

이 Lab 에서는 파일 업로더를 사용하여 데이터를 미리 보고 나중에 대규모로 데이터를 수집하는데 필요한 몇
가지 building block 을 개발하는 방법을 배운다.
Nginx 웹 서버가 실행되는 동일한 시스템에서 실행 중인 사용자 정의 Java 애플리케이션 로그 (advertisingService)를 수집하는 작업을 할 것이다.
이 Lab 을 위해서는 샘플 로그 파일을 다운로드 해야한다.
High level outline:
•
로그의 작은 샘플을 사용하여 데이터가 어떻게 보이는지 미리 보기
•
올바른 수집 규칙 - 우리의 경우 기본 GROK 패턴을 Kibana 의 Grok 디버거의 도움으로 해결
•
다음 Lab 에서 대규모로 데이터를 수집하는 데 사용할 수집 파이프라인을 만들기
랜딩 페이지에서 메뉴 아이콘을 클릭한 다음 “Upload a file”를 클릭한다.
“Select or drag and drop a file”을 클릭하고 메시지가 표시되면 다운로드한 ads_log_sample.log 파일을 선택한다.
파일 내용이 분석되는 화면으로 이동한다. 화면 하단에 몇 가지 필드 제안이 표시되고 이와 유사한 파일을 구문 분석하는데 사용할 수 있는 GROK 패턴이 제안되어 있는 것을 확인한다.
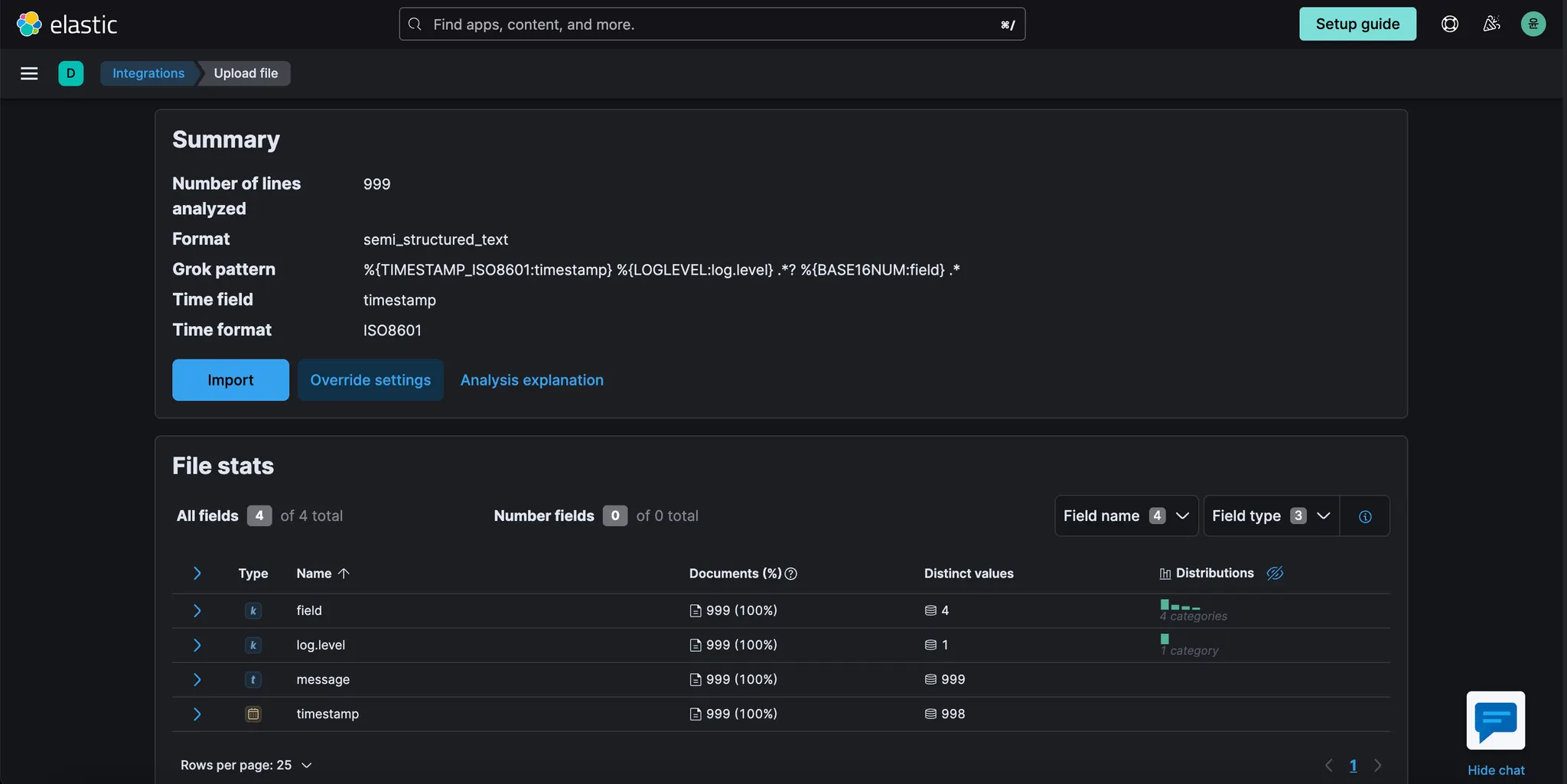
필드와 GROK 패턴 모두에 대한 제안이 완벽하지는 않지만(예를 들어 "message" 필드가 누락됨), 이 문제를 어떻게 개선할 수 있는지 살펴보자.
