빅데이터 처리를 위한 오픈소스 고속 분산처리 엔진
Hadoop은
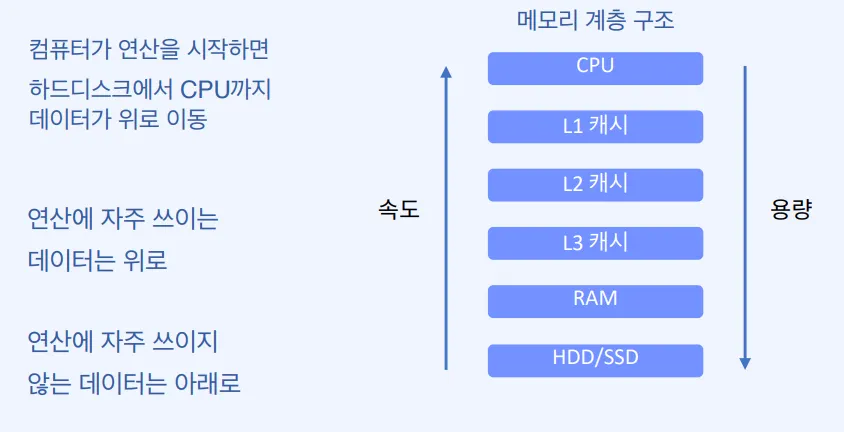
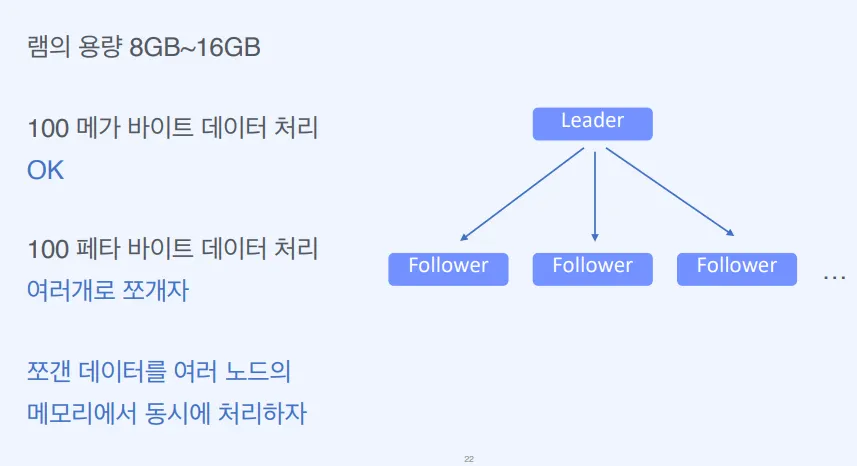
데이터의 용량이 커질수록 비용과 시간은 기하급수적으로 늘어난다. 따라서 대용량 데이터를 어떻게 처리할지에 대한 고민에서 디스크를 사용하는 것이 아니라, 위와 같이 쪼갠 데이터를 여러 노드의 메모리에서 동시에 처리하자는 인메모리 방식이 고안되었다.
