목차
1. 데이터 설명 및 보기
1-1. 데이터 불러오기
•
변수 정보
1.
id : unique identifier # 고유 id
2.
gender : 'Male', 'Female' or 'Other'
3.
age : 환자의 나이
4.
hypertension : 0은 고혈압 없음, 1은 고혈압 있음
5.
heart_disease : 0은 심장병 없음, 1은 심장병 있음
6.
ever_married : 'NO' or 'Yes' # 결혼 여부
7.
work_type : 'children', 'Govt_job', 'Never_worked', 'Private' or 'Self-employed' # 직업 종류 (어린이, 공무원, 무직, 비밀, 자영업)
8.
Residence_type : 'Rural' or 'Urban' # 주거 형식 (시골 or 도시)
9.
avg_glucose_level : average glucose level in blood # 글루코스 평균치
10.
bmi : body mass index # 체질량 지수
11.
smoking_status : 'formerly smoked', 'never smoked', 'smokes' or 'Unknown' # 흡연 여부 (이전에 흡연, 흡연한 적 없음, 흡연자, 모름)
12.
stroke : 0은 뇌졸중 없음, 1은 뇌졸중 있음
import pandas as pd
import matplotlib as mpl
import matplotlib.pylab as plt
import seaborn as sns
import numpy as npm
file_path = 'Stroke_Prediction/stroke_prediction_data.csv'
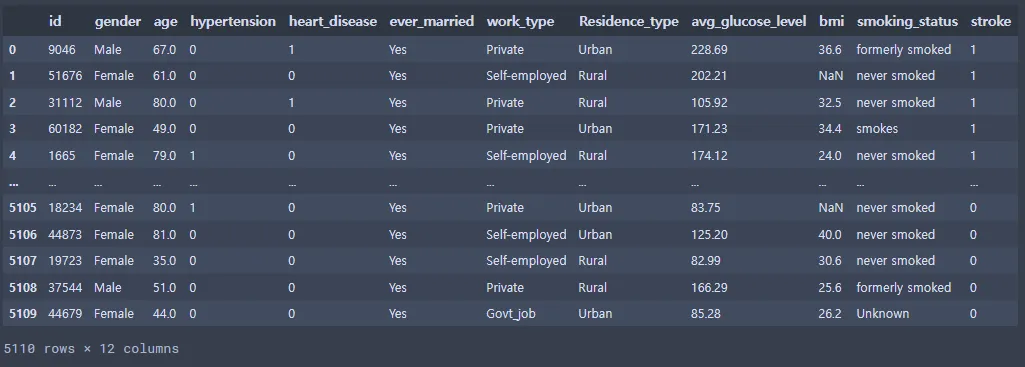
st_data = pd.read_csv(file_path)
st_data
Python
복사
1-2. 데이터 백업
st_data_copy_backup = st_data.copy()
st_data.to_csv('Stroke_Prediction/stroke_prediction_backup.csv')
file_path = 'Stroke_Prediction/stroke_prediction_backup.csv'
st_data_csv_backup = pd.read_csv(file_path)
st_data_csv_backup.drop(['Unnamed: 0'], axis = 1, inplace = True)
st_data_csv_backup
Python
복사
st_data.info()
Python
복사
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 5110 entries, 0 to 5109
