카프카(Kafka)란?
→ 카프카(Kafka)는 파이프라인, 스트리밍 분석, 데이터 통합 및 미션 크리티컬 애플리케이션을 위해 설계된
고성능 분산 메시지 처리 및 이벤트 스트리밍 플랫폼

Publish - Subscribe 모델의 메시지 큐(MQ) 형태로 동작하며 분산환경에 특화되어 있다.
•
카프카는 대용량 데이터 처리, 실시간, 고성능, 고가용성 작업이 필요한 경우, 또는 저장된 이벤트를 기반으로 로그를 추적하고 재처리가 필요한 경우에 사용
Kafka 탄생 배경
Kafka 개발 이전 아키텍쳐
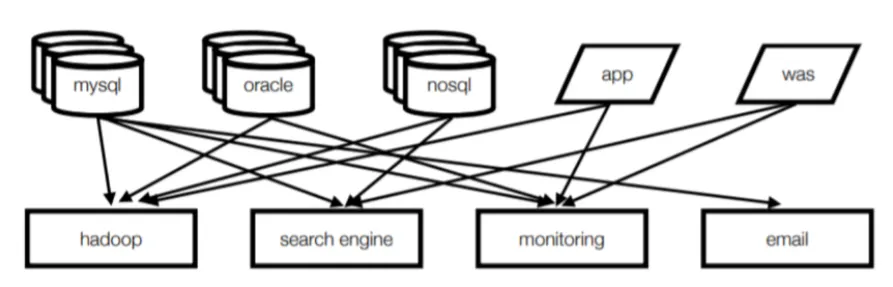
•
Point to Point 방식
•
데이터를 전송하는 소스 애플리케이션과 데이터를 받는 타겟 애플리케이션이 각각 직접적으로 연결
기존 데이터 시스템 문제점
1.
시스템 복잡도 증가
•
통합된 전송 영역이 없어 데이터 흐름을 파악하기 어렵고, 시스템 관리가 어려움
•
특정 부분에서 장애가 발생했을 때, 연결되어 있는 모든 애플리케이션들을 확인해야 하기 때문에 해결 조치에서 시간이 오래 걸림
2.
데이터 파이프라인 관리 어려움
•
각 애플리케이션과 데이터 시스템 간의 별도의 파이프라인이 존재하고, 파이프라인마다 데이터 포맷과 처리 방식이 전부 다름
•
새로운 파이프라인에 대한 확장이 어렵고, 확장성 및 유연성이 떨어짐
•
데이터 불일치 가능성이 존재하기 때문에 신뢰도 감소
이러한 문제들을 해결하기 위해 모든 이벤트와 데이터의 흐름을 중앙에서 관리하는 카프카(Kafka) 개발
Kafka 개발 이후 아키텍쳐
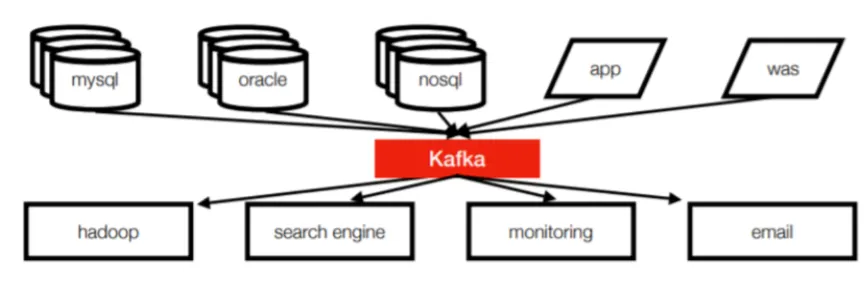
•
Pubilsh - Subscribe 방식 (단방향 통신 구조)