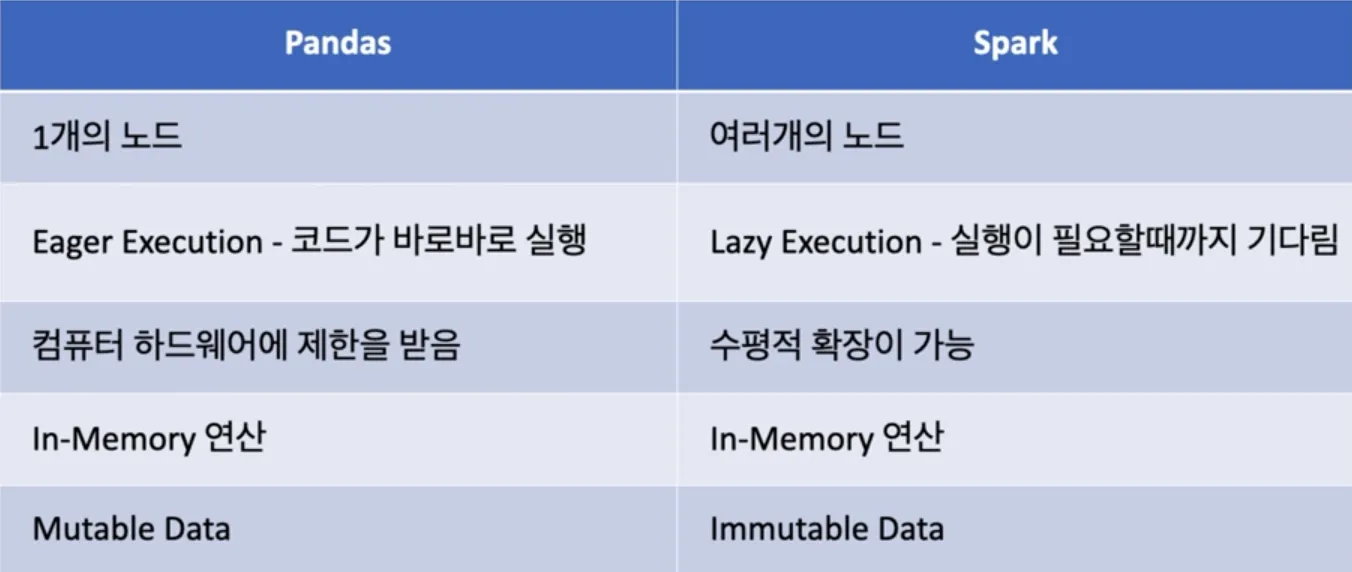
스파크는 이러한 In-Memory 연산을 사용해서 속도가 빠르다.
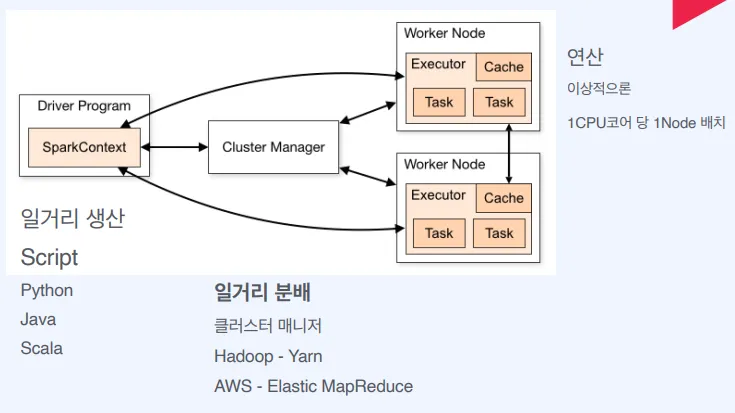
내 컴퓨터에서 Spark 프로그램을 돌리면 왜 판다스보다 느릴까?
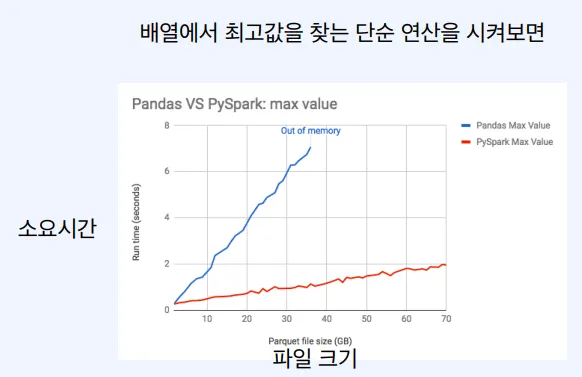
Spark는 파일 크기가 증가함에도 불구하고 계속해서 연산을 할 수 있음. → 수평적 확장이 가능함.
Hadoop MapReduce 보다 빠르다
•
메모리 상에선 100배
•
디스크 상에선 10배
Lazy Evaluation
•
태스크를 정의할때는 연산을 하지 않다가 결과가 필요할때 연산한다
•
기다리면서 연산 과정을 최적화 할 수 있다
스파크의 핵심 데이터 모델
Resilient Distributed Dataset (RDD)
•
여러 분산 노드에 걸쳐서 저장
•
변경이 불가능
•
여러개의 파티션으로 분리