


간단한 용어 설명
스케줄러
•
특정 작업을 실행하는 시기, 주기를 관리하기 위한 방법.
오케스트레이션 (오케스트레이터)
•
작업을 수행하기 위한 여러 자원(인스턴스, 복제 등)을 관리하고, 여러 개의 작업을 연결해 큰 워크플로우를 실행하는 방법.
Airflow
Airflow란?
•
Airflow는 스케줄러를 넘어 데이터 파이프라인을 위한 플랫폼
◦
Airbnb에서 시작한 아파치 오픈소스 프로젝트로, 현재는 Top-level Apache 프로젝트
◦
가장 많이 사용되는 데이터 파이프라인 프레임워크 중 하나
◦
배치 중심의 프레임워크 (batch-oriented framework)
•
데이터 파이프라인 프레임워크
◦
Python 3에서 데이터 파이프라인을 프로그래밍 방식으로 설계, 예약 및 모니터링 지원
◦
데이터 프로세스 과정에서 중요한 역할을 하며 다양한 분산 시스템에서 발생하는 작업을 조율
•
다양한 타사 서비스와의 매우 포괄적인 통합을 이루고 있습니다.
Airflow 스케줄링
•
데이터 파이프라인 스케줄링 지원
◦
정해진 시간에 ETL 실행 혹은 한 ETL의 실행이 끝나면 다음 ETL 실행
◦
웹 UI도 있다!
Airflow 모듈 제공
•
데이터 파이프라인을 쉽게 개발할 수 있도록 도와줌
◦
다양한 데이터 소스와 데이터 웨어하우스를 쉽게 통합해주는 모듈 제공
◦
데이터 파이프라인 관리 관련 다양한 기능을 제공 ⇒ 특히 Backfill
▪
위의 많은 워크플로우 관리 도구들이 제공하는 주요 기능은 의존성이 있는 다수 태스크가 포함된 파이프라인을 정의하고 실행하는 것
•
백필(Backfill)
Backfill의 용이성 여부 → 데이터 엔지니어 삶에 직접적인 영향!
◦
Backfill의 정의

실행 중에 실패한 파이프라인을 재실행하거나, 데이터에 문제가 있어 다시 읽어와야 하는 경우를 의미
◦
Backfill 해결은 Incremental Update에서 복잡해짐
▪
Full Refresh인 경우, 단순하게 다시 실행하면 됨
◦
즉, 실패한 데이터 파이프라인의 재실행이 얼마나 용이한 구조인가?
▪
이게 잘 디자인된 것이 바로 Airflow
◦
대규모 데이터 세트를 처리하는 경우, 전체 태스크를 모두 다시 실행하는 것을 방지해 많은 시간과 비용을 아낄 수 있음
◦
스케줄 주기와 백필 개념을 연결해, 스케줄 주기를 활용할 수 있음
▪
새로 생성한 DAG를 과거 시점으로 실행해 백필하는 것이 가능
▪
과거 특정 기간에 대해 DAG를 실행해 새로운 데이터 세트를 손쉽게 생성(또는 백필) 가능
◦
과거 실행 결과를 삭제한 후, 태스크 코드를 변경한 후에 과거 태스크를 쉽게 재실행할 수 있기 때문에 필요할 때 전체 데이터 세트를 간단하게 재구성 가능
Airflow DAG
•
Airflow의 데이터 파이프라인을 방향 비순환 그래프(DAG, Directed Acyclic Graph)라고 함
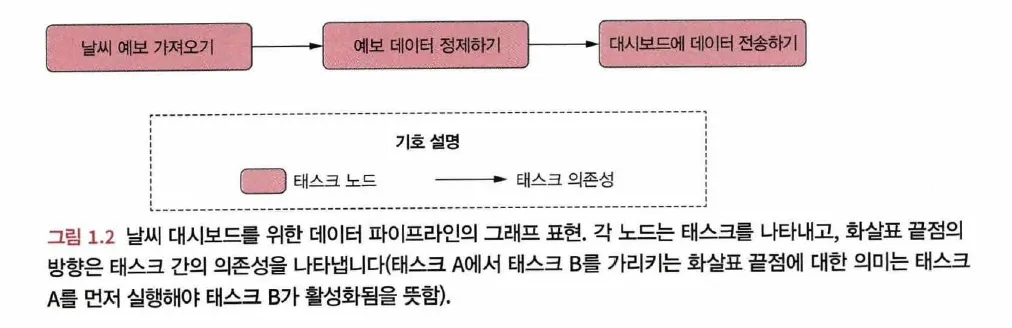
◦
태스크는 노드로 표시되고 태스크 간의 의존성은 태스크 노드 간의 방향으로 표시
만약 순환성이 있다면 어떻게 될까?