•
소스 앱은 카프카에 데이터를 보내기만하면 되고, 타겟 앱은 필요한 데이터를 카프카에서 읽어오면 됨
•
모든 이벤트와 데이터의 흐름을 중앙에서 관리할 수 있게 됨
•
새로운 서비스나 시스템이 추가돼도 카프카가 제공하는 표준 포맷으로 연결하면 데이터의 손실 없이 진행이 되므로 확장성과 신뢰성 증가
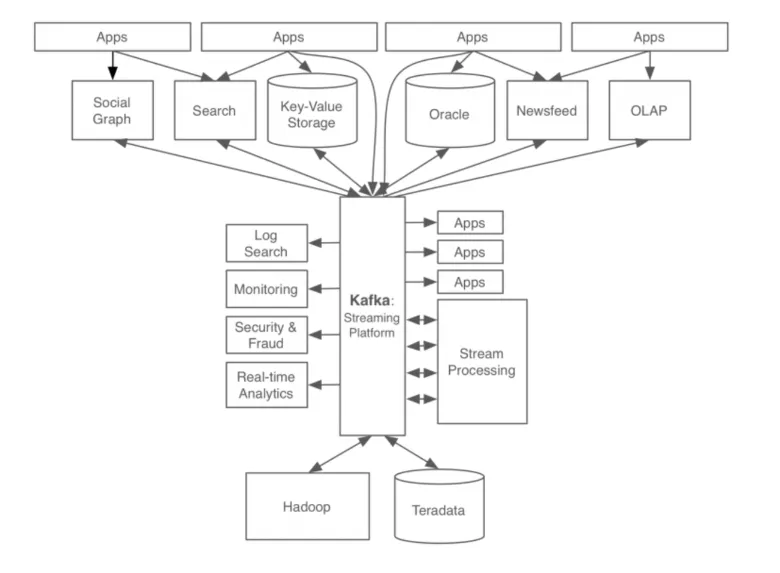
Kafka 구성요소
Kafka 전체 구조도
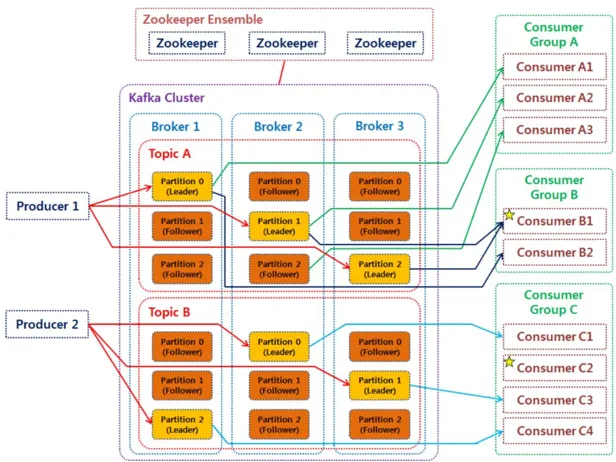
토픽(Topic)

•
카프카에서 메시지를 구분하는 단위 (DB 테이블 또는 파일 시스템의 폴더와 유사)
•
여러 개의 토픽이 생산 가능하며 각 토픽마다 이름을 다르게 설정할 수 있음
•
하나의 토픽은 보통 여러개의 파티션(Partition)으로 구성되어 있음
파티션(Partition)
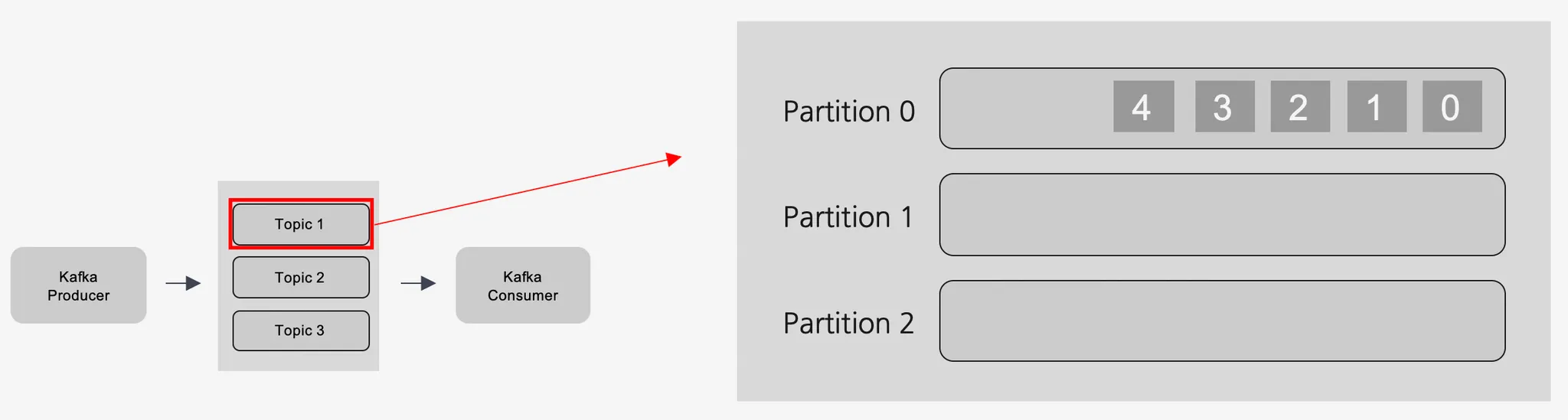
•
주로 분산 처리를 위해 사용
•
토픽(Topic) 생성 시 파티션 개수를 지정할 수 있다. (단, 추가만 가능함)
•
파티션 내부에서 데이터는 큐와 같이 끝에서부터 차곡차곡 들어감
•
파티션 내부에서 각 데이터(메시지)는 offset(고유 번호)로 구분됨
•
파티션이 한개일 때는 모든 데이터에 대해 순서가 보장됨
•
파티션이 한개가 아닌 여러개일 때 데이터 전송 방식 종류 (순서 보장 X)
◦
key 값이 존재하는 경우: key 값의 hash 값을 이용해 할당
◦
key 값이 존재하지 않는 경우: Round-Robin 방식으로 할당
•
파티션이 많을수록 처리량은 좋지만 장애 복구 시간이 그만큼 늘어나기 때문에 신중하게 결정해야 함
오프셋(Offset)이란?