메뉴 버튼을 클릭하고 새 탭에서 “Dev Tools”를 열어 현재 페이지에서 벗어나지 않도록 한다.
“Dev Tools” 페이지에서 “Grok Debugger”를 클릭한다. 이후 아래의 내용을 입력하고 Simulate를 클릭한다.
•
Sample Data
◦
2021-02-03T00:54:41.710Z INFO received ad request (context_words=[Photography])
•
Grok Pattern
◦
%{TIMESTAMP_ISO8601:timestamp} %{LOGLEVEL:log.level} .? %{BASE16NUM:field} .
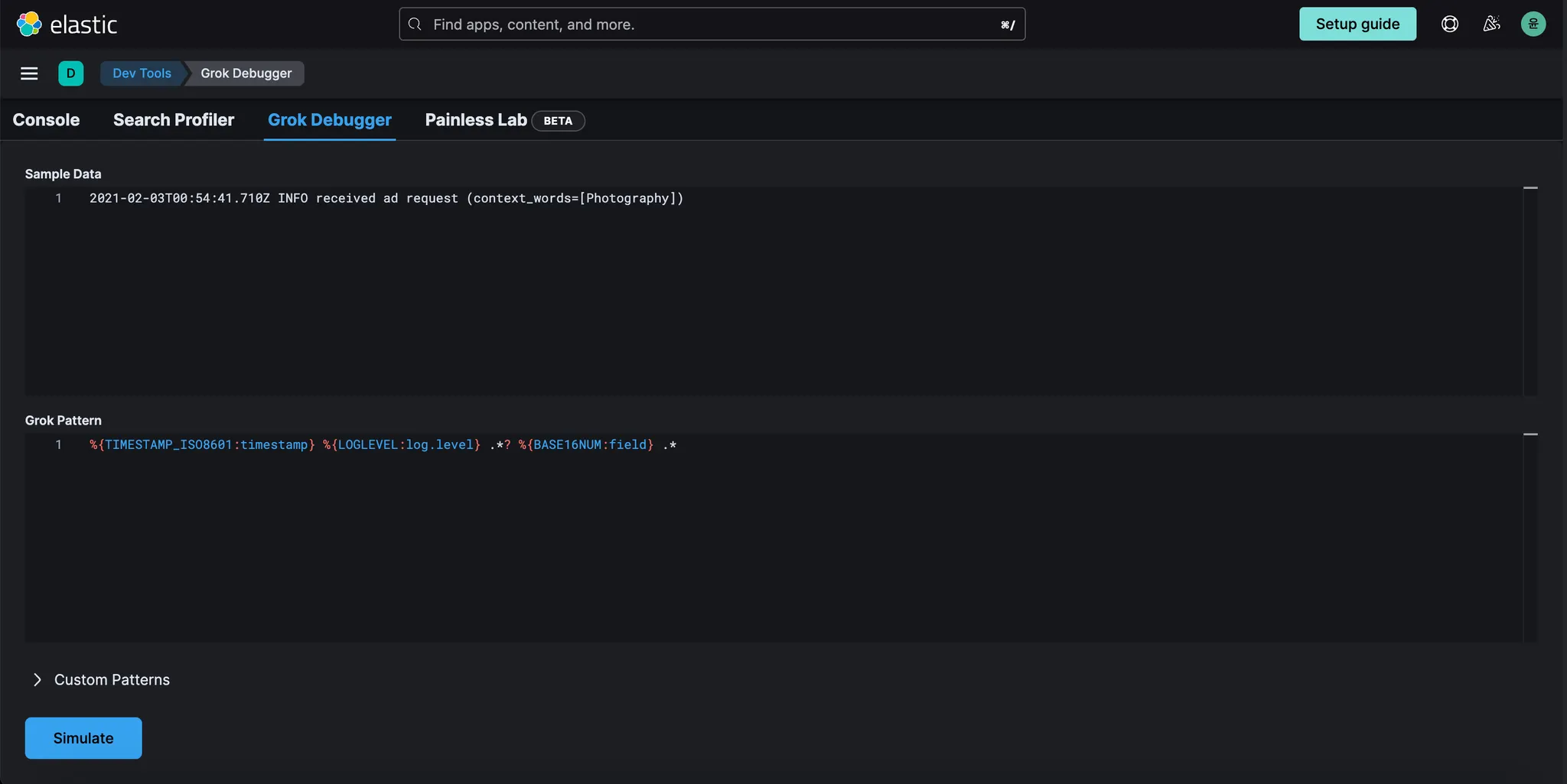
결과를 확인한다.

timestamp 도 올바르게 설정했고 log level 도 올바르게 설정했지만 field type 이 다소 엄격하다.
대문자/소문자라도 차이가 있으면 에러가 발생할 수 있으며, 가장 중요한 것은 "message" 필드에 "received
ad request (context_words=[Photography])" 값이 포함된 Elastic Common Schema 에 따라 존재하기를 원한다는 것이다. 이를 제공하는 또 다른 GROK 패턴을 시도해 보자.
•
Grok Pattern
◦
%{TIMESTAMP_ISO8601:timestamp} %{DATA:log.level} %{GREEDYDATA:message}
위 데이터를 집어넣고 다시 시도.

이제 이것이 바로 우리가 찾고 있는 최소한의 format 이다.
예를 들어 "context_words" 필드를 생성하여 값을 추출할 수 있지만(이 경우 "Photography"), 지금은 그렇게 할 필요는 없다. "timestamp", "log.level", "message" 필드만 있어도 다음 Lab 에서 배우게 될 것처럼 로그에 대해 이미 많은 분석을 수행할 수 있다.