◦
DAG는 파이프라인 실행을 위한 단순한 알고리즘을 제공해준다는 데에서 이점이 존재
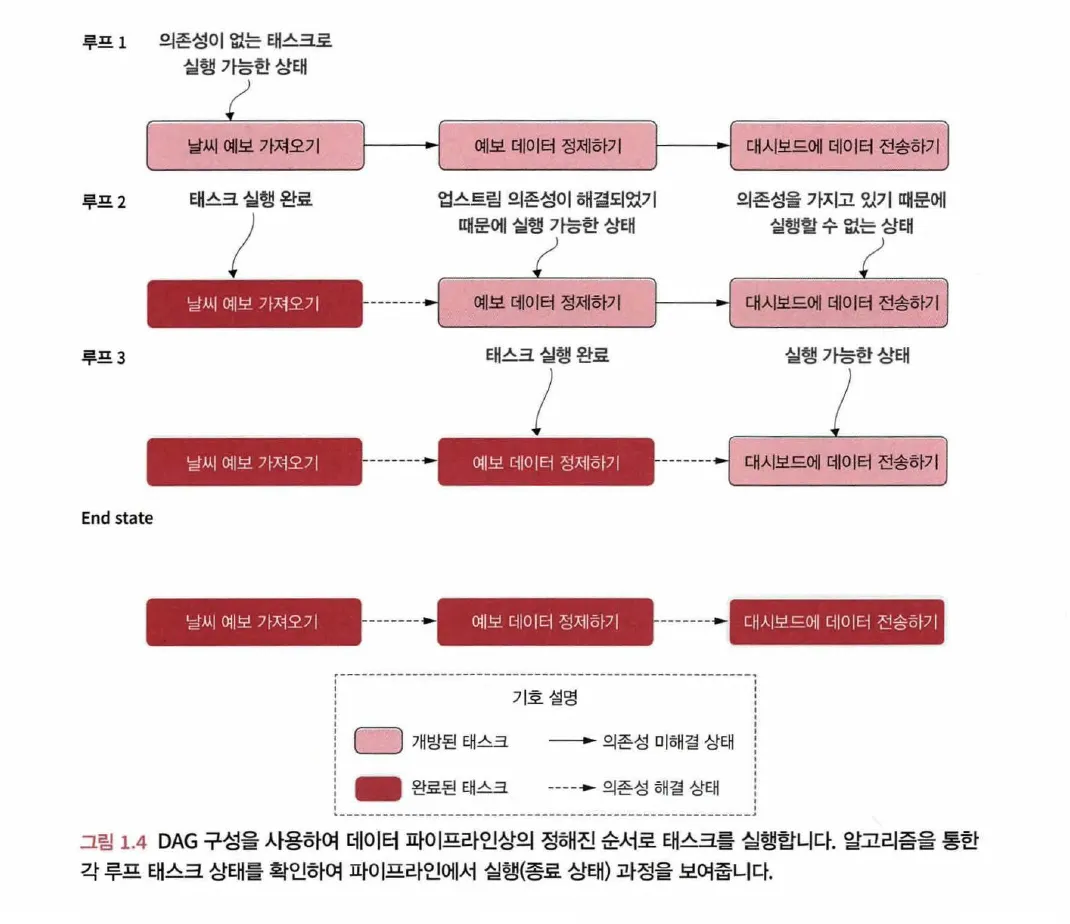
1.
그래프 내의 태스크는 각각 개방된(open, 미완료) 상태이며 다음과 같은 단계를 수행
a.
각각의 화살표 끝점은 태스크를 향하며 다음 태스크로 향하기 전에 이전 태스크가
완료되었는지 확인(1단계)
b.
태스크가 완료되면 다음에 실행해야 할 태스크를 대기열에 추가
2.
실행 대기열에 있는 태스크를 실행하고 태스크 수행이 완료되면 완료로 표시
3.
