파이프라인 에러메시지 받기
conda install (Windows)
conda install (MacOS)
CeleryExecutor + Redis + PostgreSQL 버전입니다.
CeleryExecutor는 무엇인가?!
Airflow 띄워보기
적당한 이름의 폴더를 만들고 거기로 이동합니다.
mkdir airflow && cd airflow
Bash
복사
conda나 venv 등 편한 툴을 활용하여 가상 환경을 구축합니다. python은 3.8
Windows 환경에서 오류날 경우
conda create -n airflow-practice python=3.8
Bash
복사
Dockerfile 파일 생성
# Dockerfile
FROM apache/airflow:2.5.1
USER root
RUN apt-get update && apt-get install -y build-essential
RUN apt-get install -y default-libmysqlclient-dev
CMD ["webserver"]
Docker
복사
docker-compose.yaml 파일을 작성 (참고로 CeleryExecutor with Redis and PostgreSQL 버전입니다)
# docker-compose.yaml
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing,
# software distributed under the License is distributed on an
# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
#
# Basic Airflow cluster configuration for CeleryExecutor with Redis and PostgreSQL.
#
# WARNING: This configuration is for local development. Do not use it in a production deployment.
#
# This configuration supports basic configuration using environment variables or an .env file
# The following variables are supported:
#
# AIRFLOW_IMAGE_NAME - Docker image name used to run Airflow.
# Default: apache/airflow:2.5.1
# AIRFLOW_UID - User ID in Airflow containers
# Default: 50000
# AIRFLOW_PROJ_DIR - Base path to which all the files will be volumed.
# Default: .
# Those configurations are useful mostly in case of standalone testing/running Airflow in test/try-out mode
#
# _AIRFLOW_WWW_USER_USERNAME - Username for the administrator account (if requested).
# Default: airflow
# _AIRFLOW_WWW_USER_PASSWORD - Password for the administrator account (if requested).
# Default: airflow
# _PIP_ADDITIONAL_REQUIREMENTS - Additional PIP requirements to add when starting all containers.
# Default: ''
#
# Feel free to modify this file to suit your needs.
---
version: '3'
x-airflow-common:
&airflow-common
# In order to add custom dependencies or upgrade provider packages you can use your extended image.
# Comment the image line, place your Dockerfile in the directory where you placed the docker-compose.yaml
# and uncomment the "build" line below, Then run `docker-compose build` to build the images.
image: ${AIRFLOW_IMAGE_NAME:-apache/airflow:2.5.1}
# build:
# context: .
# dockerfile: Dockerfile
environment:
&airflow-common-env
AIRFLOW__CORE__EXECUTOR: CeleryExecutor
AIRFLOW__DATABASE__SQL_ALCHEMY_CONN: postgresql+psycopg2://airflow:airflow@postgres/airflow
# For backward compatibility, with Airflow <2.3
AIRFLOW__CORE__SQL_ALCHEMY_CONN: postgresql+psycopg2://airflow:airflow@postgres/airflow
AIRFLOW__CELERY__RESULT_BACKEND: db+postgresql://airflow:airflow@postgres/airflow
AIRFLOW__CELERY__BROKER_URL: redis://:@redis:6379/0
AIRFLOW__CORE__FERNET_KEY: ''
AIRFLOW__CORE__DAGS_ARE_PAUSED_AT_CREATION: 'true'
AIRFLOW__CORE__LOAD_EXAMPLES: 'true'
AIRFLOW__API__AUTH_BACKENDS: 'airflow.api.auth.backend.basic_auth,airflow.api.auth.backend.session'
_PIP_ADDITIONAL_REQUIREMENTS: ${_PIP_ADDITIONAL_REQUIREMENTS:- pandas numpy beautifulsoup4 }
volumes:
- ${AIRFLOW_PROJ_DIR:-.}/dags:/opt/airflow/dags