다시 Data Visualizer으로 돌아간다. 그리고 Override settings를 클릭한다.
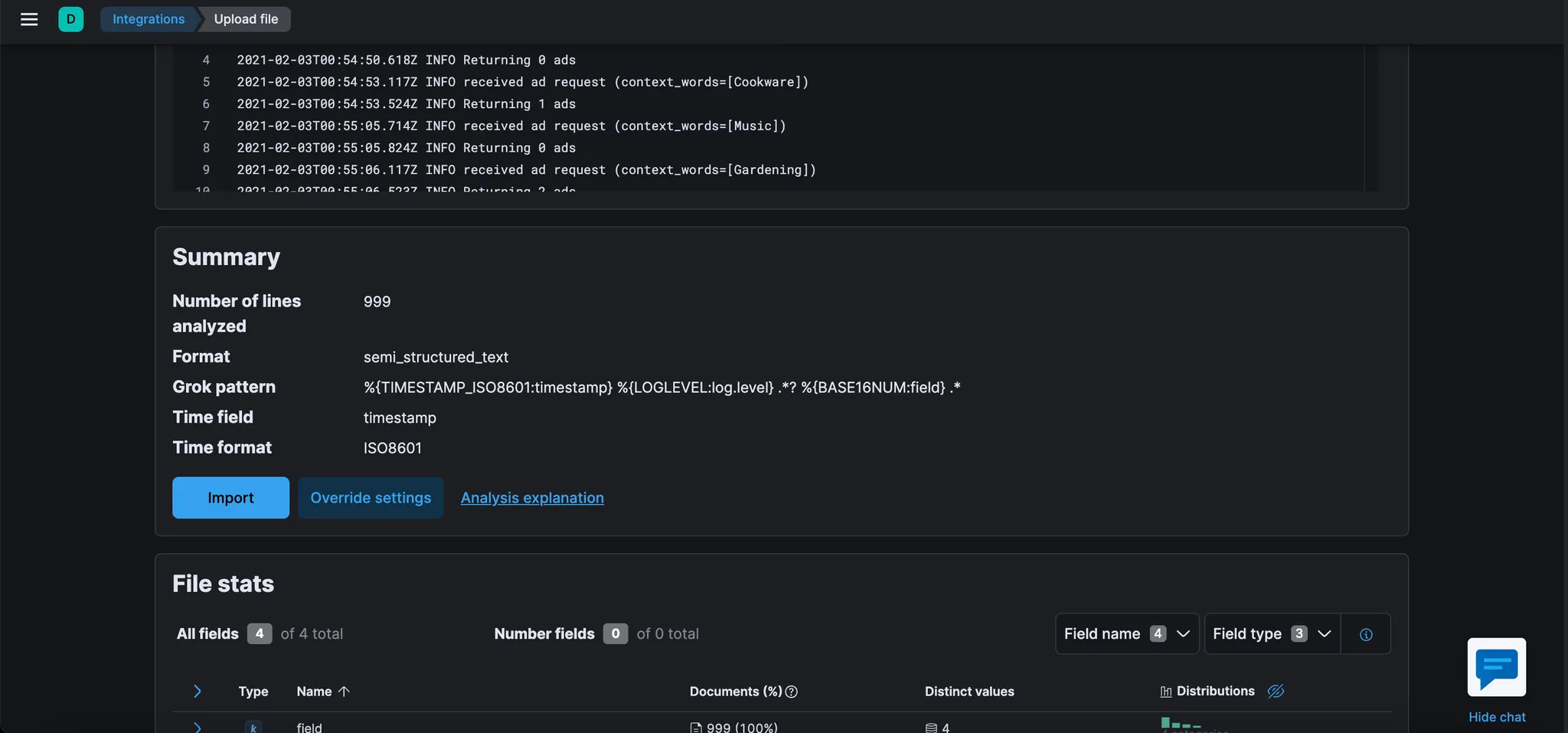
다음의 내용을 입력후, Apply를 클릭한다.
