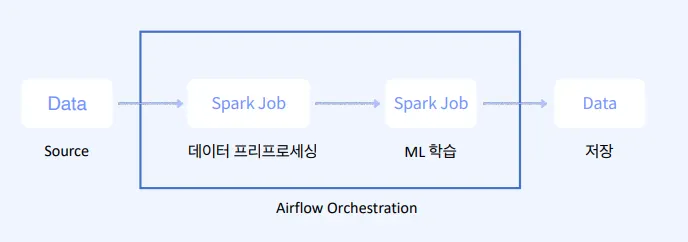
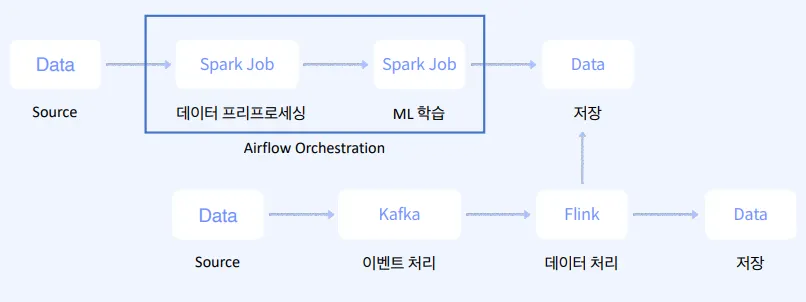
배치 프로세싱이란
배치(Batch) == 일괄
배치 프로세싱 (Batch Processing) == 일괄 처리
많은 양의 데이터를 정해진 시간에 한꺼번에 처리하는 것
1.
한정된 대량의 데이터
2.
특정 시간
3.
일괄 처리
전통적으로 쓰이는 데이터 처리 방법
배치 프로세싱은 언제 쓰는가
1.
실시간성을 보장하지 않아도 될 때
2.
데이터를 한꺼번에 처리할 수 있을때
3.
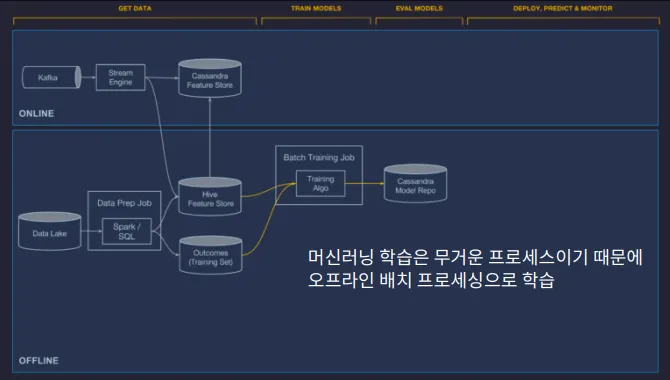
무거운 처리를 할때 (예 ML 학습)
ex)
1.
매일 다음 14일의 수요와 공급을 예측
2.
매주 사이트에서 관심을 보인 유저들에게 마케팅 이메일 전송
3.
매주 발행하는 뉴스레터
4.
매주 새로운 데이터로 머신러닝 알고리즘 학습
5.
매일 아침 웹 스크래핑/크롤링
6.
매달 월급 지급
기술 스택 : Quartz, Spring Batch, Airflow, Spark
스트림 프로세싱이란
실시간으로 쏟아지는 데이터를 계속 처리하는 것
이벤트가 생길때마다, 데이터가 들어올때마다 처리
배치 프로세싱은 배치당 처리하는 데이터 수가 달라지면서 리소스를 비효율적으로 사용하게 된다.
그에 비해 스트림은 데이터가 생성되어 요청이 들어올때마다 처리하기에 더 효율적.
1.
실시간성을 보장해야 될 때
2.
데이터가 여러 소스로부터 들어올때
3.
데이터가 가끔 들어오거나 지속적으로 들어올때
4.
가벼운 처리를 할때 (Rule-based)
ex)
1.
사기 거래 탐지 (Fraud Detection)
2.
이상 탐지 (Anomaly Detection)
3.
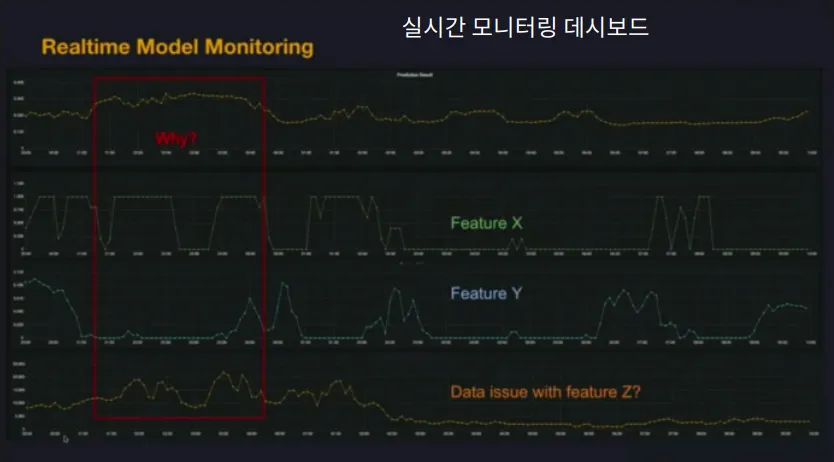
실시간 알림
4.