- ${AIRFLOW_PROJ_DIR:-.}/logs:/opt/airflow/logs
- ${AIRFLOW_PROJ_DIR:-.}/plugins:/opt/airflow/plugins
- ${AIRFLOW_PROJ_DIR:-.}/data:/opt/airflow/data
user: "${AIRFLOW_UID:-50000}:0"
depends_on:
&airflow-common-depends-on
redis:
condition: service_healthy
postgres:
condition: service_healthy
services:
postgres:
image: postgres:13
environment:
POSTGRES_USER: airflow
POSTGRES_PASSWORD: airflow
POSTGRES_DB: airflow
volumes:
- postgres-db-volume:/var/lib/postgresql/data
healthcheck:
test: ["CMD", "pg_isready", "-U", "airflow"]
interval: 5s
retries: 5
restart: always
redis:
image: redis:latest
expose:
- 6379
healthcheck:
test: ["CMD", "redis-cli", "ping"]
interval: 5s
timeout: 30s
retries: 50
restart: always
airflow-webserver:
<<: *airflow-common
command: webserver
ports:
- 8080:8080
healthcheck:
test: ["CMD", "curl", "--fail", "http://localhost:8080/health"]
interval: 10s
timeout: 10s
retries: 5
restart: always
depends_on:
<<: *airflow-common-depends-on
airflow-init:
condition: service_completed_successfully
airflow-scheduler:
<<: *airflow-common
command: scheduler
healthcheck:
test: ["CMD-SHELL", 'airflow jobs check --job-type SchedulerJob --hostname "$${HOSTNAME}"']
interval: 10s
timeout: 10s
retries: 5
restart: always
depends_on:
<<: *airflow-common-depends-on
airflow-init:
condition: service_completed_successfully
airflow-worker:
<<: *airflow-common
command: celery worker
healthcheck:
test:
- "CMD-SHELL"
- 'celery --app airflow.executors.celery_executor.app inspect ping -d "celery@$${HOSTNAME}"'
interval: 10s
timeout: 10s
retries: 5
environment:
<<: *airflow-common-env
# Required to handle warm shutdown of the celery workers properly
# See https://airflow.apache.org/docs/docker-stack/entrypoint.html#signal-propagation
DUMB_INIT_SETSID: "0"
restart: always
depends_on:
<<: *airflow-common-depends-on
airflow-init:
condition: service_completed_successfully
airflow-triggerer:
<<: *airflow-common
command: triggerer
healthcheck:
test: ["CMD-SHELL", 'airflow jobs check --job-type TriggererJob --hostname "$${HOSTNAME}"']
interval: 10s
timeout: 10s
retries: 5
restart: always
depends_on:
<<: *airflow-common-depends-on
airflow-init:
condition: service_completed_successfully
airflow-init:
<<: *airflow-common
entrypoint: /bin/bash
# yamllint disable rule:line-length
command:
- -c
- |
function ver() {
printf "%04d%04d%04d%04d" $${1//./ }
}
airflow_version=$$(AIRFLOW__LOGGING__LOGGING_LEVEL=INFO && gosu airflow airflow version)
airflow_version_comparable=$$(ver $${airflow_version})
min_airflow_version=2.2.0
min_airflow_version_comparable=$$(ver $${min_airflow_version})
if (( airflow_version_comparable < min_airflow_version_comparable )); then
echo
echo -e "\033[1;31mERROR!!!: Too old Airflow version $${airflow_version}!\e[0m"
echo "The minimum Airflow version supported: $${min_airflow_version}. Only use this or higher!"
echo
exit 1
fi
if [[ -z "${AIRFLOW_UID}" ]]; then
echo
echo -e "\033[1;33mWARNING!!!: AIRFLOW_UID not set!\e[0m"
echo "If you are on Linux, you SHOULD follow the instructions below to set "
echo "AIRFLOW_UID environment variable, otherwise files will be owned by root."