•
Grok pattern
◦
%{TIMESTAMP_ISO8601:timestamp} %{DATA:log.level} %{GREEDYDATA:message}
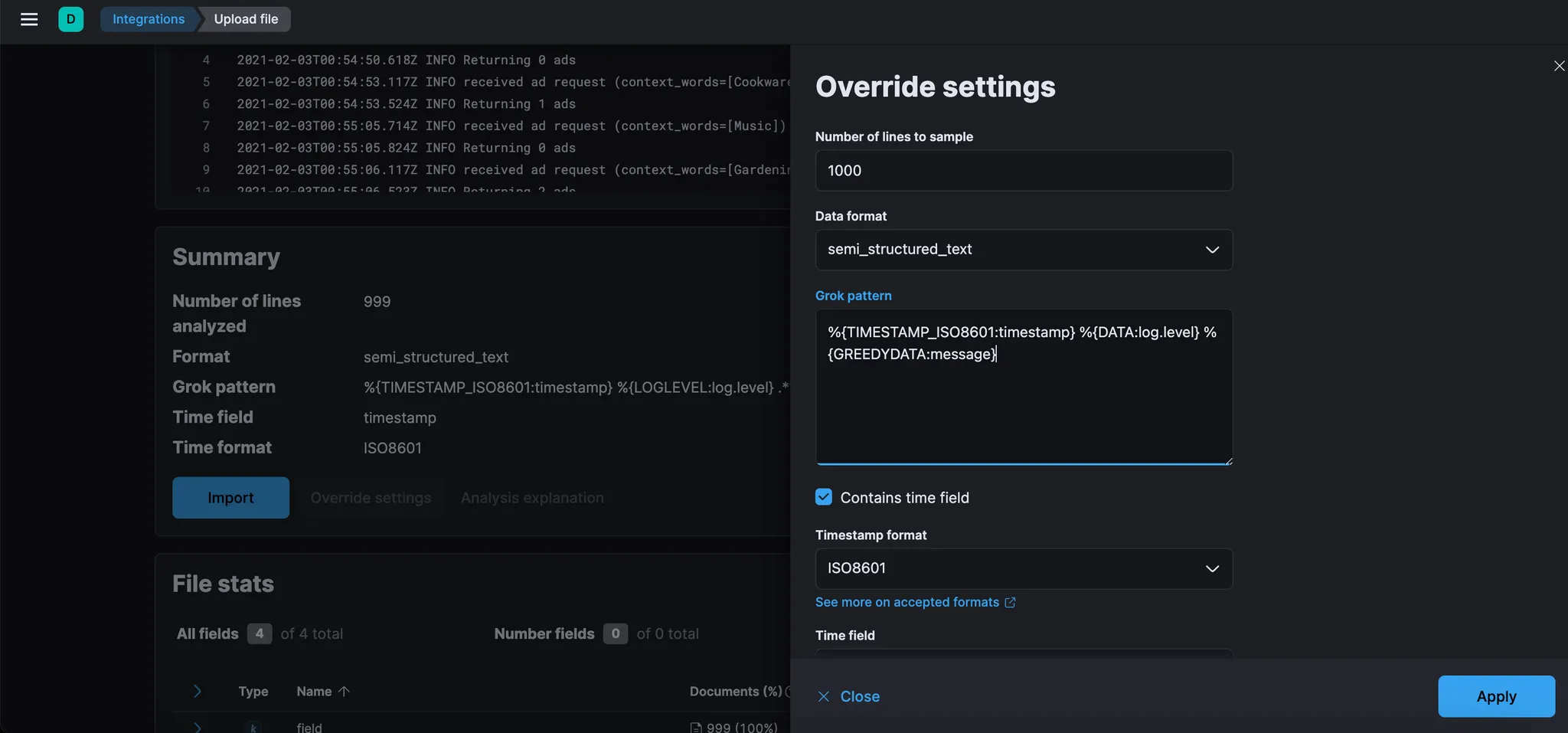
화면 하단의 Import 버튼을 클릭 후, Advanced 선택.
•
Index name : ads-log
•
Mappings : “type”: “text” → 이렇게 해야 full text search 을 통해 검색할 수 있게 된다.
위의 내용을 수정하고 Import 클릭
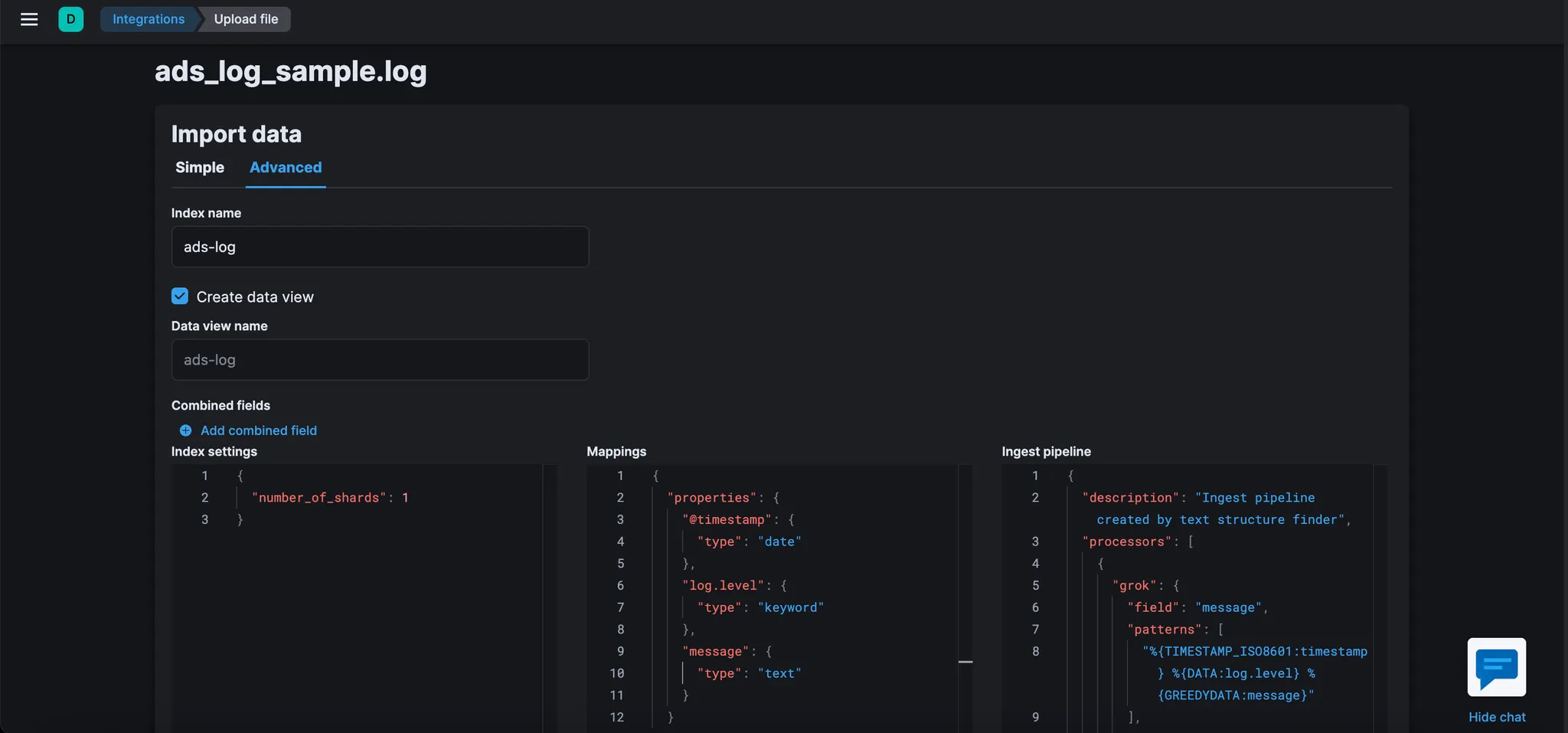
완료되면 다음과 같은 내용이 표시된다.