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 5110 non-null int64
1 gender 5110 non-null object
2 age 5110 non-null float64
3 hypertension 5110 non-null int64
4 heart_disease 5110 non-null int64
5 ever_married 5110 non-null object
6 work_type 5110 non-null object
7 Residence_type 5110 non-null object
8 avg_glucose_level 5110 non-null float64
9 bmi 4909 non-null float64
10 smoking_status 5110 non-null object
11 stroke 5110 non-null int64
dtypes: float64(3), int64(4), object(5)
memory usage: 479.2+ KB
Plain Text
복사
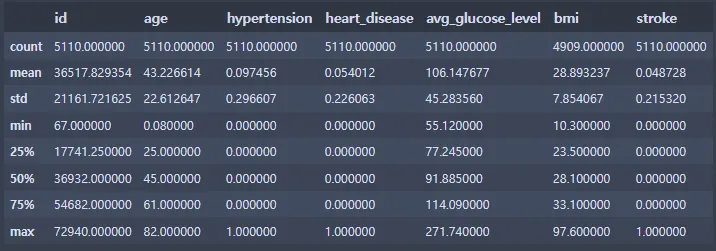
st_data.describe()
Python
복사
2. 데이터 기초 분석 및 탐색
2-1. 데이터 재구조화
gender의 male, female → 0, 1
gender_dict = {'Male':0, 'Female':1}
st_data['gender'] = st_data['gender'].map(gender_dict)
Python
복사
2-2. ever_married 그룹 분석
st_data.groupby(['ever_married']).mean()
Python
복사

ever_married의 No, Yes → 0, 1
married_dict = {'No':0, 'Yes':1}
st_data['ever_married'] = st_data['ever_married'].map(married_dict)
Python
복사
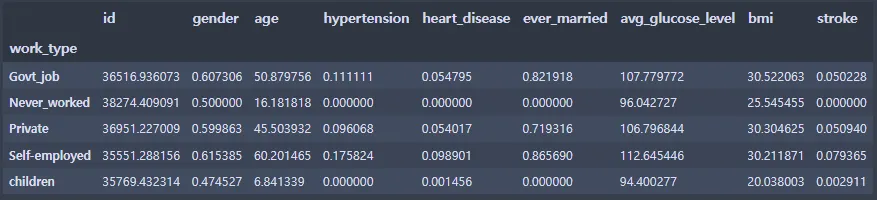
2-3. work_type 그룹 분석
st_data.groupby(['work_type']).mean()
Python
복사
work_type의 Private, Self-employed, Govt_job, Never_worked, children → 0, 1, 2, 3, 4
work_dict = {'Private':0, 'Self-employed':1, 'Govt_job':2, 'Never_worked':3, 'children':4}
st_data['work_type'] = st_data['work_type'].map(work_dict)
Python
복사
2-4. Residence_type 그룹 분석
