
Spark ML
스파크의 여러 컴포넌트
•
Spark SQL
•
Spark Streaming
•
MLlib
•
GraphX 등등..
MLlib(Machine Learing Library)은 ML을 쉽고 확장성 있게 적용하기 위해,
머신러닝 파이프라인 개발을 쉽게 하기 위해 만들어졌다.
Machine Learning 이란?
•
데이터를 이용해 코딩을 하는 일
•
최적화와 같은 방법을 통해 패턴을 찾는 일
머신러닝 파이프라인 구성
데이터 로딩 → 전처리 → 학습 → 모델 평가
MLlib은 DataFrame위에서 동작
아직 RDD API가 있지만 maintenance mode이며, 새로운 API는 개발 끊김.
DataFrame을 쓰는 MLlib API를 Spark ML이라고도 부름.
SparkML을 사용하는 이유
다른 라이브러리에 비해 스파크는 대중적으로 사용되는 몇몇 알고리즘만 구현되어 있다.
→ 새롭거나 핫한 모델이 나와도 스파크에서 쓰려면 다른 라이브러리보다는 조금 더 기다려야 한다는 단점은 존재.
그럼 SparkML을 왜 쓰는걸까? 대량의 데이터를 처리하는데 매우 적합하기 때문.
스파크는 데이터를 인메모리 상에서 처리. 데이터를 메모리에 올려서 처리하면 디스크를 사용하는 맵리듀스나 머하웃보다 10배에서 100배까지 빠른 결과를 얻어낼 수 있다.

학습에 필요한 전처리를 스파크로 진행하고 모델링은 텐서플로우와 같은 타 라이브러리로 진행하거나, 스파크 지원 모델로 충분한 프로젝트라면 모델링까지 스파크로 마무리하여 작업의 속도를 높일 수 있다.
MLlib 컴포넌트
•
알고리즘
◦
Classification
◦
Regression
◦
Clustering
◦
Recommendation
•
파이프라인
◦
Training
◦
Evaluating
◦
Tuning
◦
Persistence
•
Feature Engineering
◦
Extraction
◦
Transformation
•
Utils
◦
Linear algebra
◦
Statistics
주요 컴포넌트 소개
•
DataFrame
◦
ML파이프라인에서는 데이터프레임이 기본 포맷이며, 테스트셋을 로딩하기 위해 기본적으로 csv, JSON, Parquet, JDBC를 지원. ML 파이프라인에서 다음 2가지의 새로운 데이터소스를 추가 지원함.
◦
이미지 데이터소스
▪
jpeg, png 등의 이미지들을 지정된 디렉토리에서 로드
◦
LIBSVM 데이터소스
▪
label과 features 두 개의 컬럼으로 구성되는 머신러닝 트레이닝 포맷
▪
features 컬럼은 벡터 형태의 구조
•
Transformer
◦
피쳐 변환과 학습된 모델을 추상화
◦
모든 Transformer는 transform() 함수를 가지고 있음.
◦
데이터를 학습이 가능한 포맷으로 바꿈.
◦
DF를 받아 새로운 DF를 만드는데, 보통 하나 이상의 column을 더하게 된다.
◦
ex) Data Normalization, Tokenization, 카테고리컬 데이터를 숫자로 (one-hot encoding)
•
Estimator
◦
모델의 학습 과정을 추상화
◦
모든 Estimator는 fit() 함수를 가지고 있음.
◦
fit()은 DataFrame을 받아 Model을 반환
◦
모델은 하나의 Transformer
ex)
lr = LinearRegression()
model = lr.fit(data)
•
Evaluator
◦
metric을 기반으로 모델의 성능을 평가
ex) Root mean squared error (RMSE)
◦
모델을 여러개 만들어서, 성능을 평가 후 가장 좋은 모델을 뽑는 방식으로 모델 튜닝을 자동화 가능.
ex) BinaryClassificationEvaluator, CrossValidator
•
Pipeline
◦
ML의 워크플로우
◦
여러 stage를 담고 있음 Pipeline(stages=).
