
실습 준비
•
실습 파일 clone
git clone https://github.com/YunSeo00/spark-streaming.git
Python
복사
docker 컨테이너 띄우기 및 jupyter notebook 실행
docker-compose up
# 로그에 나오는 jupyter notebook 링크로 접속
Python
복사
1. 실시간으로 socket에 입력되는 문장의 단어 개수 세기 - 방학세션 복습
필요한 패키지 설치 및 환경 조성
1.
랜덤으로 문장을 생성하기 위해 Faker 라이브러리 설치
pip install Faker
Python
복사
2.
matplotlib 라이브러리에서 한글 깨짐 방지를 위해 나눔 폰트 설치
sudo apt-get update
# 나눔 폰트 설치
sudo apt-get install fonts-nanum
# matplotlib에 남아있는 폰트 캐시 삭제
rm -rf ~/.cache/matplotlib/*
# 폰트 캐시 생성
fc-cache -fv
Bash
복사
3.
socket으로 문장을 보내는 파일 실행
cd streaming
python sendData.py
Python
복사
코드
4.
visualization.ipynb 실행
•
SparkSession 생성
spark = SparkSession.builder \
.appName("SocketStreamingWordCount") \
.getOrCreate()
Python
복사
•
socket stream 생성 및 설정
# StreamingContext 생성
ssc = StreamingContext(spark.sparkContext, 10)
# 소켓 버퍼 크기 설정 (예: 1024 바이트)
conf = spark.sparkContext.getConf()
conf.set("spark.streaming.receiver.maxRate", "1024")
# 소켓 스트림 생성
socket_stream = ssc.socketTextStream("127.0.0.1", 5555)
Python
복사
•
윈도우 설정
◦
20 second의 window 설정 → 20초 전에 입력된 단어는 카운트 집계에 세지지 않는다.
# 윈도우 설정
lines = socket_stream.window(20)
Python
복사
•
단어 카운트
◦
가장 하단에 registerTempTable 을 통해 새로운 스트리밍 임시 뷰를 생성한다.
→ 이를 이용하여 sql 구문을 사용할 수 있게 됨.
(lines.flatMap(lambda line: line.split(" ")) # 공백을 기준으로 단어 분리
.filter(lambda word: len(word) > 1) # 한 글자 단어 제외
.map(lambda word: (word,1)) # key, value 쌍으로 변환
.reduceByKey(lambda a, b: a + b) # reduce 연산
.foreachRDD( lambda rdd: rdd.toDF(["word","count"]).sort( desc("count")) # RDD Dataframe에 count수 기준으로 정렬해서 저장
.limit(10).registerTempTable("word_counts")))
Python
복사
5.
word_counts 임시 뷰를 이용하여 만든 그래프 변화 살펴보기
2. 실시간으로 폴더에 추가되는 csv 파일 정보 집계하기 (with 파티션)
•
mldata 폴더에 적재되는 csv 파일을 실시간으로 집계 후 postgres에 저장하는 실습
◦
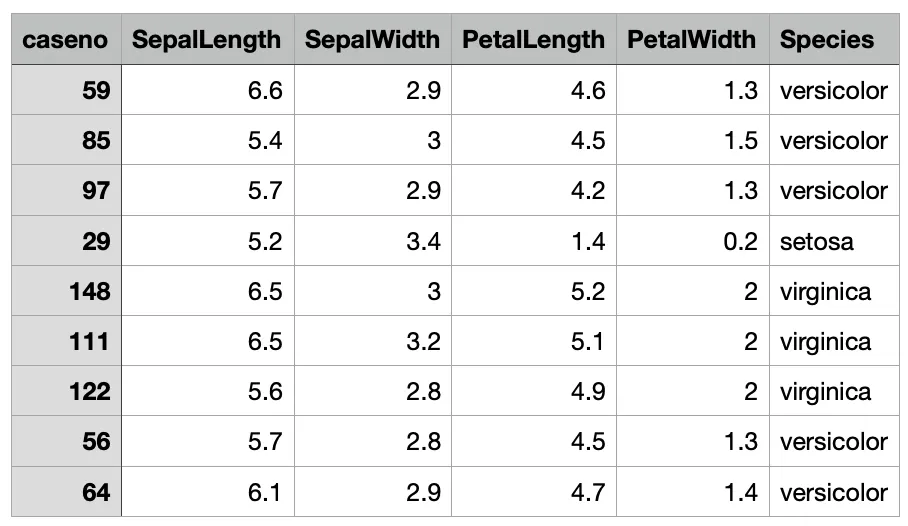
IRIS 데이터 살펴보기
•
csv_count.py 실행
python csv_count_and_save.py
Python
복사
코드
•
postgres container 접속 및 테이블 변화 살펴보기
docker exec -it spark-streaming-postgres-1 /bin/bash
psql -U boaz -d boaz
\dt # table 확인
select * from iriscount; # 내용 확인
Python
복사
•
mldata 폴더에 데이터 추가하면서 실시간으로 집계되는 결과 살펴보기
◦
mldata/year=2023/iris.csv
◦
mldata/data=2020-09-27/iris.csv → 오류