→ 컨슈머에서 메시지를 어디까지 읽었는지 저장하는 값을 나타냄. 컨슈머 그룹의 컨슈머들은 각각의 파티션에 자신이 가져간 메시지의 위치 정보(offset)을 기록함. 그러므로, 컨슈머 장애가 발생한 후 재실행했을 때 마지막으로 읽었던 위치에서부터 다시 읽어들일 수 있다. 일종의 세이브 포인트라고 생각하면 이해가 쉬울 것이다.
Round-Robin 방식이란?
→ Round-Robin 방식은 간단하고 공정한 스케줄링 기법으로서, 다수의 작업을 공평하게 처리해야 하는 경우에 효과적으로 사용된다. 그러나 실행 시간이 다른 작업들이 혼재하거나, 빠른 응답이 필요한 시스템에는 다른 스케줄링 방식을 고려해야 할 수 있다.
브로커(Broker)
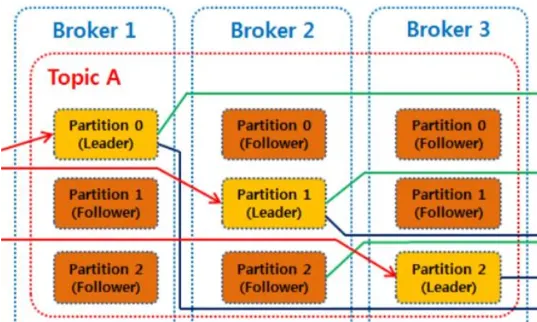
•
실행된 카프카 서버를 의미: 브로커 안에 데이터를 담는 토픽이 들어간다고 생각하면 됨
•