st_data.groupby(['Residence_type']).mean()
Python
복사

Residence_type의 Rural, Urban → 0, 1
residence_dict = {'Rural':0, 'Urban':1}
st_data['Residence_type'] = st_data['Residence_type'].map(residence_dict)
Python
복사
2-5. smoking_status 그룹 분석
st_data.groupby(['smoking_status']).mean()
Python
복사

smoking_status의 Unknown, never smoked, formerly smoked, smokes → 0, 1, 2, 3
smoking_dict = {'Unknown':0, 'never smoked':1, 'formerly smoked':2, 'smokes':3}
st_data['smoking_status'] = st_data['smoking_status'].map(smoking_dict)
Python
복사
st_data
Python
복사
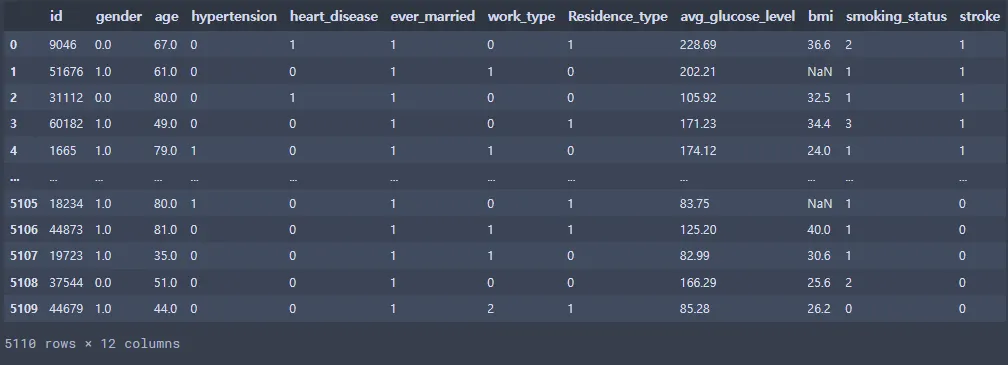
결측치 때문에 소수점이 생김
st_data.info()
Python
복사
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 5110 entries, 0 to 5109
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 5110 non-null int64
1 gender 5109 non-null float64
2 age 5110 non-null float64
3 hypertension 5110 non-null int64
4 heart_disease 5110 non-null int64
5 ever_married 5110 non-null int64
6 work_type 5110 non-null int64
7 Residence_type 5110 non-null int64
8 avg_glucose_level 5110 non-null float64
9 bmi 4909 non-null float64
10 smoking_status 5110 non-null int64
11 stroke 5110 non-null int64
dtypes: float64(4), int64(8)
memory usage: 479.2 KB
Plain Text
복사
3. 데이터 클린징
3-1. 결측치 확인
import missingno as msno
st_data.isnull().sum()
Python
복사
id 0
gender 1
age 0
hypertension 0
heart_disease 0
ever_married 0
work_type 0