◦
저장될 수 있음 (persist)
◦
Transformer → Estimator → Evaluator → Model
ML Pipeline은 결국 하나 이상의 Transformer와 Estimator가 연결된 모델링 워크플로우로, 입력은 데이터프레임이고 출력은 머신러닝 모델인 것이다.
ML Pipeline 그 자체도 Estimator이므로 실행은 fit함수의 호출로 시작할 수 있으며, 저장했다가 다시 로딩하는 것이 가능해 한번 파이프라인을 만들어두면 반복적인 모델 빌딩이 쉬워진다.
•
Parameter
◦
Transformer와 Estimator의 공통 API로 다양한 인자를 적용해줌.
◦
Param(하나의 이름과 값)과 ParamMap(Param 리스트) 두 종류의 파라미터가 존재.
◦
파라미터는 fit (Estimator) 혹은 transform (Transformer)에 인자로 지정 가능.
Spark ML 피쳐변환
•
Feature Transformer가 하는 일
◦
기본적으로 머신러닝에서 모든 피쳐 값들은 숫자 필드이어야 하므로 텍스트 필드(카테고리 값들)를 숫자 필드로 변환
◦
숫자 필드라고 해도 가능한 값의 범위를 특정 범위(0부터 1)로 변환하는 표준화가 필요, 이를 피쳐 스케일링(Scaling) 혹은 정규화(Normalization)라고 함.
•
Feature Extractor가 하는 일
◦
기존 피쳐에서 새로운 피쳐를 추출
◦
TF-IDF, Word2Vec 등
◦
텍스트 데이터를 어떤 형태로 인코딩하는 것이 여기에 해당
•
StringIndexer: 텍스트 카테고리를 숫자로 변환
◦
Scikit-Learn은 sklearn.preprocessing 모듈 아래 여러 인코더(OneHotEncoder, LabelEncoder, OrdinalEncoder 등) 존재
◦
Spark MLlib의 경우 pyspark.ml.feature 모듈 밑에 두 개의 인코더 존재
◦
StringIndexer, OneHotEncoder
◦
사용법은 Indexer 모델을 만들고(fit), Indexter 모델로 데이터프레임을 변환(Transform)
•
Scaler: 숫자 필드 값의 범위를 0과 1사이로 표준화
◦
pyspark.ml.feature 모듈 밑에 두 개의 스케일러 존재
◦
StandardScaler: 각 값에서 평균을 빼고 이를 표준편차로 나눔. 값의 분포가 정규분포를 따르는 경우 사용
◦
MinMaxScaler: 모든 값을 0과 1사이로 스케일링. 각 값에서 최솟값을 빼고 (최댓값-최솟값)으로 나눔
•
Imputer: 값이 없는 필드 채우기
◦
값이 존재하지 않는 레코드들이 존재하는 필드들의 경우 기본값(평균값, 중앙값 등)을 정해 채움
추천 모델
유저별 영화 추천 파이프라인
•
ALS: Alternating Least Squares
추천 알고리즘 중 하나로, 교대 최소 제곱법이라고도 부른다.