그래프의 모든 태스크가 완료될 때까지 1단계로 돌아감
•
하나의 DAG는 하나 이상의 태스크(Task)로 구성됨
•
Airflow는 Python 코드로 DAG의 구조를 정의
◦
각 DAG 파일은 DAG를 구성하는 태스크들의 명세와 태스크 간의 의존성을 나타냄
◦
그 외에도 DAG 파일에는 Airflow의 실행 방법, 시간 등을 정의한 몇 가지 추가 메타 데이터가 포함될 수 있음
◦
DAG를 Python 코드로 정의할 수 있기 때문에, 다양한 방법으로 유연하게 코드를 작성하고, 파이프라인을 구성할 수 있음
▪
외부 데이터베이스, 빅데이터 기술 및 다양한 클라우드 서비스를 포함한 다양한 시스템에서 태스크를 실행할 수 있도록 Airflow Provider들이 계속 개발
▪
여러 시스템과 플랫폼을 오가는 복잡한 데이터 파이프라인을 쉽게 구축할 수 있음
•
DAG에 Tag를 붙이는 기준 (예시): 소유자, 담당 팀, 중요도, 도메인 등Airflow 구성
•
Airflow는 하나 이상의 서버로 구성된 클러스터
◦
Worker 및 Scheduler로 구성됨
◦
스케줄러는 Task를 여러 개의 Worker에게 분배함
◦