Residence_type 0
avg_glucose_level 0
bmi 201
smoking_status 0
stroke 0
dtype: int64
Plain Text
복사
gender에 결측치 1개????????????????????? → 아마 Other 데이터가 아닐까 생각함
msno.matrix(st_data)
Python
복사
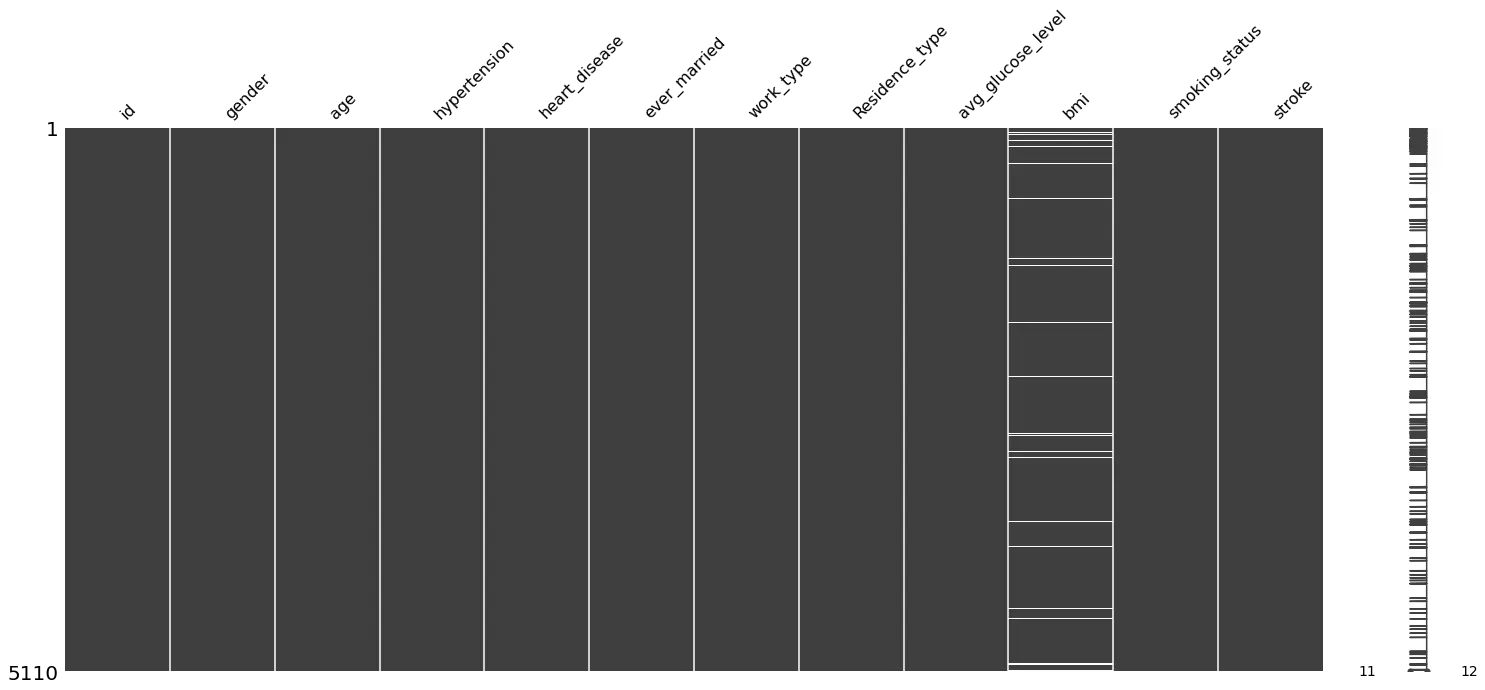
gender는 평균을 내면 안되기 때문에 삭제하고.. bmi의 결측치는 변수별 평균으로 대체하는 방법을 사용
st_data2 = st_data.fillna({'bmi':st_data['bmi'].mean()}, inplace=True) # bmi열의 결측치를 평균으로 대체
st_data2 = st_data.dropna(axis=0) # 남은 결측값은 삭제측값은 삭제
Python
복사
st_data2.isnull().sum()
Python
복사
id 0
gender 0
age 0
hypertension 0
heart_disease 0
ever_married 0
work_type 0
Residence_type 0
avg_glucose_level 0
bmi 0
smoking_status 0
stroke 0
dtype: int64
Plain Text
복사
데이터가 5109개로 줄어든 것 확인
3-2. 정수형 변환
st_data2.info()
Python
복사
<class 'pandas.core.frame.DataFrame'>
Int64Index: 5109 entries, 0 to 5109
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 5109 non-null int64
1 gender 5109 non-null float64
2 age 5109 non-null float64
3 hypertension 5109 non-null int64
4 heart_disease 5109 non-null int64
5 ever_married 5109 non-null int64
6 work_type 5109 non-null int64
7 Residence_type 5109 non-null int64
8 avg_glucose_level 5109 non-null float64
9 bmi 5109 non-null float64
10 smoking_status 5109 non-null int64
11 stroke 5109 non-null int64
dtypes: float64(4), int64(8)
memory usage: 518.9 KB
Plain Text
복사
st_data2['gender'] = st_data2['gender'].astype(np.int64)