서버 내부에 메시지를 저장하고 관리하는 역할을 수행함
•
보통 3대 이상의 브로커로 카프카 클러스터를 구성하는 것을 권장
•
N개의 브로커 중 1대는 컨트롤러(Controller) 기능을 수행함
◦
각 브로커에게 담당 파티션을 할당함
◦
브로커가 정상적으로 동작하는지 모니터링함
브로커(Broker) - 토픽 레플리케이션(Topic Replication)
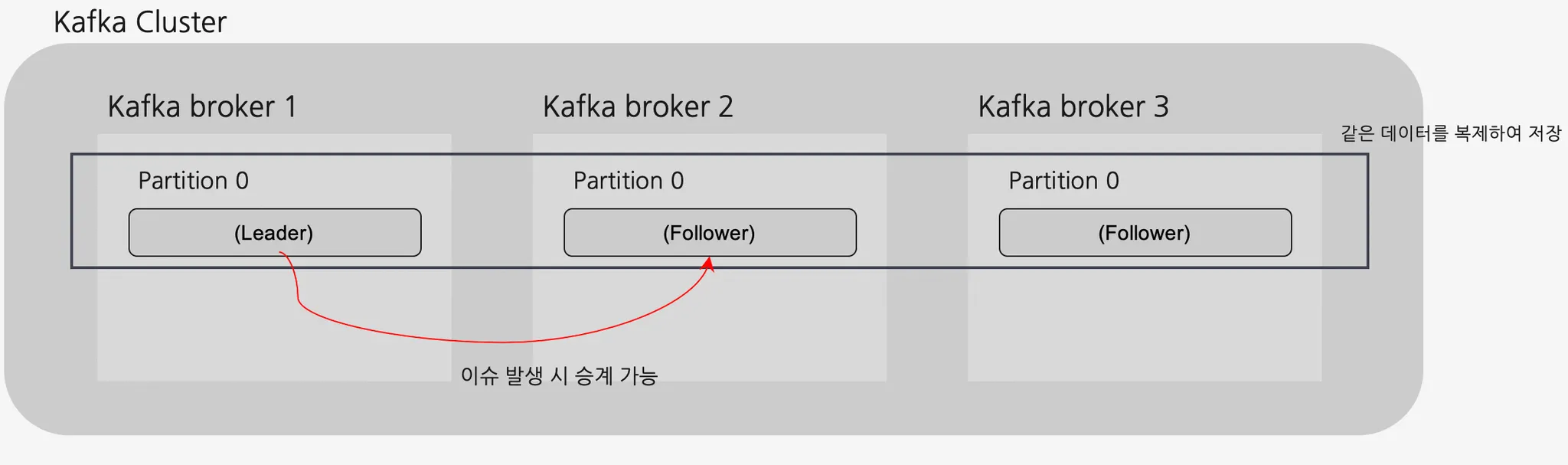
•
여러 대의 브로커를 설정하여 동일한 데이터를 복제해서 각각 저장하는 레플레케이션(replication)을 사용할 수 있음
•
원본 파티션 = 리더(Leader) 파티션, 복제 파티션 = 팔로워(Follower) 파티션이라 한다
•
리더 파티션과 팔로워 파티션을 합쳐 ISR(In Sync Replica)라고 부른다
•