DAG 및 스케줄링 정보는 DB에 저장됨 (SQLite, MySQL, PostgreSQL 등 사용 가능)
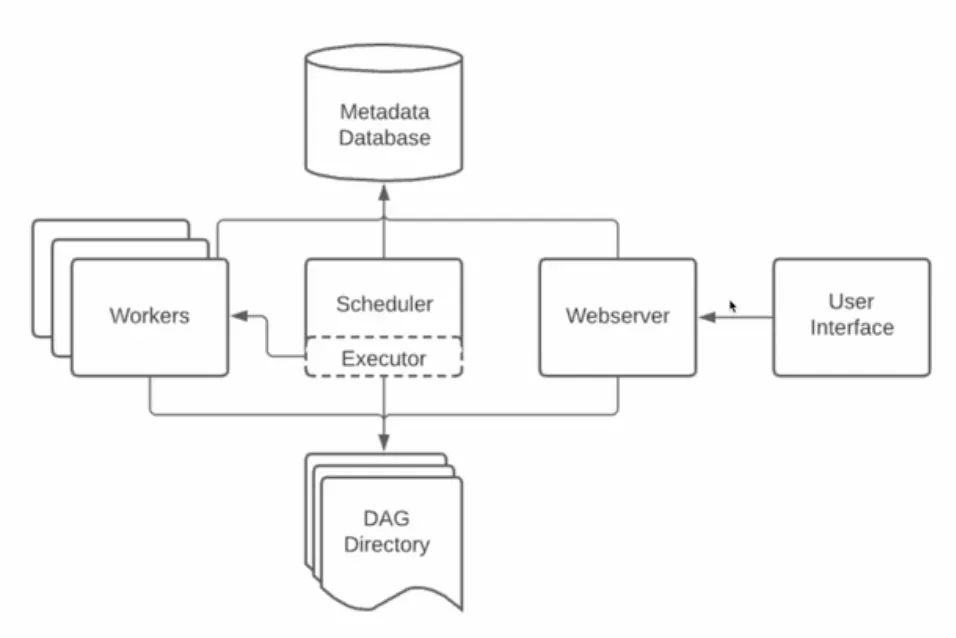
Airflow 구성
Airflow 컴포넌트
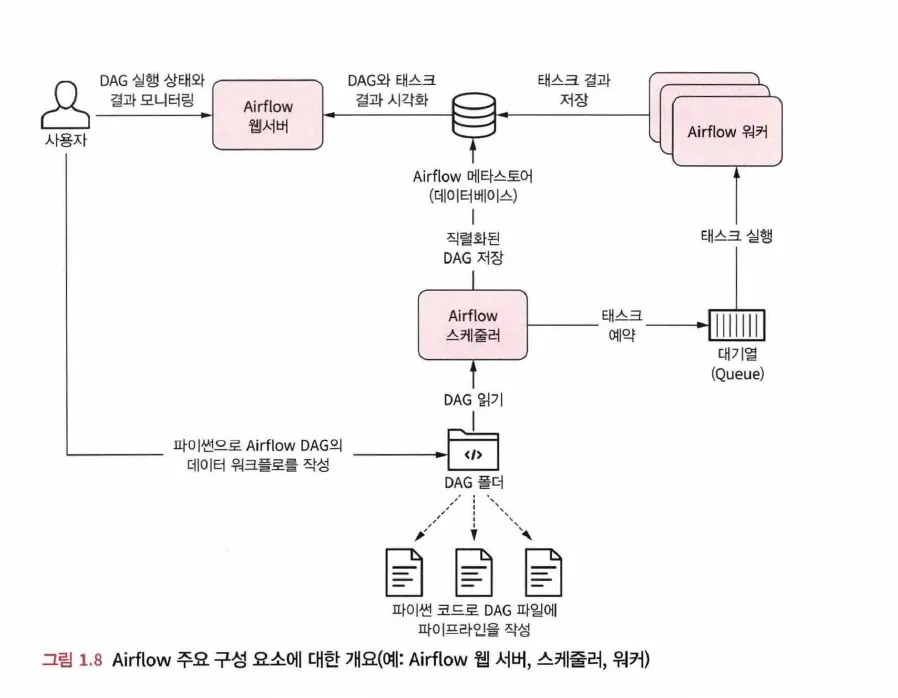
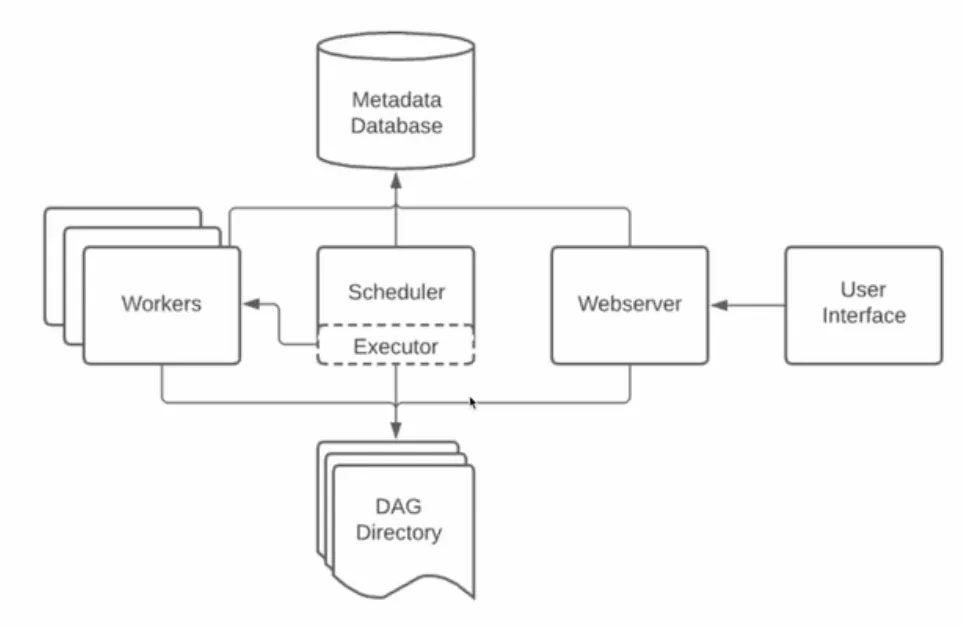
Apache Airflow는 총 5개의 컴포넌트로 구성됨
1.
Scheduler: DAG를 파싱하고, 현재 시점에서 DAG의 스케줄이 지난 경우 Worker에게 DAG의 태스크를 예약
•
파이프라인이 실행되는 시기와 방법을 결정하는 컴포넌트
•
주기적으로 DAG를 파싱하고, 파싱된 정보는 Meta DB에 기록하고 태스크는 Executor를 통해 워커에게 배정
•
DAG/태스크가 종료된 후 다른 태스크를 트리거하는 역할도 함
2.
Web Server: 스케줄러에서 분석한 DAG를 시각화하고 DAG 실행과 결과를 확인할 수 있는 웹 인터페이스
•
웹 서버는 Python Flask로 구현되어 있음
•
Scheduler와 DAG의 실행 상황을 시각화
3.