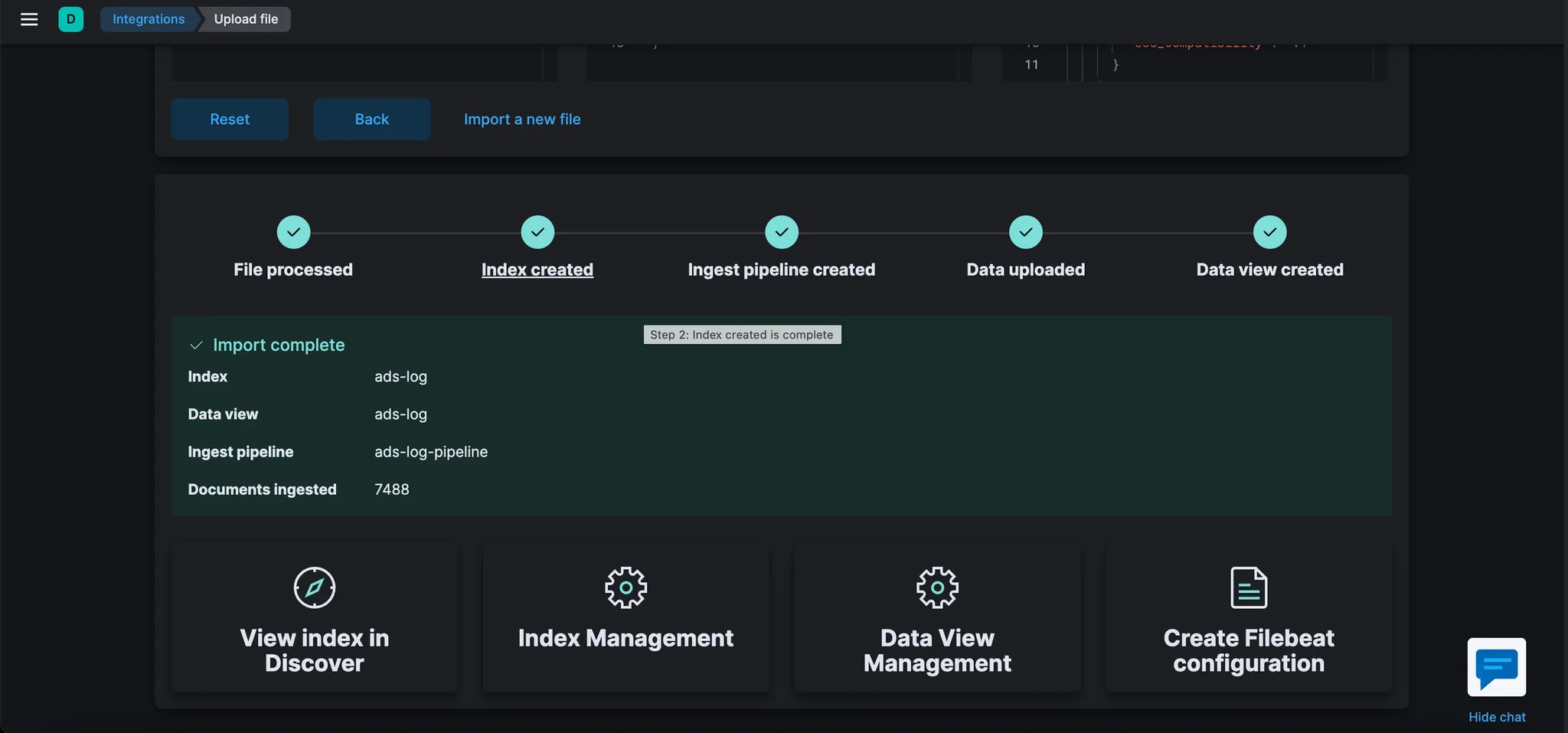
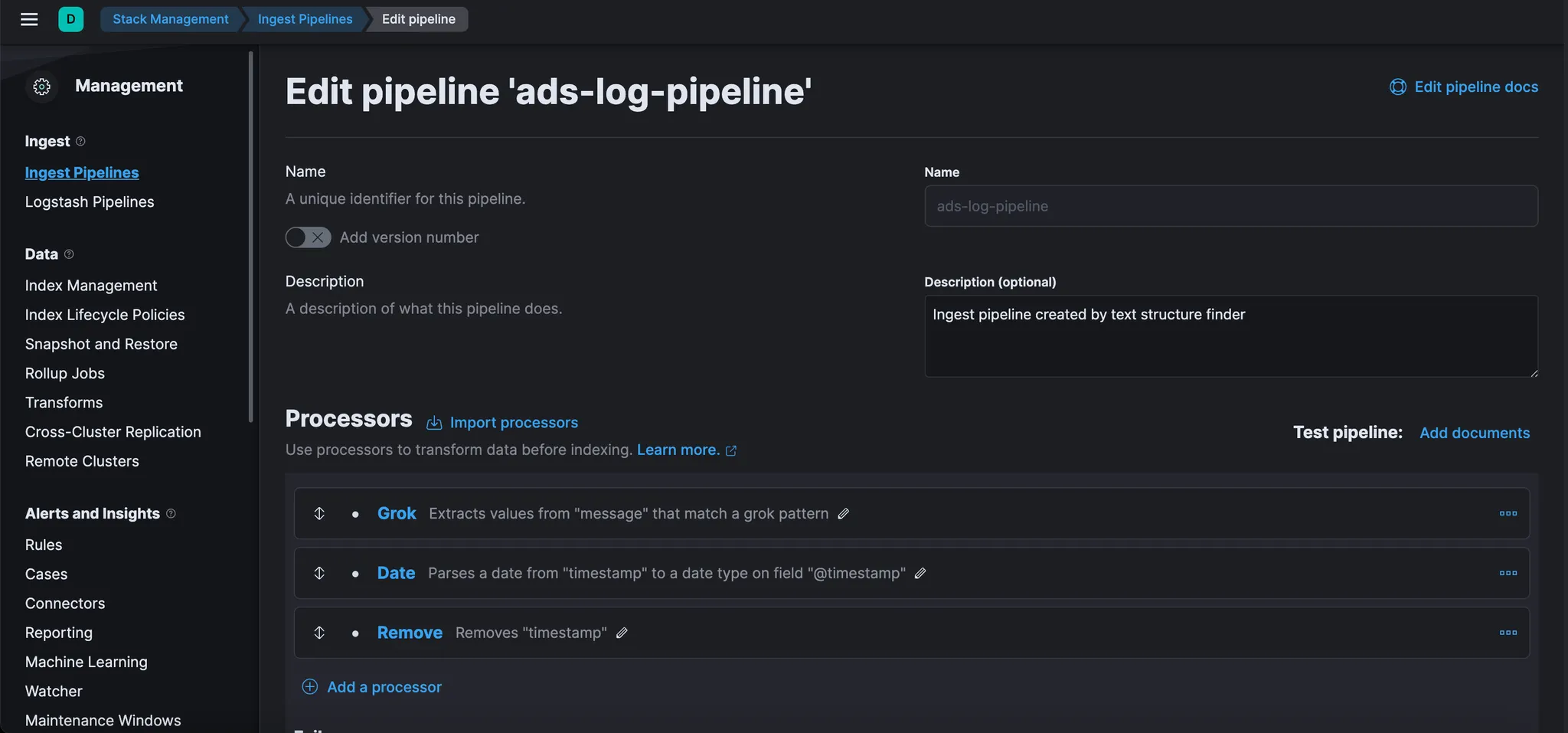
제공한 Grok 패턴으로 수집 파이프라인이 어떻게 생성되었는지 확인한다.
이 경우 파이프라인의 이름은 "ads-log-pipeline"이다.
"View index in Discover"를 클릭하고 로그 샘플에서 가져온 데이터를 탐색한다. 