st_data2['age'] = st_data2['age'].astype(np.int64)
Python
복사
st_data2.info()
Python
복사
<class 'pandas.core.frame.DataFrame'>
Int64Index: 5109 entries, 0 to 5109
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 5109 non-null int64
1 gender 5109 non-null int64
2 age 5109 non-null int64
3 hypertension 5109 non-null int64
4 heart_disease 5109 non-null int64
5 ever_married 5109 non-null int64
6 work_type 5109 non-null int64
7 Residence_type 5109 non-null int64
8 avg_glucose_level 5109 non-null float64
9 bmi 5109 non-null float64
10 smoking_status 5109 non-null int64
11 stroke 5109 non-null int64
dtypes: float64(2), int64(10)
memory usage: 518.9 KB
Plain Text
복사
st_data2
Python
복사
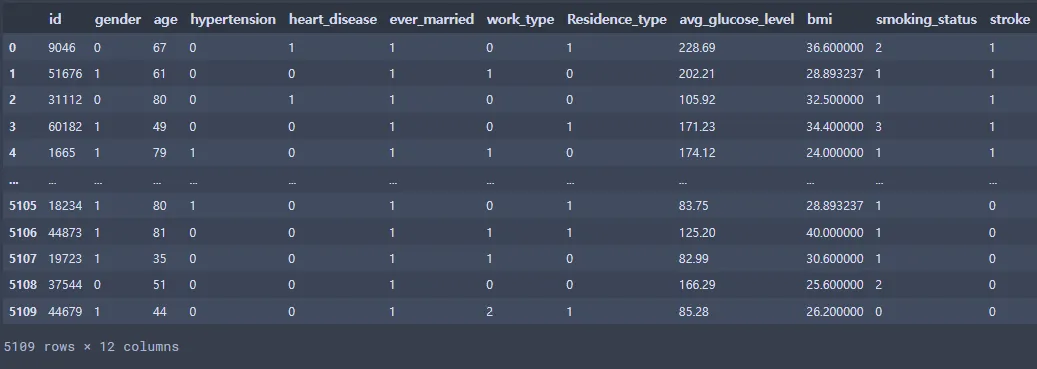
3-3. 이상치 확인
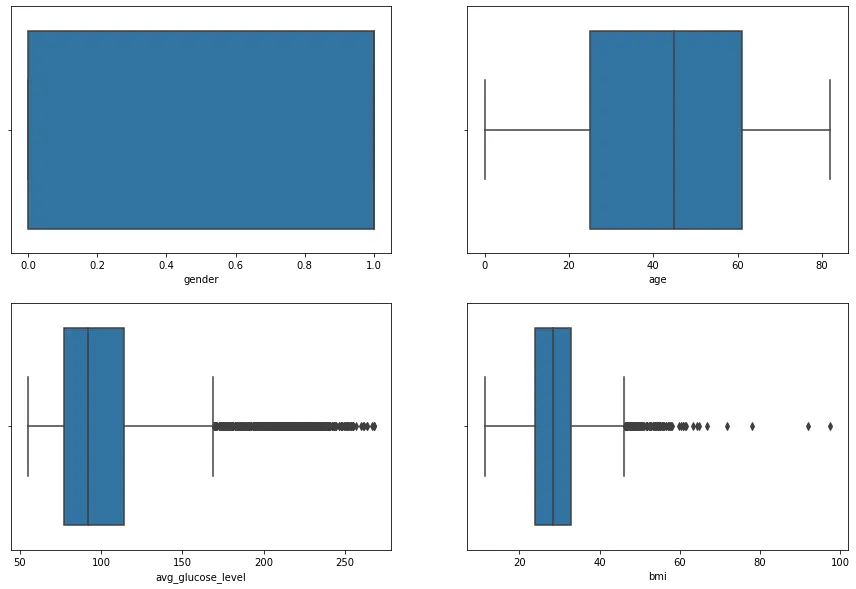
figure, ((ax1, ax2), (ax3, ax4)) = plt.subplots(nrows=2, ncols=2) #표를 넣을 4칸 생성
figure.set_size_inches(15, 10) # 각 표의 사이즈 정하기
sns.boxplot(x = "gender", data = st_data2, ax=ax1)
sns.boxplot(x = "age", data = st_data2, ax=ax2)
sns.boxplot(x = "avg_glucose_level", data = st_data2, ax=ax3)
sns.boxplot(x = "bmi", data = st_data2, ax=ax4)
Python
복사
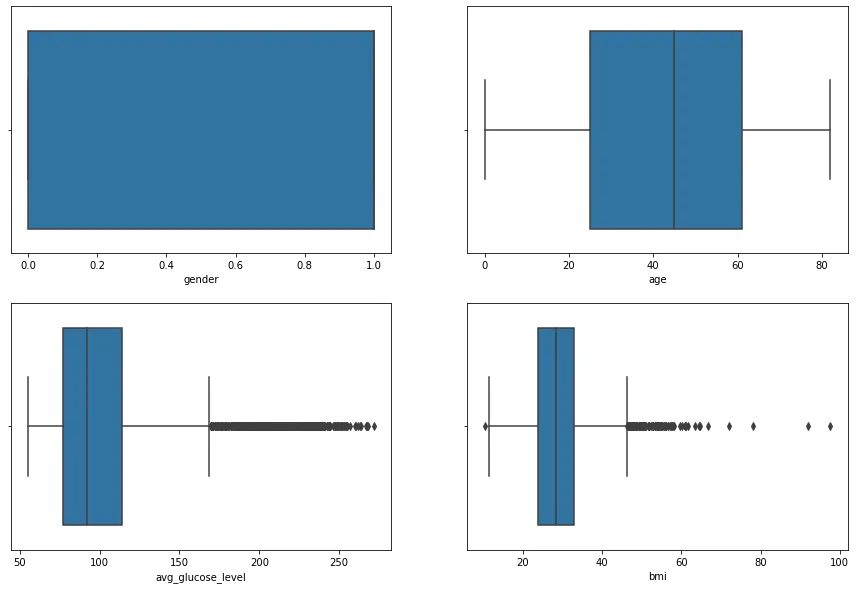
당뇨병은 우리 몸의 췌장에서 분비되는 인슐린이라고 하는 호르몬이 부족해서 혈당(혈액 안의 당분)이 높아지는 병입니다. 당뇨병은 동맥경화의 원인이 되며, 따라서 뇌졸중의 중요한 위험인자가 됩니다. 당뇨병 환자는 정상인보다 2-3배 정도 뇌졸중에 잘 걸린다는 보고가 있습니다. (서울아산병원 뇌졸중센터)
→ 평균 혈당(glucose)수치가 높을수록 뇌졸중에 잘 걸린다는 뜻!