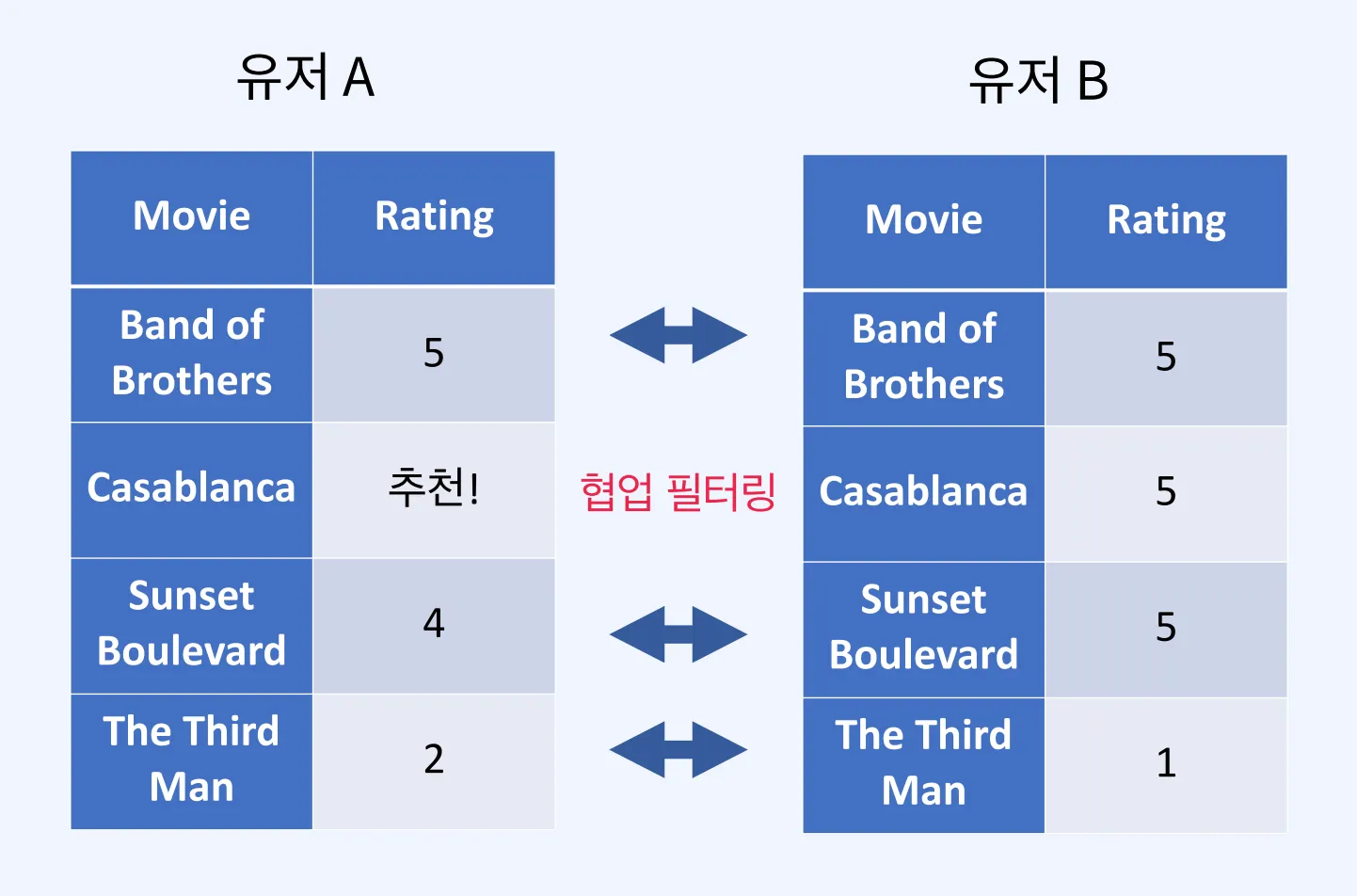
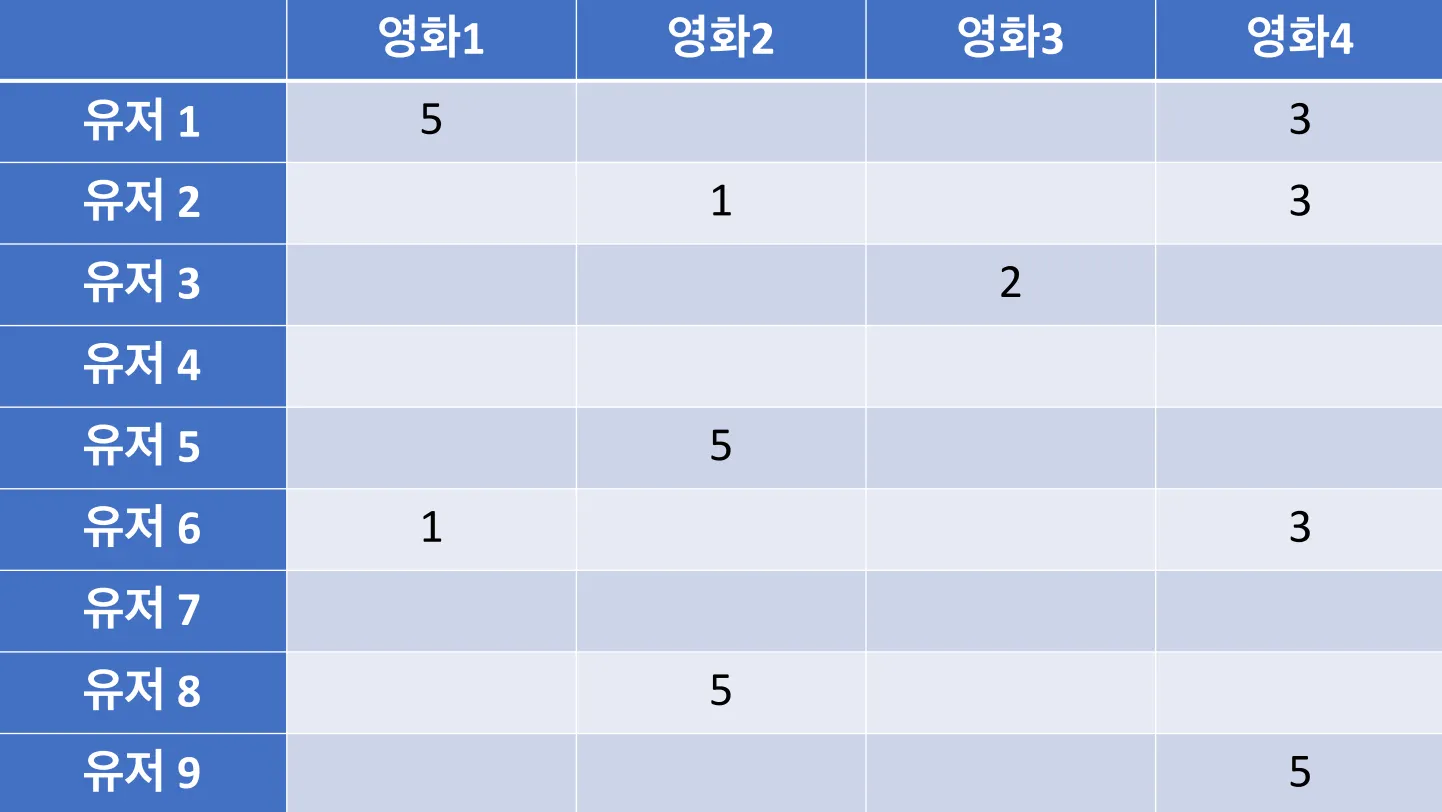
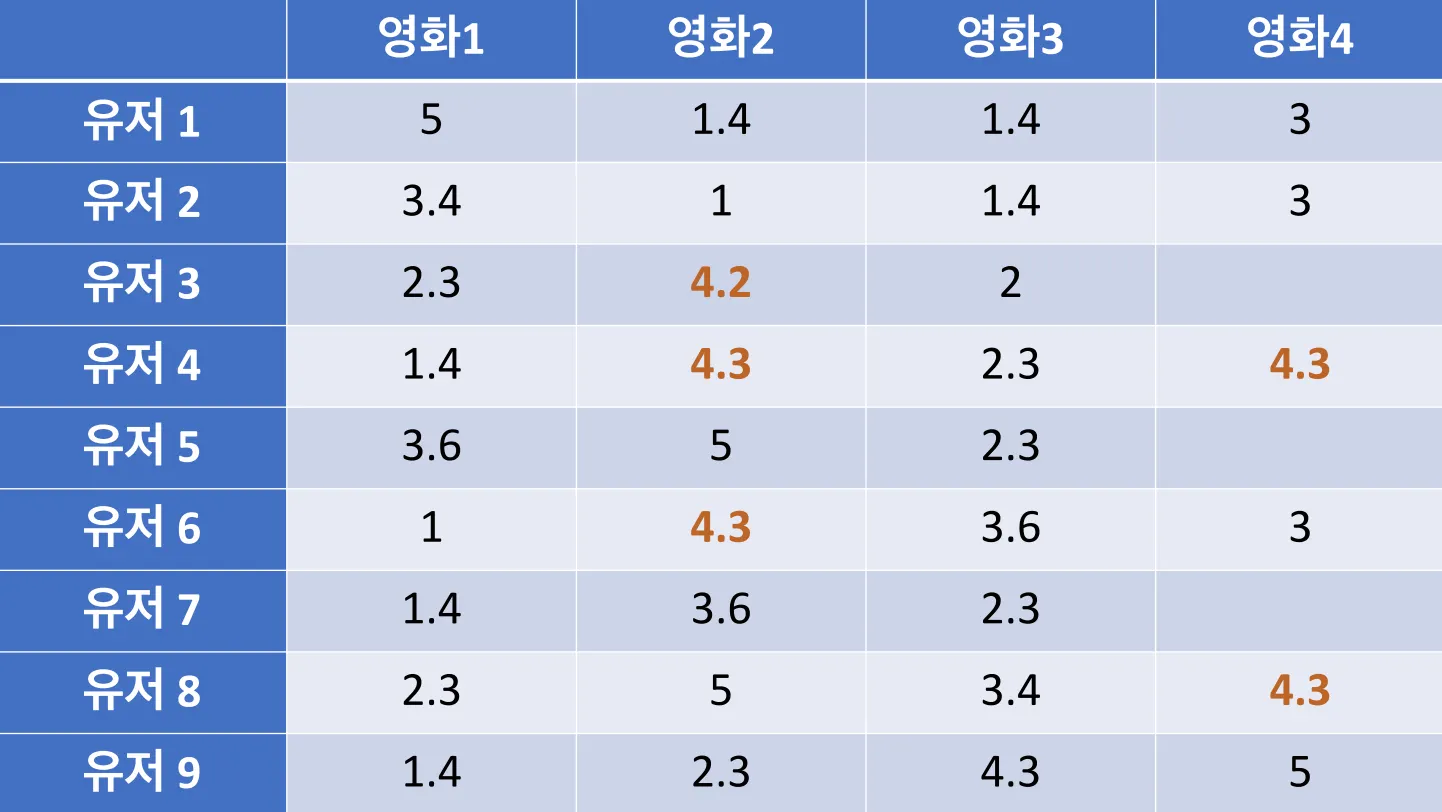
한 유저가 볼 수 있는 영화가 너무 많기에, 못본 영화들의 평점을 예측하고 가장 높은 점수부터 유저에게 전달하는 것이 바로 추천이다.
ALS란 두 행렬 중 하나를 고정시키고 다른 하나의 행렬을 순차적으로 반복하면서 최적화하는 방식이다.
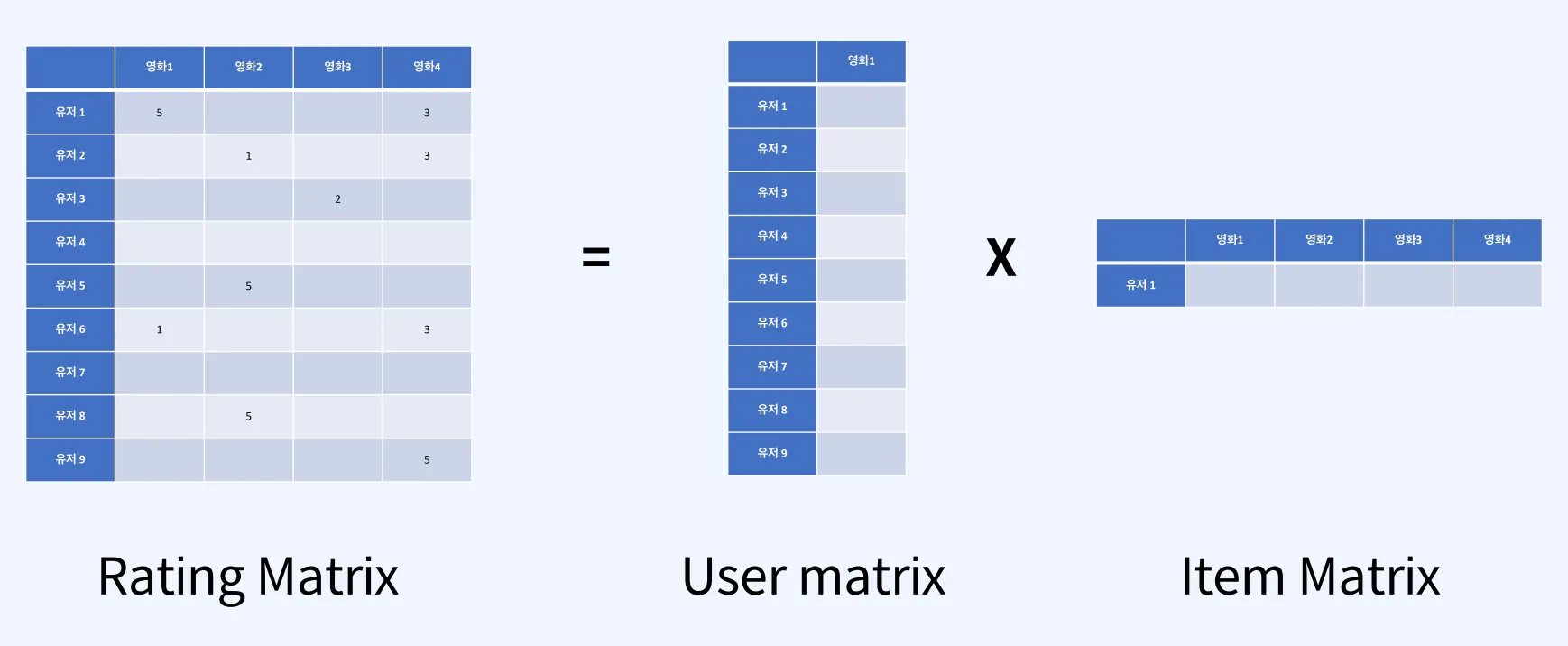
예측 모델
거리별 택시비 예측하기
•
Linear Regression (선형 회귀)
종속변수 y와 한 개 이상의 독립변수 x에 대한 선형 상관 관계를 모델링하는 회귀 분석 방법.
위와 같이 데이터가 분포되어있을 때, 데이터의 분포가 가장 잘 맞는 선을 긋는 것(최적화).
•
RMSE(Root Mean Squared Error)
예측 모델에서 예측한 값과 실제 값 사이의 평균 차이를 측정한다.
예측 모델이 목표 값(정확도)을 얼마나 잘 예측할 수 있는지 추정한다.
실습 코드
영화 추천 파이프라인
git clone https://github.com/Y-gw/boaz-sparkML.git
Shell
복사
파일 만들기
docker pull jupyter/all-spark-notebook
docker run -p 8888:8888 -e JUPYTER_ENABLE_LAB=yes -v {LOCAL_PATH}:/home/jovyan --name jupyter jupyter/all-spark-notebook
Shell
복사
token 복사
http://localhost:8888/