브로커가 갑자기 사용불가하게 되더라도, 복제된 다른 팔로워 파티션을 통해 기능을 정상적으로 수행 가능
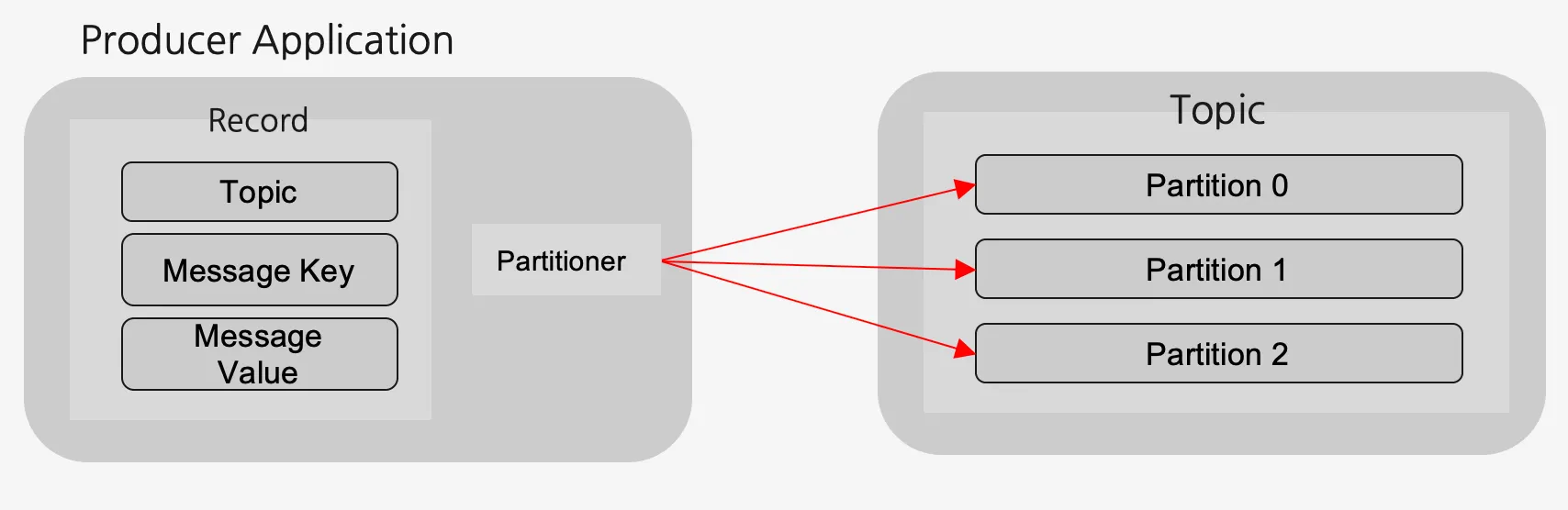
프로듀서(Producer)
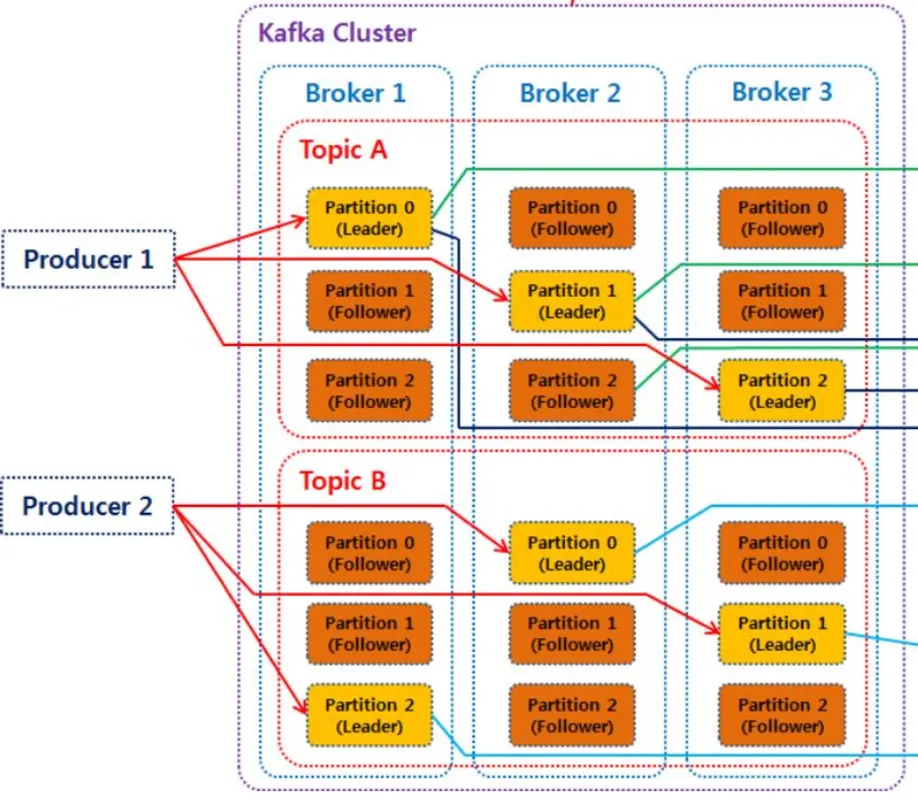
•
데이터를 토픽에 생성하는 역할을 수행
•
메시지 전송 시 Batch 처리가 가능함
•
메시지의 키 값을 설정하여 특정 토픽에 보낼 수 있음
•
반드시 파티셔너(Partitioner)를 통해 브로커로 데이터 전송
◦
파티셔너: 데이터를 토픽의 어떤 파티션 내에 넣을지 결정하는 역할 수행
▪
Key 값 가진 경우: 레코드는 특정한 해쉬값으로 생성되어 그 값을 기준으로 할당 (특정 파티션)
▪
Key 값 없는 경우: Round-Robin 방식으로 파티션에 할당
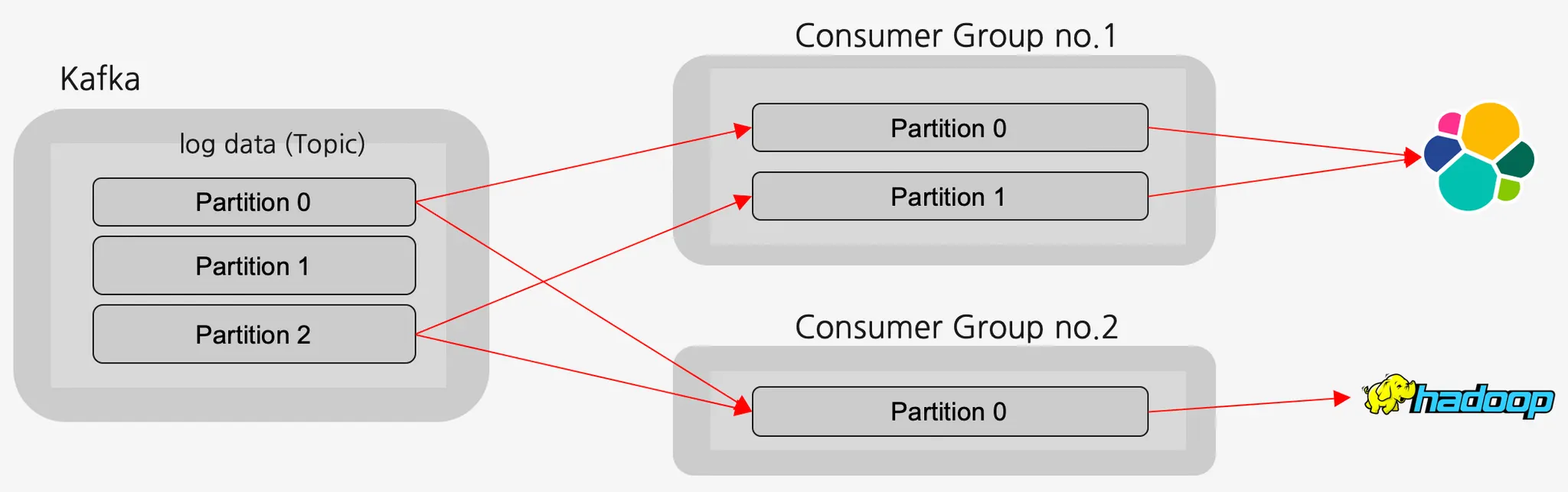
컨슈머(Consumer)
•