Worker: 예약된 태스크를 선택하고 실행
•
DAG를 실제로 실행하는 역할로, Task에 해당하는 Python 코드를 실행함
•
Airflow를 Scaling 해준다는 것은, Worker의 수를 늘린다는 것을 의미합니다.
4.
Meta Database
•
SQLite, MySQL, PostgreSQL 등 사용 가능
•
스케쥴링, Worker에 대한 정보 및 실행 결과들을 기록해주는 기록용 메타 데이터베이스
•
Scheduler와 각 DAG들의 실행 결과가 메타 DB에 기록됨
5.
Queue
•
여러 개의 태스크를 여러 워커에 분산 처리하기 위해 필요
•
하나의 Worker만 사용하는 경우, 더 많은 DAG를 실행할 때 제약이 있음. 이 때 Worker(서버, 노드)를 추가하는데, 태스크가 어느 워커에서 실행될지 미리 알 수는 없기 때문에 Queue를 통해 비동기적으로 처리하게 됨.
•
Executor에 따라 사용하는 큐가 달라짐 (CeleryExecuter , KubernetesExecutor)
Airflow Scheduler가 작업을 진행하는 과정
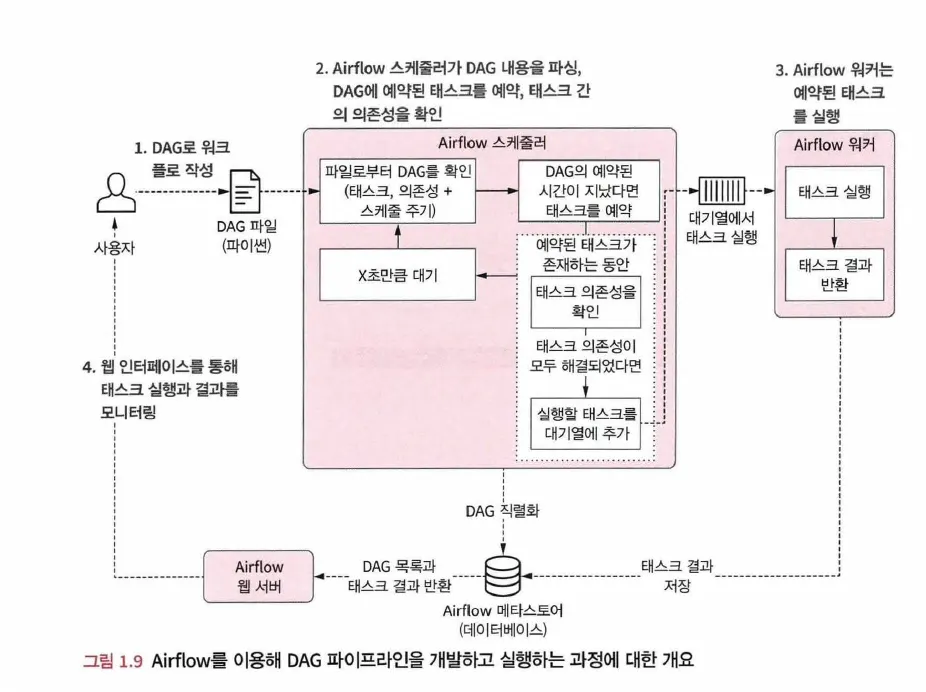
1.
사용자가 DAG 코드를 작성하면, 스케줄러는 DAG 파일을 파싱하고 각 태스크, 의존성 및 예약 주기를 확인
2.
스케줄러는 모든 DAG 파일을 파싱한 후, DAG의 예약 주기가 경과했는지 확인. 예약 주기가 현재 시간 이전이라면 실행되도록 예약
3.
예약된 각 태스크에 대해 스케줄러는 해당 태스크의 의존성(Upstream 태스크)을 확인. 의존성 태스크 완료되지 않았다면 실행 대기열에 추가
a.
여러 개의 Worker가 병렬로 Queue의 태스크를 선택해 실행하고, 실행 결과는 메타 데이터베이스에 저장됨
4.