Shell
복사
접속
•
DF 구조
+------+-------+------+----------+
|userId|movieId|rating| timestamp|
+------+-------+------+----------+
| 1| 296| 5.0|1147880044|
| 1| 306| 3.5|1147868817|
| 1| 307| 5.0|1147868828|
| 1| 665| 5.0|1147878820|
| 1| 899| 3.5|1147868510|
| 1| 1088| 4.0|1147868495|
| 1| 1175| 3.5|1147868826|
| 1| 1217| 3.5|1147878326|
| 1| 1237| 5.0|1147868839|
| 1| 1250| 4.0|1147868414|
| 1| 1260| 3.5|1147877857|
| 1| 1653| 4.0|1147868097|
| 1| 2011| 2.5|1147868079|
| 1| 2012| 2.5|1147868068|
| 1| 2068| 2.5|1147869044|
| 1| 2161| 3.5|1147868609|
| 1| 2351| 4.5|1147877957|
| 1| 2573| 4.0|1147878923|
| 1| 2632| 5.0|1147878248|
| 1| 2692| 5.0|1147869100|
+------+-------+------+----------+
only showing top 20 rows
Plain Text
복사
•
ML 라이브러리 불러와서 모델 만들기
from pyspark.ml.recommendation import ALS # ALS 알고리즘 불러오기
als = ALS(