비즈니스 모니터링
5.
실시간 수요/공급 측정및 가격책정
6.
실시간 기능이 들어가는 어플리케이션
기술스택 : 일반 서버 어플리케이션, Storm, Flink, Spark Streaming
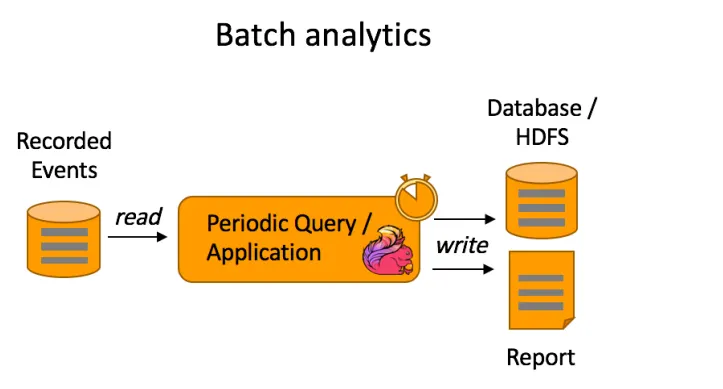
일반적인 배치 처리 플로우
1.
데이터를 모아서
2.
데이터베이스에서 읽어서 처리
3.
다시 데이터베이스에 담기
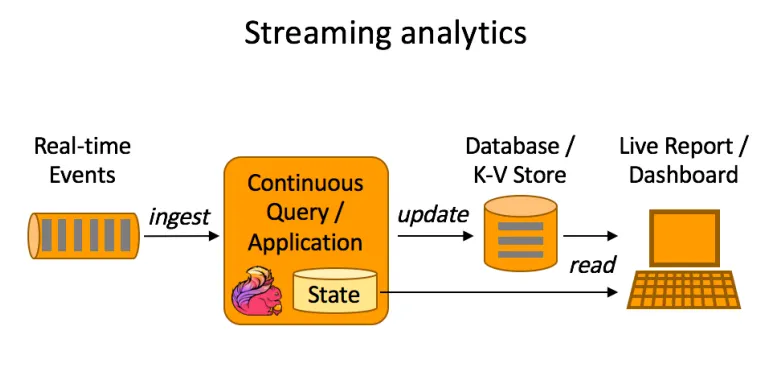
일반적인 스트림 처리 플로우
1.
데이터가 들어올때마다 (ingest)
2.
쿼리/처리 후 State를 업데이트
3.
DB에 담기
마이크로 배치(Micro-Batch)
데이터를 조금씩 모아서 프로세싱하는 방식.
Batch 프로세싱을 잘게 쪼개서 스트리밍을 흉내내는 방식.
Spark가 이러한 방식을 사용함.
실 서비스 활용 예시
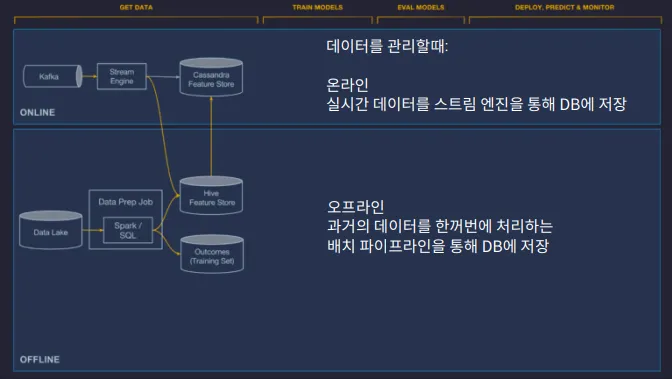
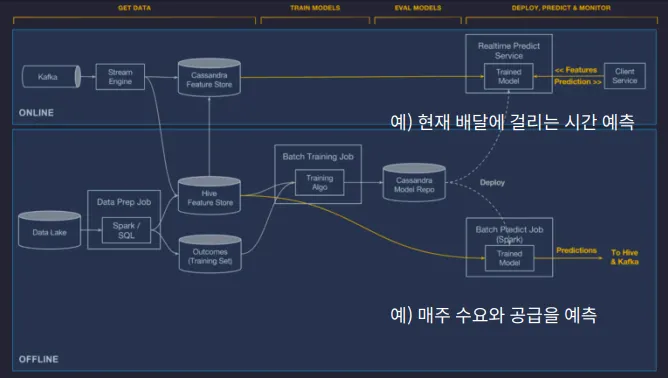
배치와 스트림을 적절히 섞은 예 : 미켈란젤로

우버 내부 툴로서, 우버 내부에서 배달에 걸리는 시간 등을 예측하는데 사용함.
크게 두가지 파트로 나누어서 설계되었는데,
•
온라인
1.
실시간 예측을 위한 부분
2.
지금의 데이터를 처리
3.
데이터가 무한이라고 가정
•
오프라인
1.
실시간이 아니어도 되는 부분
2.
과거의 데이터를 처리
3.
데이터가 한정적이라고 가정