스케줄러는 1단계로 다시 돌아간 후 새로운 루프를 잠시 대기
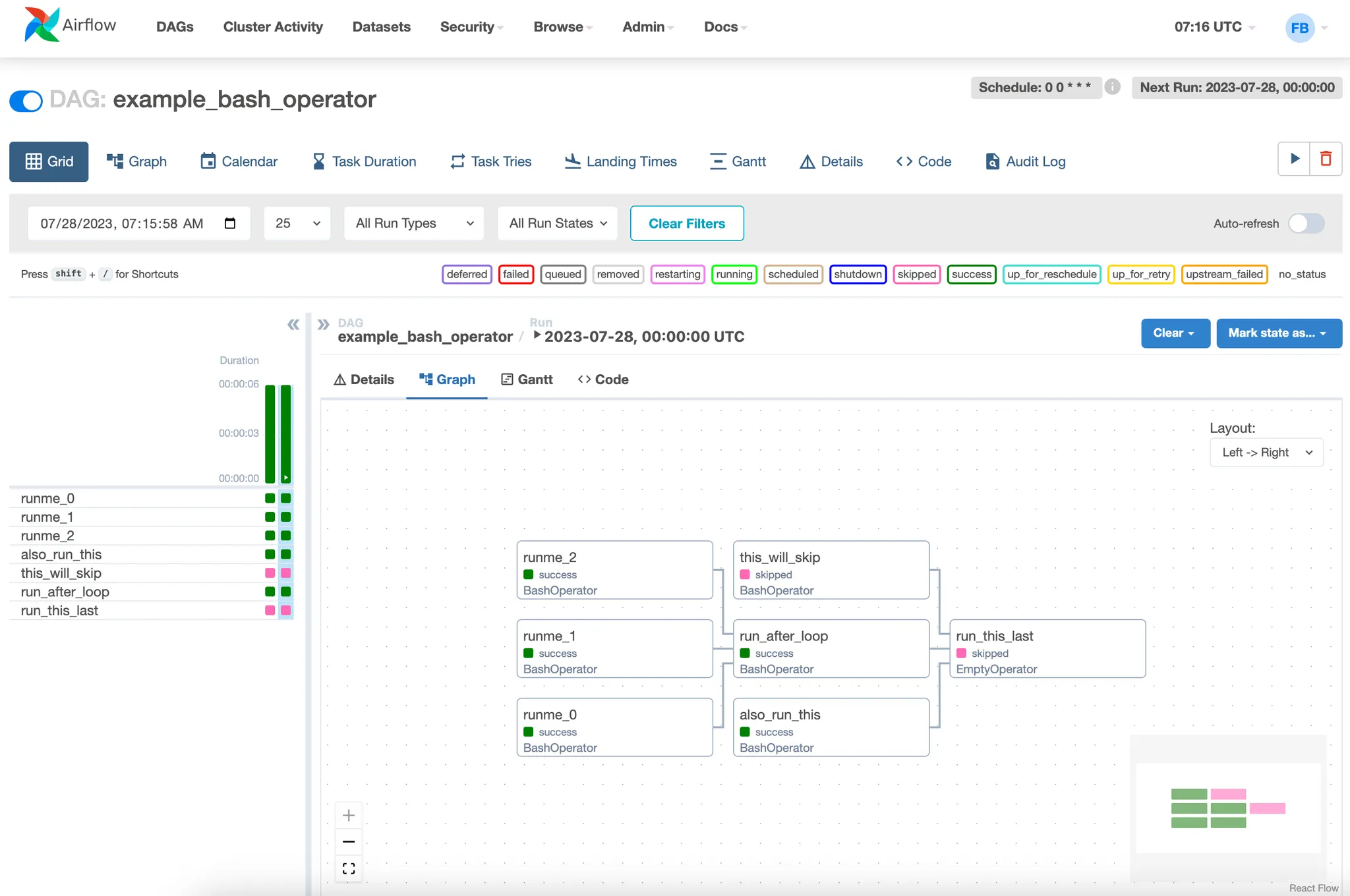
Airflow의 모니터링과 실패 처리
•
DAG 이름, 스케줄, 최근 실행된 태스크의 상태
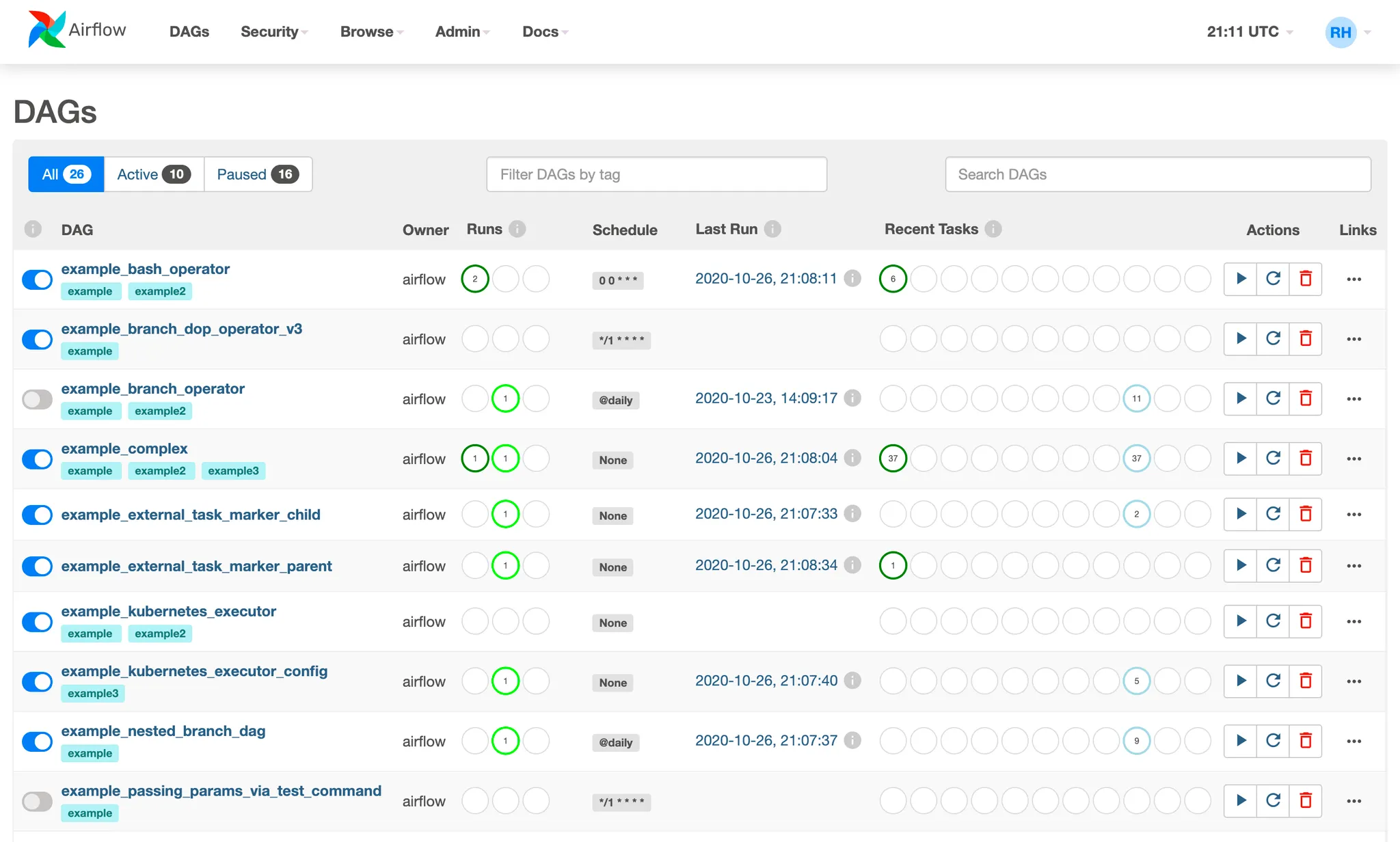
•
각 DAG의 태스크 목록과 의존성 그래프 (Graph View)

점진적 로딩 및 백필
Airflow 스케일링 방법
•
데이터 파이프라인의 처리량, 처리 속도에 한계가 올 경우, 스케일 업 또는 스케일 아웃을 선택해야 함
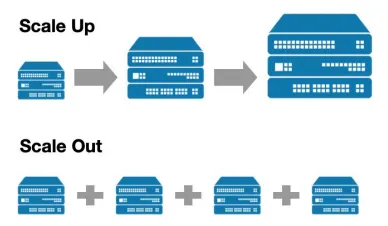
•
스케일 업 (더 좋은 사양의 서버 사용)
◦
동일한 노드 개수로 서버 사양을 올리기
◦
하나의 노드가 더 많은 태스크를 수행할 수 있게 하지만, 언젠가는 한계에 도달
•
스케일 아웃 (서버 추가)
◦
노드의 개수를 증가
◦
거의 무한히 늘릴 수 있지만, 단점도 존재함
▪
서버의 사양을 높일 때, 노드의 개수를 늘릴 때보다 비용이 저렴할 수 있음
▪
노드 관리 비용과 운영 비용이 있는 만큼, Airflow를 Managed로 제공해주는 클라우드 서비스를 사용하는 것도 좋음 (ex. AWS MWAA, GCP Cloud Composer)
•