maxIter=5,
regParam=0.1,
userCol="userId",
itemCol="movieId",
ratingCol="rating",
coldStartStrategy="drop"
)
model = als.fit(train_df) # fit 컴포넌트를 활용한 train
predictions = model.transform(test_df) # transform 컴포넌트를 활용한 model test
predictions.show()
Python
복사
+------+-------+------+----------+
|userId|movieId|rating|prediction|
+------+-------+------+----------+
| 76| 1342| 3.5| 2.9047337|
| 85| 1088| 2.0| 3.7284317|
| 132| 1238| 5.0| 3.2149928|
| 132| 1580| 3.0| 3.2497048|
| 137| 1645| 3.0| 3.167203|
| 230| 833| 3.0| 2.5753236|
| 230| 1088| 4.0| 3.115355|
| 243| 1580| 3.0| 2.5723686|
| 319| 1238| 5.0| 3.8150952|
| 333| 1088| 5.0| 4.05824|
| 368| 1580| 3.5| 3.603326|
| 368| 3175| 5.0| 3.5701354|
| 409| 8638| 5.0| 3.9008398|
| 458| 1580| 3.5| 3.1976578|
| 472| 3918| 3.0| 2.3450446|
| 548| 5803| 2.5| 2.6988087|
| 548| 36525| 3.5| 3.169841|