이것은 이 수집 파이프라인을 사용하여 데이터를 가져오면 데이터가 어떻게 보일지 미리 보여주는 것이다.
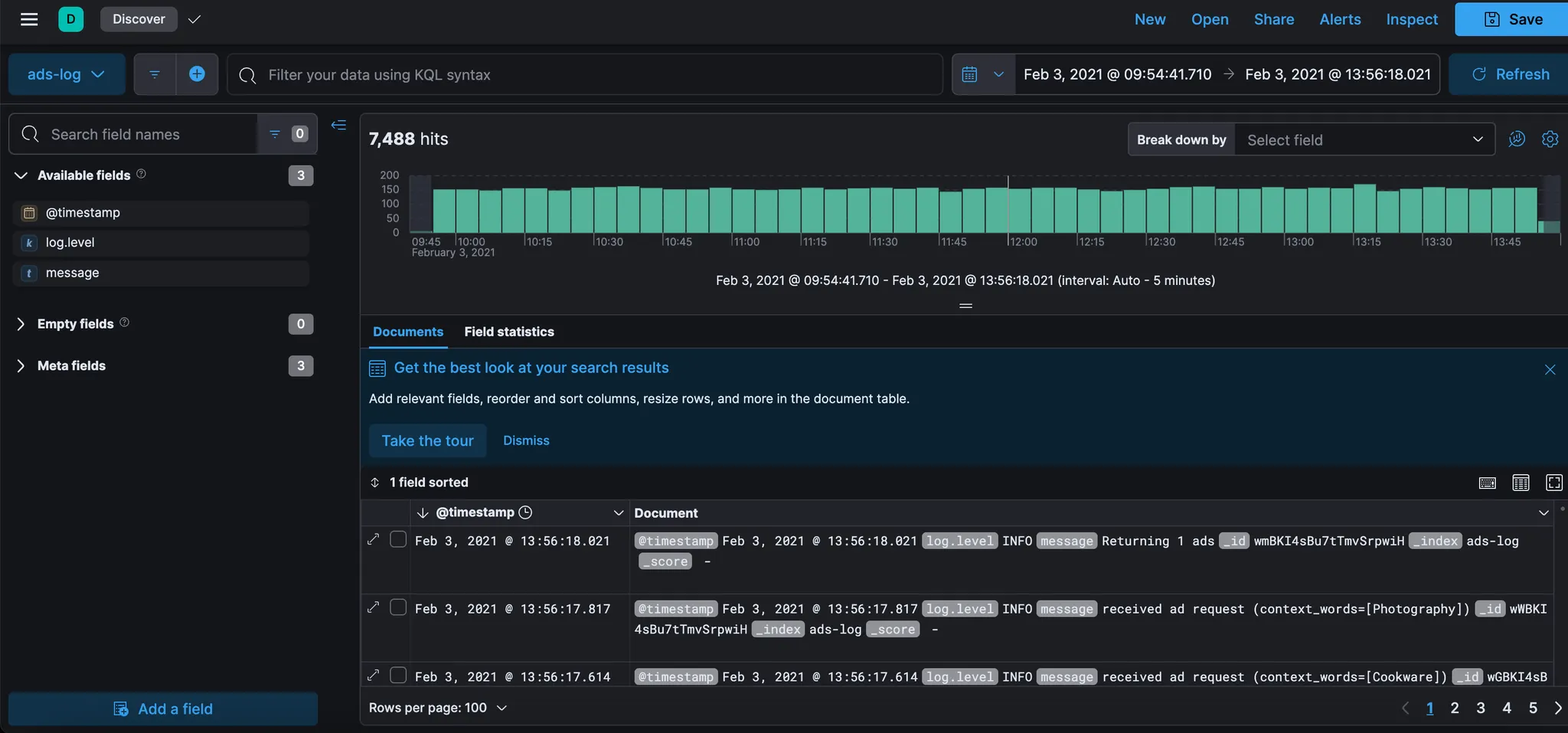
마지막 단계로 스택 관리 섹션에서 생성된 ingest pipeline 을 살펴보자.
Kibana 메뉴 버튼을 클릭하고 "Stack Management"를 선택한다.