avg_glucose_level이 270 이상인 이상치 제거 (별로 제거할 필요 없어보이긴 함)
bmi의 최소값 아웃라이어에 이상치 보이므로 제거
st_data3 = st_data2[(st_data2["avg_glucose_level"]<270) & (st_data2["bmi"]>st_data2["bmi"].min())]
st_data3
Python
복사
figure, ((ax1, ax2), (ax3, ax4)) = plt.subplots(nrows=2, ncols=2)
figure.set_size_inches(15, 10)
sns.boxplot(x = "gender", data = st_data3, ax=ax1)
sns.boxplot(x = "age", data = st_data3, ax=ax2)
sns.boxplot(x = "avg_glucose_level", data = st_data3, ax=ax3)
sns.boxplot(x = "bmi", data = st_data3, ax=ax4)
Python
복사
4. 데이터 시각화
4-1. countplot
figure, ((ax1, ax2), (ax3, ax4), (ax5, ax6)) = plt.subplots(nrows=3, ncols=2) #가로3 세로 2
figure.set_size_inches(15, 15)
sns.countplot('hypertension', data=st_data3, ax=ax1)
sns.countplot('heart_disease', data=st_data3, ax=ax2)
sns.countplot('ever_married', data=st_data3, ax=ax3)
sns.countplot('work_type', data=st_data3, ax=ax4)
sns.countplot('Residence_type', data=st_data3, ax=ax5)
sns.countplot('smoking_status', data=st_data3, ax=ax6)
Python
복사
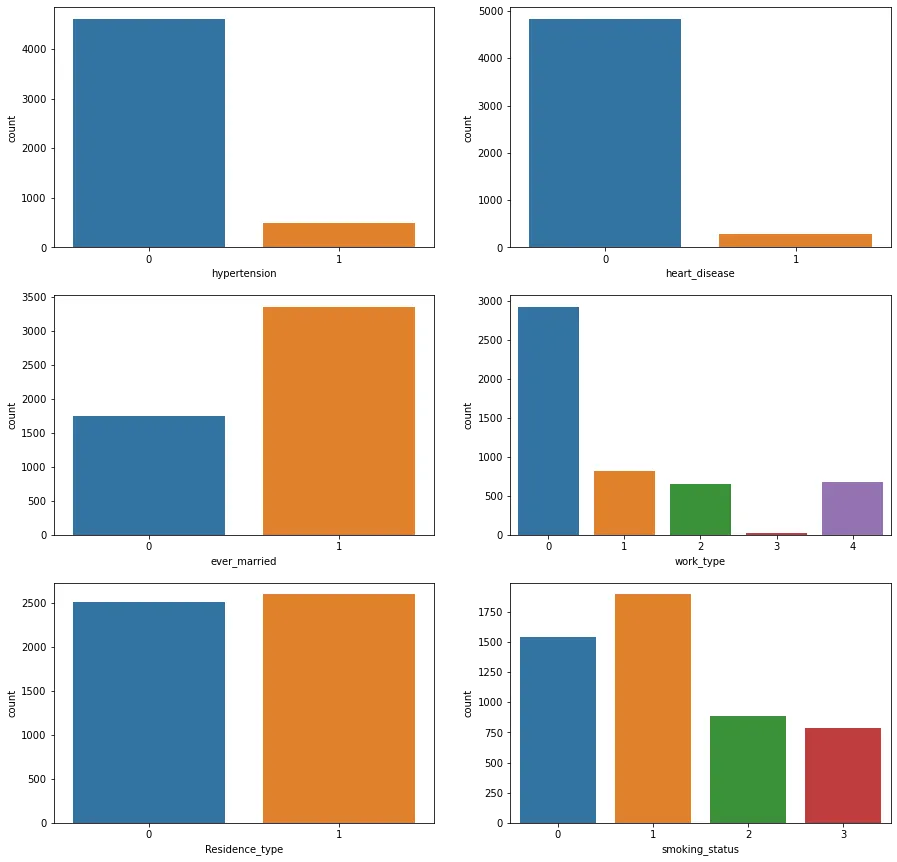
1.
고혈압과 심장병은 대부분 가지고 있지 않다.
2.
결혼경험이 있는 사람이 많다.
3.
'Private'가 가장 많다. 일을 안해본 사람은 거의 없다.
4.
시골과 도시에 반반 거주한다.
5.
담배는 안피는 사람이 많고 흡연을 해본 사람보다 현재 흡연중인 사람이 더 적다.