| 548| 82529| 3.0| 3.22782|
| 587| 6466| 4.0| 3.3879008|
| 597| 3997| 1.0| 1.9163384|
+------+-------+------+----------+
only showing top 20 rows
Plain Text
복사
•
모델 평가
from pyspark.ml.evaluation import RegressionEvaluator
evaluator = RegressionEvaluator(metricName="rmse", labelCol='rating', predictionCol='prediction')
rmse = evaluator.evaluate(predictions)
print(rmse)
>> ex) 0.8184303257919787
Python
복사
•
추천
model.recommendForAllUsers(3).show() # 유저 별 Top3개의 아이템 추천
Python
복사
+------+--------------------+
|userId| recommendations|
+------+--------------------+
| 12|[{151989, 6.29235...|
| 22|[{199187, 7.83498...|
| 26|[{151989, 5.92996...|
| 27|[{203086, 6.41190...|
| 28|[{151989, 8.20413...|
| 31|[{151989, 4.24829...|
| 34|[{151989, 6.02863...|
| 44|[{151989, 7.49052...|
| 47|[{151989, 5.90802...|
| 53|[{151989, 7.39449...|
| 65|[{205277, 6.63911...|
| 76|[{151989, 6.86239...|
| 78|[{151989, 7.89406...|
| 81|[{151989, 4.36021...|
| 85|[{151989, 5.68050...|
| 91|[{203086, 5.94486...|
| 93|[{151989, 6.51991...|
| 101|[{151989, 5.67113...|
| 103|[{151989, 6.55442...|
| 108|[{151989, 6.03695...|
+------+--------------------+
only showing top 20 rows
Plain Text
복사
•
유저별 추천 api를 위한 코드
from pyspark.sql.types import IntegerType
user_list = [65, 78, 81]
users_df = spark.createDataFrame(user_list, IntegerType()).toDF('userId')
Python
복사
user_recs = model.recommendForUserSubset(users_df, 5)
movies_list = user_recs.collect()[0].recommendations
recs_df = spark.createDataFrame(movies_list)
Python
복사
택시비 예측하기
•
구조 확인 및 필요 컬럼 추출
trips_df.createOrReplaceTempView("trips") # sql에서 쓸 수 있게 변환
Python
복사
query = """
SELECT
trip_distance, #캐스팅 필요할 수도 있음.