메뉴에서 “Ingest Pipelines”을 클릭한 다음 위에서 저장한 “ads-log-pipeline”을 클릭한다.
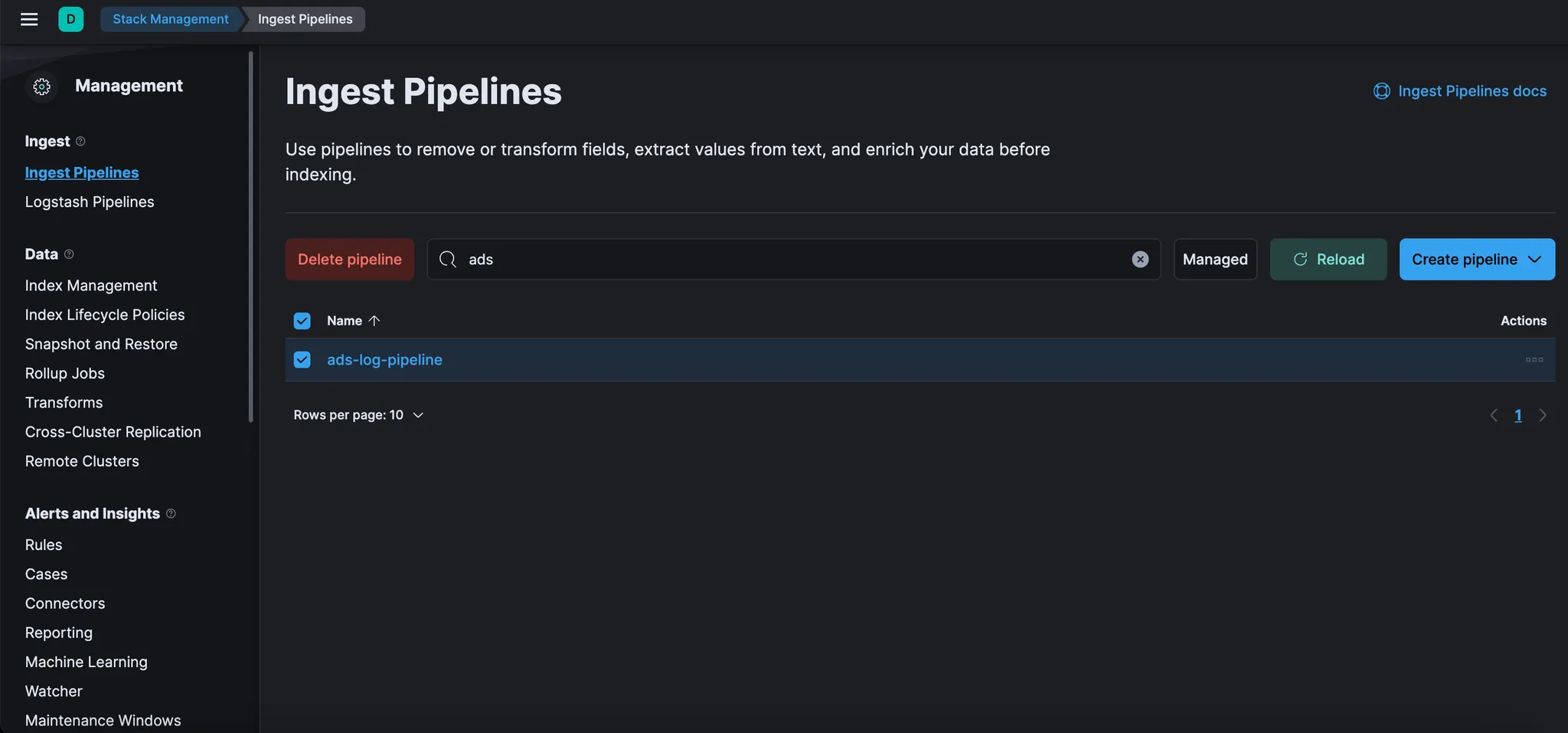
이 섹션에서 언제든지 Ingest Pipelines 을 찾을 수 있다. 이 섹션을 사용하여 새 파이프라인을 만들거나 기존 파이프라인을 수정할 수도 있다.