4-2. violinplot
figure, ((ax1, ax2)) = plt.subplots(nrows=1, ncols=2)
figure.set_size_inches(15, 10)
sns.violinplot('gender', 'age', hue='stroke', split=True, data=st_data3, ax=ax1)
sns.violinplot('gender', 'avg_glucose_level', hue='stroke', split=True, data=st_data3, ax=ax2)
Python
복사
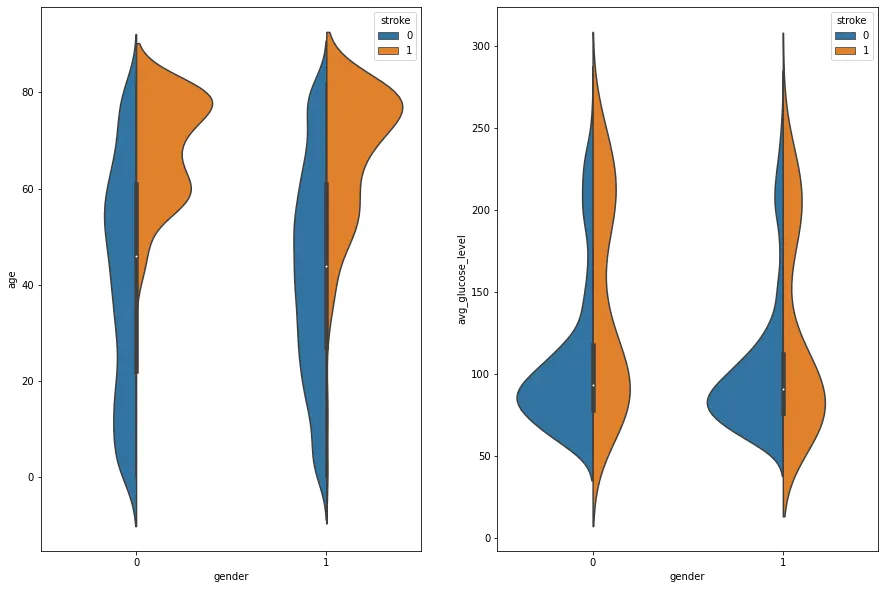
1.
나이가 많을수록 뇌졸중 위험이 높아진다.
2.
혈당 수치가 너무 낮거나 너무 높으면 뇌졸중 위험이 높아진다.
Q : 아니 혈당 수치가 높을수록 뇌졸중에 잘 걸린다면서 왜 낮은데도 뇌졸중 발병률이 높지?
→ 고혈당은 혈당을 올리는 글루카곤, 에피네프린 같은 교감신경 호르몬 분비가 과도하게 이루어져서 생긴다. 이 과정에서 교감신경이 과도하게 긴장하면서 관상동맥을 좁게 만들어 혈류 부전을 일으키고 이는 뇌졸중으로 이어진다. 저혈당의 경우에도 몸의 혈당이 낮기 때문에 몸에서는 혈당을 높이기 위해 교감신경 호르몬을 많이 분비하게 되고 이는 결국 고혈당으로 인한 뇌졸중과 같은 메커니즘을 만들어내게 된다.
요약 : 혈당 수치가 너무 높거나 너무 낮으면 교감신경 호르몬의 과다분비로 인해 동맥 수축이 일어나고 뇌졸중을 발병시킨다.
혈당은 80~170mg/dL 정도가 정상이다. 180 이상이면 고혈당, 70 이하면 저혈당.