토픽에서 데이터를 가져오는 역할 수행 → 폴링(polling)이라고 함
•
한 개의 컨슈머는 여러 개의 토픽을 처리할 수 있음
•
토픽에서 데이터를 가져가더라도 데이터를 삭제하지 않는다. (삭제는 Kafka delete policy에 의해 진행)
◦
한 번 저장된 데이터를 여러번 소비하는 것이 가능함
•
컨슈머는 여러 개 만들 수 있으며, 컨슈머 그룹(Consumer Group)으로 묶어 관리할 수 있음
컨슈머 그룹을 사용하는 이유
→ 어떤 consumer에서 오류가 발생한다면, 파티션 재조정(리밸런싱)을 통해 다른 컨슈머가 해당 파티션의 sub을 맡아서 한다. 오프셋 정보를 그룹간에 공유하고 있기 때문에 오류가 발생하기 전 마지막으로 읽었던 데이터 위치부터 시작한다
•
그룹에 속하는 컨슈머가 여러 개이면 로드밸런싱을 통해 데이터 분배 가능
•
컨슈머 그룹들끼리는 서로 영향을 미치지 않음 (토픽 안에 있는 데이터 변경 X)
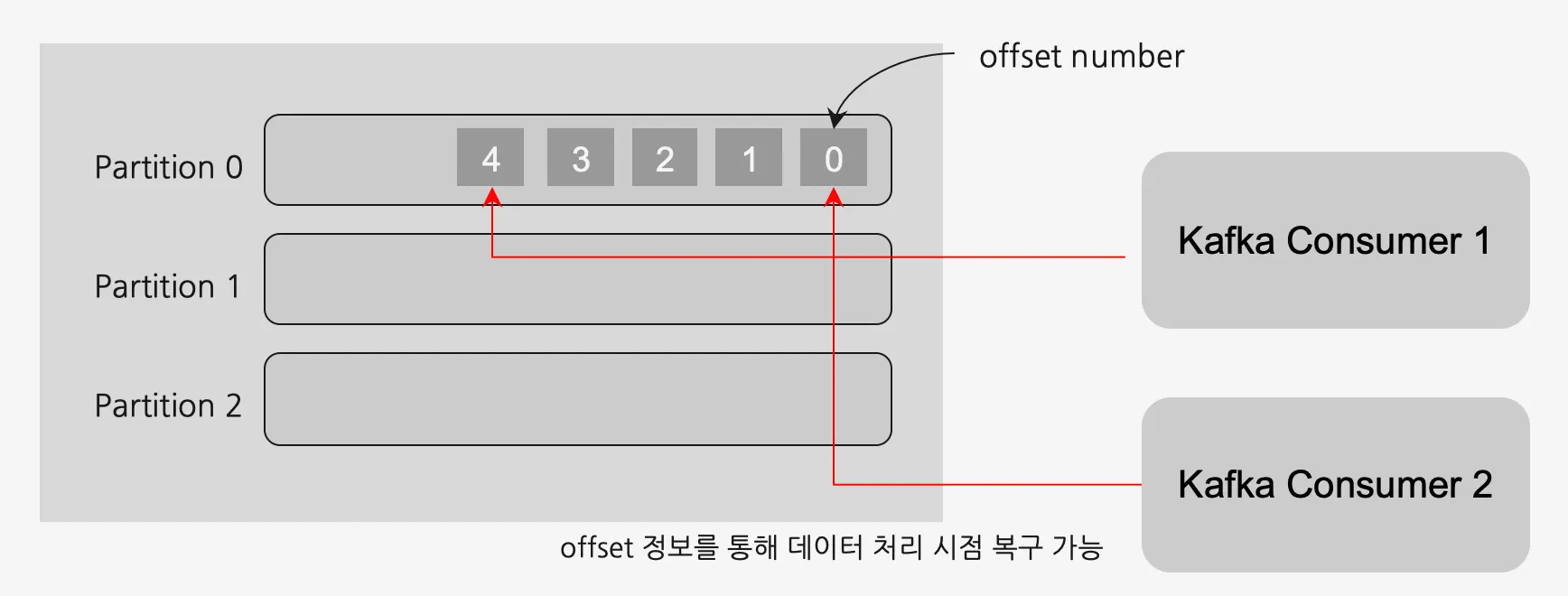
컨슈머(Consumer) - 오프셋 커밋(offset Commit)
•
컨슈머들은 파티션에 자신이 가져간 데이터의 오프셋(고유번호)을 기록함
◦
오프셋은 토픽별로 그리고 파티션 별로 별개로 지정
•
각 파티션 내 데이터들에 대해 어디까지 읽었는지 업데이트하는 동작을 커밋(Commit)이라고 함
•
컨슈머가 갑자기 동작이 중지되어도 이 오프셋 정보를 통해 데이터 처리 시점을 복구할 수 있음
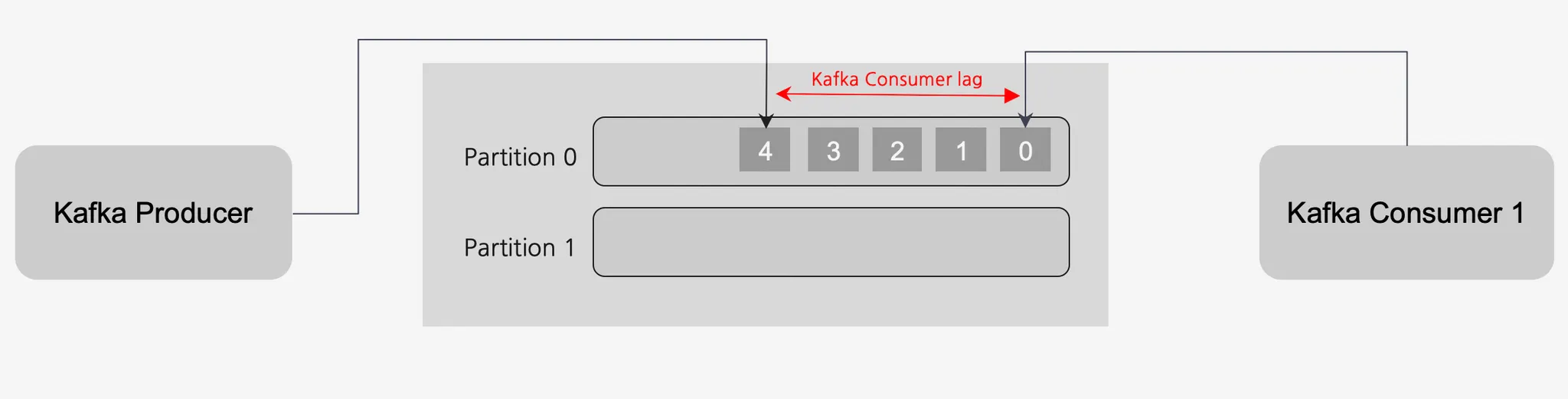
컨슈머(Consumer) - 컨슈머 랙(Consumer Lag)
•
프로듀서가 넣은 데이터의 오프셋과 컨슈머가 마지막으로 읽은 오프셋 간의 차이를 컨슈머 랙(Lag)이라고 함
◦
컨슈머의 기능이 저하되거나 비정상동작을 하는 경우 발생