“ads-log-pipeline” 하단의 “manage” 버튼 Click 후, “Pipeline options” → “Edit” 을 클릭하여 편집할 수 있다. 그러면 파이프라인의 구조를 확인할 수 있는 다음 화면으로 이동한다.
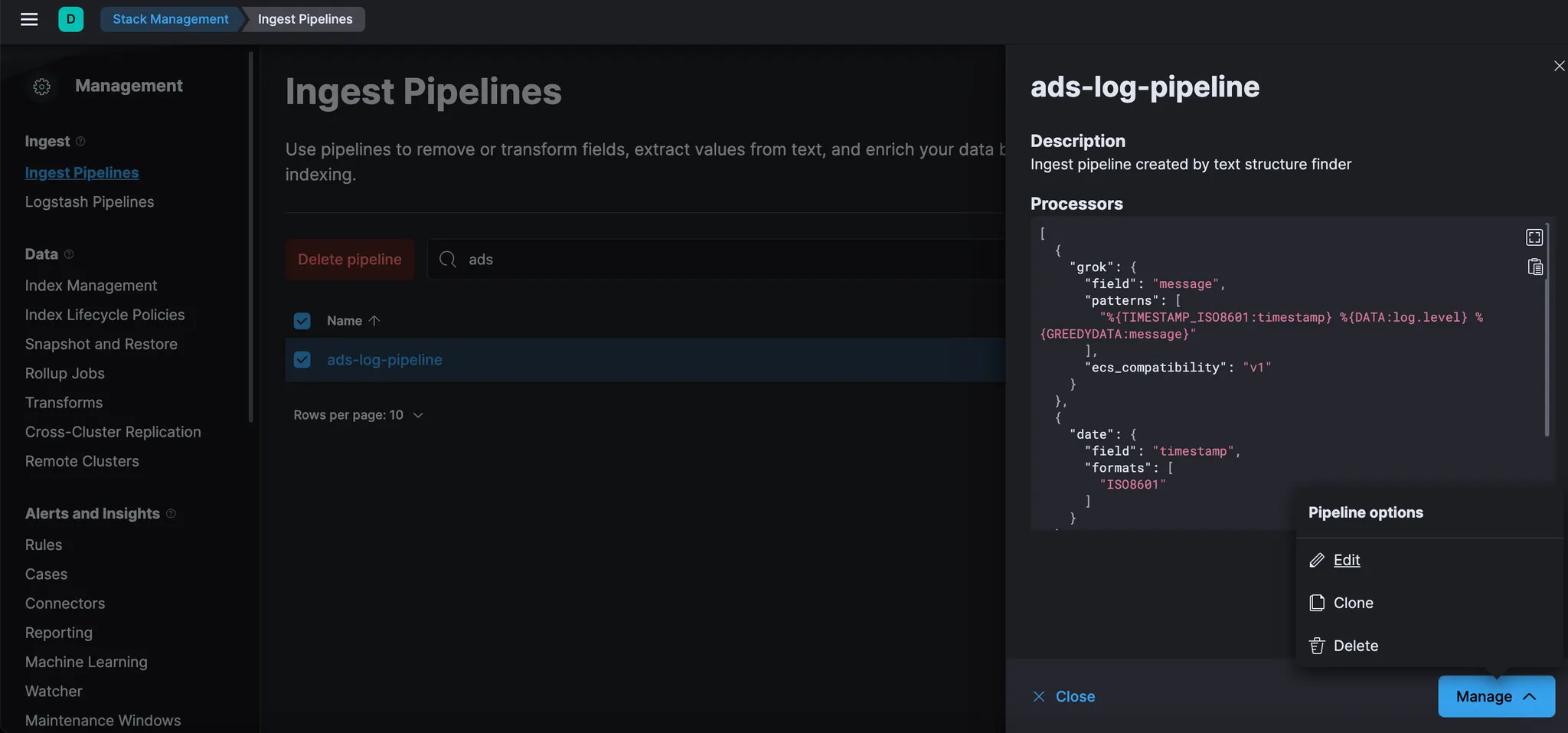
여기에서 설정과 프로세서 순서를 변경하거나, 새 프로세서를 추가하거나, 샘플 문서로 파이프라인을 테스트할 수 있다. 변경 사항은 따로 저장하지 않고, 완료되면 "Cancel" 버튼을 클릭한다.
이번 Lab 에서는 advertService Java 프로그램에 대한 로그의 small sample 을 Data Visualizer 와 Grok
디버거를 사용하여
•
로그의 기본 구조를 이해하고,
•
Grok 프로세서로 parsing rule 을 작성하고,
•
이 로그가 대규모로 수집되기 시작하면 다음 Lab 에서 사용할 Ingest Pipeline 을 통해 parsing rule 을
자동화 해보았다.