total_amount
FROM
trips
WHERE
total_amount < 5000
AND total_amount > 0
AND trip_distance > 0
AND trip_distance < 500
AND passenger_count < 4
AND TO_DATE(tpep_pickup_datetime) >= '2021-01-01'
AND TO_DATE(tpep_pickup_datetime) < '2021-04-01'
"""
SQL
복사
+-------------+------------+
|trip_distance|total_amount|
+-------------+------------+
| 2.1| 11.8|
| 0.2| 4.3|
| 14.7| 51.95|
| 10.6| 36.35|
| 4.94| 24.36|
| 1.6| 14.15|
| 4.1| 17.3|
| 5.7| 21.8|
| 9.1| 28.8|
| 2.7| 18.95|
| 6.11| 24.3|
| 1.21| 10.79|
| 7.4| 33.92|
| 1.01| 10.3|
| 0.73| 12.09|
| 1.17| 12.36|
| 0.78| 9.96|
| 1.66| 12.3|
| 0.93| 9.3|
| 1.16| 11.84|
+-------------+------------+
only showing top 20 rows
Plain Text
복사
•
feature column 생성을 통한 Train 데이터셋 구성
from pyspark.ml.feature import VectorAssembler
vassembler = VectorAssembler(inputCols=["trip_distance"], outputCol="features")
vtrain_df = vassembler.transform(train_df)
Python
복사
•
regression 모델 생성
from pyspark.ml.regression import LinearRegression
lr = LinearRegression(
maxIter=50,
labelCol="total_amount",
featuresCol="features"
)
model = lr.fit(vtrain_df)
vtest_df = vassembler.transform(test_df)
prediction = model.transform(vtest_df)
prediction.show()
Python
복사
+-------------+------------+--------+-----------------+
|trip_distance|total_amount|features| prediction|
+-------------+------------+--------+-----------------+
| 0.01| 3.3| [0.01]|8.291036440655487|
| 0.01| 3.3| [0.01]|8.291036440655487|
| 0.01| 3.3| [0.01]|8.291036440655487|
| 0.01| 3.3| [0.01]|8.291036440655487|
| 0.01| 3.3| [0.01]|8.291036440655487|
| 0.01| 3.3| [0.01]|8.291036440655487|
| 0.01| 3.3| [0.01]|8.291036440655487|
| 0.01| 3.3| [0.01]|8.291036440655487|
| 0.01| 3.3| [0.01]|8.291036440655487|
| 0.01| 3.3| [0.01]|8.291036440655487|
| 0.01| 3.3| [0.01]|8.291036440655487|
| 0.01| 3.3| [0.01]|8.291036440655487|
| 0.01| 3.3| [0.01]|8.291036440655487|
| 0.01| 3.3| [0.01]|8.291036440655487|
| 0.01| 3.8| [0.01]|8.291036440655487|
| 0.01| 3.8| [0.01]|8.291036440655487|
| 0.01| 3.8| [0.01]|8.291036440655487|
| 0.01| 3.8| [0.01]|8.291036440655487|
| 0.01| 3.8| [0.01]|8.291036440655487|
| 0.01| 3.8| [0.01]|8.291036440655487|
+-------------+------------+--------+-----------------+
only showing top 20 rows
Plain Text
복사
•
모델 평가
model.summary.rootMeanSquaredError
>> ex) 4.872759850891687
Python
복사
model.summary.r2 # total amount의 82%가 trip_distance로 설명이 가능하다는 말과 같음.
>> ex) 0.8237208415594777
Python
복사
•
직접 입력값 설정해서 예측
from pyspark.sql.types import DoubleType
distance_list = [1.1, 5.5, 10.5, 30.0]
distance_df = spark.createDataFrame(distance_list, DoubleType()).toDF("trip_distance")
vdistance_df = vassembler.transform(distance_df)
model.transform(vdistance_df).show()
Python
복사
+-------------+--------+------------------+
|trip_distance|features| prediction|
+-------------+--------+------------------+
| 1.1| [1.1]|11.770960525327574|
| 5.5| [5.5]|25.818360500150682|
| 10.5| [10.5]|41.781315016995116|
| 30.0| [30.0]|104.03683763268842|
+-------------+--------+------------------+
Plain Text
복사