Airflow를 한 개의 서버에서:
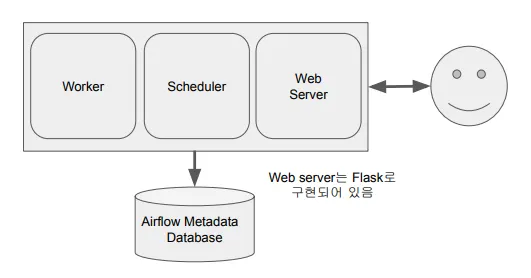
◦
Master 1 + Worker 1
◦
하나의 서버가 가진 CPU, Memory 한계로 인한 처리량과 처리 속도의 한계
•
Airflow를 여러 개의 서버에서:
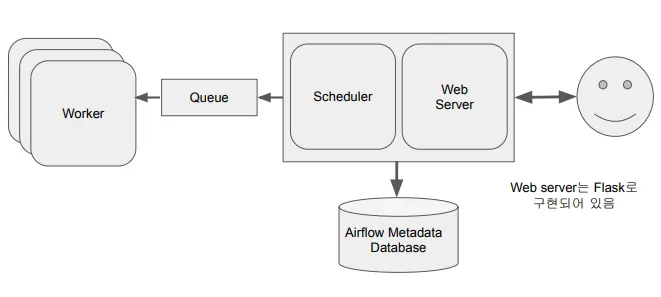
◦
Master 1 + Worker n
◦
마스터 노드의 Executor와 워커 노드는 Queue를 통해 통신함 (Executor에 따라 Queue를 사용하지 않을 수도 있음)
◦
처리 성능의 Bottleneck은 Worker에 존재하므로, 마스터 노드 외의 서버들을 워커 전용으로 모두 할당
•
Airflow 구조 다시 보기
잠깐! Airflow Executor는 무엇?
•
Executor는 Task들을 관리하고 실행하는 역할을 수행
◦
병렬 혹은 일렬 실행이나 어느 워커에서 실행할 지 등등
•
다양한 수의 Executor 타입이 존재
◦
Sequential Executor: 디폴트로 설치되며 SQLite에서 사용 가능
◦
Local Executor: Task를 Airflow 마스터 노드 안에서 실행
◦
Celery Executor: 다수의 Worker 노드가 있는 경우 사용되며 Celery 큐를 사용해 Task들을 Worker 노드로 분산하여 실행
