✓ 자체적으로 중복 저장과 장애복구 기능을 가지고 있기에, 값비싼 서버용 장비가 아닌 PC급 장비를 활용하여 비용을 낮출 수 있음
✓ 다양한 접근 옵션을 제공.
2.2.2 NoSQL
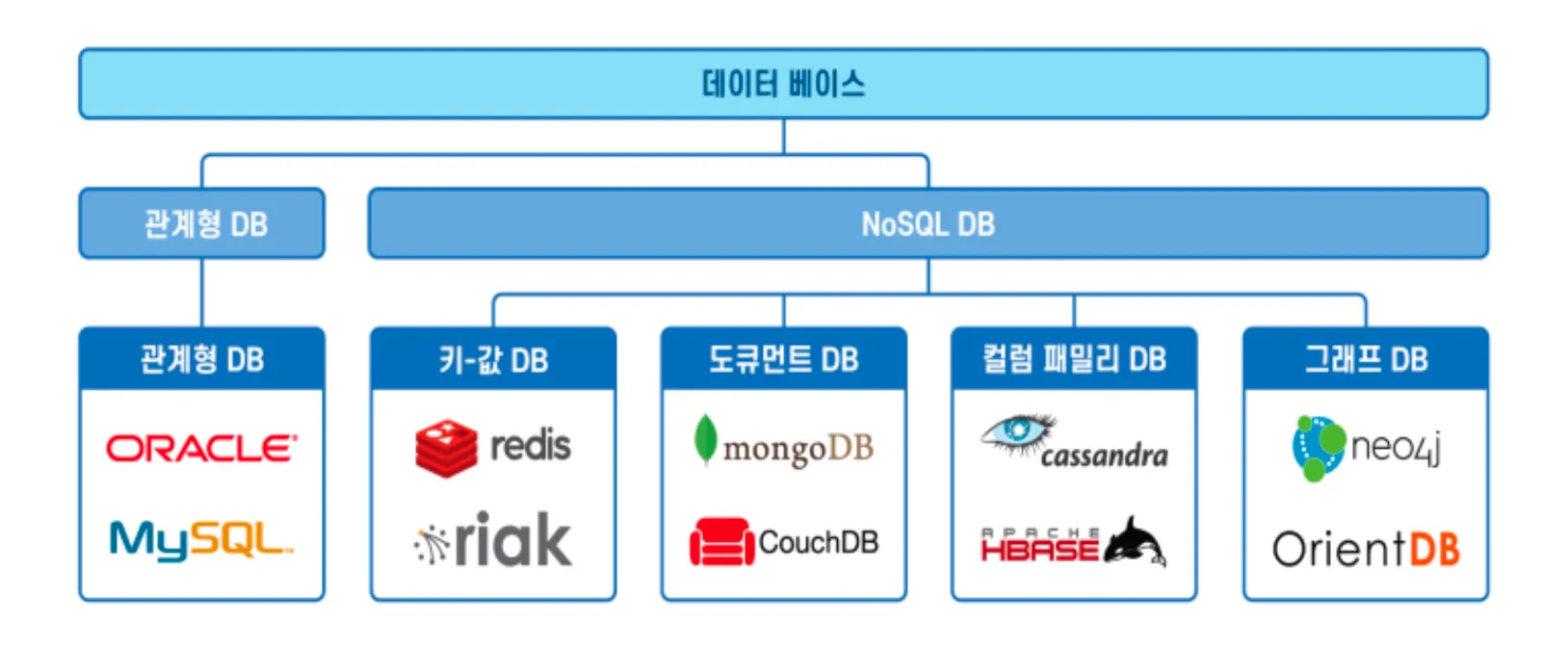
✓ 비관계형 데이터베이스를 지칭
•
관계형 데이터 모델을 지양하며 대량의 분산된 데이터를 저장하고 조회하는데 특화되었으며 스키마 없이 사용 가능하거나 느슨한 스키마를 제공하는 저장소
•
기존 RDBMS 형태의 관계형 데이터베이스가 아닌 다른 형태의 데이터 저장 기술을 의미하며, 관계형 데이터베이스의 한계를 극복하기 위한 데이터 저장소의 새로운 형태
•
시작은 1998년 카를로 스트로찌(Carlo Strozzi)라는 엔지니어가 표준 SQL을 채용하지 않은 자신만의 경량 Open Source 데이터베이스를 NoSQL 이라고 부르는데서 유래
✓ 비관계형 데이터 저장소에서 비정형 데이터를 저장하는 시스템으로 초대량의 데이터를 빠르게 처리하는 것이 필수적인 업무에 선택적으로 사용됨
→ (기사 원문 수집, Push 메시지 발송, AB테스트, 백엔드 데이터 저장 등)
✓ 전통적인 관계형 데이터베이스보다 덜 제한적인 일관성 모델을 이용하는 데이터의 저장 및 검색을 위한 매커니즘을 제공
✓ 단순 검색 및 추가 작업을 위한 최적화된 키, 값 저장 공간
✓ 빅데이터 실시간 웹 애플리케이션의 상업적 이용에 널리 이용
✓ 관계형 데이터베이스에서 사용해오던 관계형 데이터 모델이 아닌 키-값 데이터 모델, 컬럼 기반 데이터 모델, 문서 기반 데이터 모델, 그래프 기반 데이터 모델 등을 사용
✓ 관계형 데이터베이스보다 유연하고 빠른 데이터 처리가 가능
✓ 데이터 모델 지원
2.2.3 Apache Hbase
✓ 구글의 BigTable 논문을 구현한 Hbase 등장
✓ HDFS 위에서 동작하며 MapReduce에서 사용할 수 있는 입출력 제공(하둡 생태계)
✓ 기존의 데이터베이스 대비 기능이 제한적이지만, 클러스터에 컴퓨터를 여러 대 붙이면 성능이 계속 올라감
✓ 페이스북 메신저, 비트윈 메신저 등 고성능 데이터베이스가 필요한 경우에 사용