5. 상관분석
#상관관계 파악(상관계수)
corrMatt = st_data3[['gender', 'age', 'hypertension', 'heart_disease', 'ever_married', 'work_type', 'Residence_type', 'avg_glucose_level', 'bmi', 'smoking_status', 'stroke']]
corrMatt = corrMatt.corr()
corrMatt
Python
복사
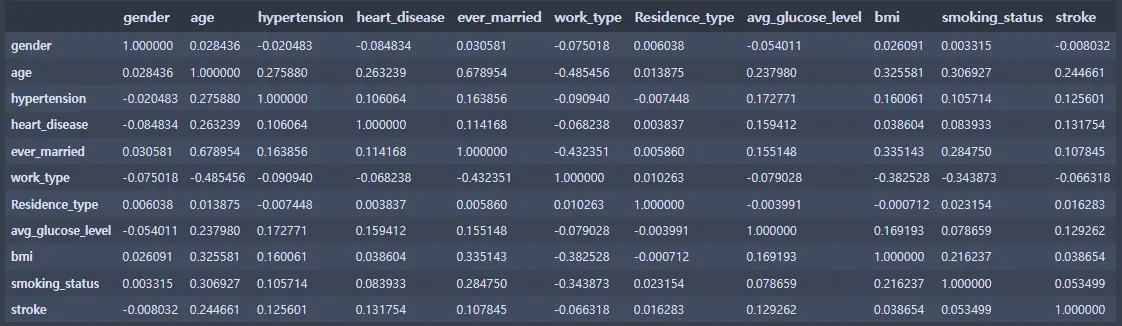
mask=np.zeros_like(corrMatt, dtype=np.bool)
mask[np.triu_indices_from(mask)] = True
figure, ax = plt.subplots()
figure.set_size_inches(20, 10)
sns.heatmap(corrMatt, mask=mask, vmin=-1, vmax=1, square=True, annot=True)
Python
복사
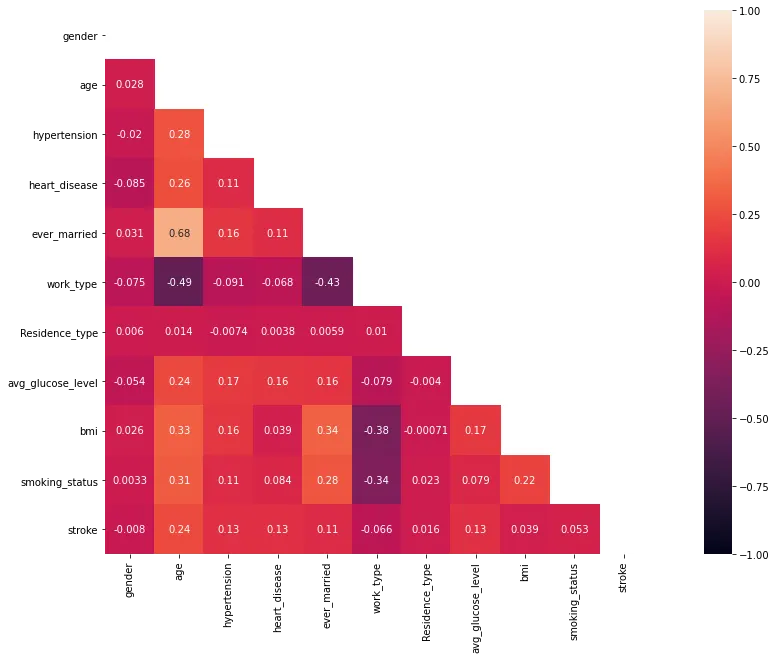
뇌졸중은 나이와 가장 큰 상관관계를 이루고 고혈압, 심장병과도 약한 상관관계를 이룬다.
위에서 알 수 있었듯 혈당과도 상관관계가 있으나, 저혈당과 고혈당 모두 뇌졸중 위험이 있기에 상관계수가 애매하게 측정되는 것 같다.
강한 상관관계인 데이터
•
나이와 결혼경험
뚜렷한 상관관계인 데이터
•
나이와 직업 (음의 상관관계)
•
나이와 흡연상태
•
나이와 bmi
•
결혼경험과 직업 (음의 상관관계)
•
결혼경험과 bmi
•
직업과 bmi (음의 상관관계)
•
직업과 흡연상태 (음의 상관관계)
6. 회귀분석
•
종속 변수 : stroke, age
•
독립 변수 : bmi, avg_glucose_level
sns.lmplot('age', 'bmi', hue='stroke', data=st_data3)
Python
복사

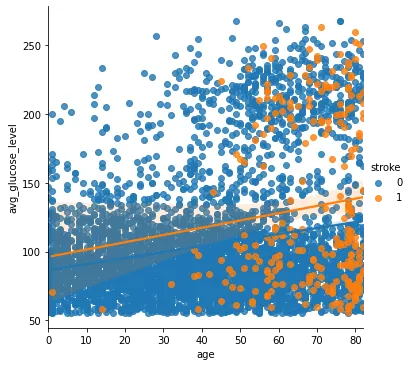
나이가 많을수록 주황색 점이 많아짐.
bmi랑은 별로 상관이 없는거 같다.
sns.lmplot('age', 'avg_glucose_level', hue='stroke', data=st_data3)
Python
복사