◦
Kubernetes Executor: K8s 클러스터를 사용하여 태스크들을 독립된 환경(Pod)에서 사용
◦
Local Kubernetes Executor와 Celery Kubernetes Executor도 존재




Airflow의 장단점
•
장점
◦
데이터 파이프라인을 세밀하게 제어 가능
◦
다양한 데이터 소스와 데이터 웨어하우스를 지원하기 때문에 쉽게 확장 가능
◦
파이프라인 증분 (Incremental) 처리가 가능 → 재실행할 필요가 없는 효율적인 파이프라인 구축이 가능
◦
백필(Backfill)이 쉬움
◦
웹 인터페이스가 훌륭 → 실행 결과를 모니터링하기 좋고, 오류 디버깅도 편리함
•
단점
◦
배우기 쉽지 않음 ⇒ 러닝 커브가 존재
◦
개발 환경을 구성하기 어려움
◦
클러스터 노드의 경우, 복잡해서 직접 운영하기 어려움
Airflow가 적합하지 않은 사례
•
스트리밍(실시간 데이터 처리) 파이프라인에 적합하지 않을 수 있음
•
태스크의 변경이 잦은 동적 파이프라인의 경우에는 적합하지 않을 수 있음
◦
Airflow는 동적 태스크를 구현할 수 있지만, 웹 인터페이스는 DAG의 가장 최근 실행 버전에 대한 정의만 표현함
Reference

•