echo "For other operating systems you can get rid of the warning with manually created .env file:"
echo " See: https://airflow.apache.org/docs/apache-airflow/stable/howto/docker-compose/index.html#setting-the-right-airflow-user"
echo
fi
one_meg=1048576
mem_available=$$(($$(getconf _PHYS_PAGES) * $$(getconf PAGE_SIZE) / one_meg))
cpus_available=$$(grep -cE 'cpu[0-9]+' /proc/stat)
disk_available=$$(df / | tail -1 | awk '{print $$4}')
warning_resources="false"
if (( mem_available < 4000 )) ; then
echo
echo -e "\033[1;33mWARNING!!!: Not enough memory available for Docker.\e[0m"
echo "At least 4GB of memory required. You have $$(numfmt --to iec $$((mem_available * one_meg)))"
echo
warning_resources="true"
fi
if (( cpus_available < 2 )); then
echo
echo -e "\033[1;33mWARNING!!!: Not enough CPUS available for Docker.\e[0m"
echo "At least 2 CPUs recommended. You have $${cpus_available}"
echo
warning_resources="true"
fi
if (( disk_available < one_meg * 10 )); then
echo
echo -e "\033[1;33mWARNING!!!: Not enough Disk space available for Docker.\e[0m"
echo "At least 10 GBs recommended. You have $$(numfmt --to iec $$((disk_available * 1024 )))"
echo
warning_resources="true"
fi
if [[ $${warning_resources} == "true" ]]; then
echo
echo -e "\033[1;33mWARNING!!!: You have not enough resources to run Airflow (see above)!\e[0m"
echo "Please follow the instructions to increase amount of resources available:"
echo " https://airflow.apache.org/docs/apache-airflow/stable/howto/docker-compose/index.html#before-you-begin"
echo
fi
mkdir -p /sources/logs /sources/dags /sources/plugins /sources/data
chown -R "${AIRFLOW_UID}:0" /sources/{logs,dags,plugins}
exec /entrypoint airflow version
# yamllint enable rule:line-length
environment:
<<: *airflow-common-env
_AIRFLOW_DB_UPGRADE: 'true'
_AIRFLOW_WWW_USER_CREATE: 'true'
_AIRFLOW_WWW_USER_USERNAME: ${_AIRFLOW_WWW_USER_USERNAME:-airflow}
_AIRFLOW_WWW_USER_PASSWORD: ${_AIRFLOW_WWW_USER_PASSWORD:-airflow}
_PIP_ADDITIONAL_REQUIREMENTS: ''
user: "0:0"
volumes:
- ${AIRFLOW_PROJ_DIR:-.}:/sources
airflow-cli:
<<: *airflow-common
profiles:
- debug
environment:
<<: *airflow-common-env
CONNECTION_CHECK_MAX_COUNT: "0"
# Workaround for entrypoint issue. See: https://github.com/apache/airflow/issues/16252
command:
- bash
- -c
- airflow
# You can enable flower by adding "--profile flower" option e.g. docker-compose --profile flower up
# or by explicitly targeted on the command line e.g. docker-compose up flower.
# See: https://docs.docker.com/compose/profiles/
flower:
<<: *airflow-common
command: celery flower
profiles:
- flower
ports:
- 5555:5555
healthcheck:
test: ["CMD", "curl", "--fail", "http://localhost:5555/"]
interval: 10s
timeout: 10s
retries: 5
restart: always
depends_on:
<<: *airflow-common-depends-on
airflow-init:
condition: service_completed_successfully
volumes:
postgres-db-volume:
YAML
복사
작성 후 해당 폴더에서 docker-compose up -d 로 실행
docker compose up -d
Bash
복사
127.0.0.1:8080으로 접속하면 다음과 같은 화면이 나옵니다. 아이디 패스워드 입력 후 접속
ID: airflow / PW: airflow
접속하면 아래와 같은 화면을 볼 수 있습니다.
크롤링 활용 ETL 파이프라인 구성
본격적으로 DAG 개발을 해봅시다.
아래 코드는 indeed에서 airflow 기술 스택을 사용하는 채용 공고를 검색, title을 크롤링하여 저장하는 아주!! 간단한 ETL을 airflow로 돌려보겠습니다.
1.
Airflow Webserver에서 Admin의 Connections를 클릭합니다.
2.
+를 눌러 새로운 커넥션을 등록해줍니다.
3.
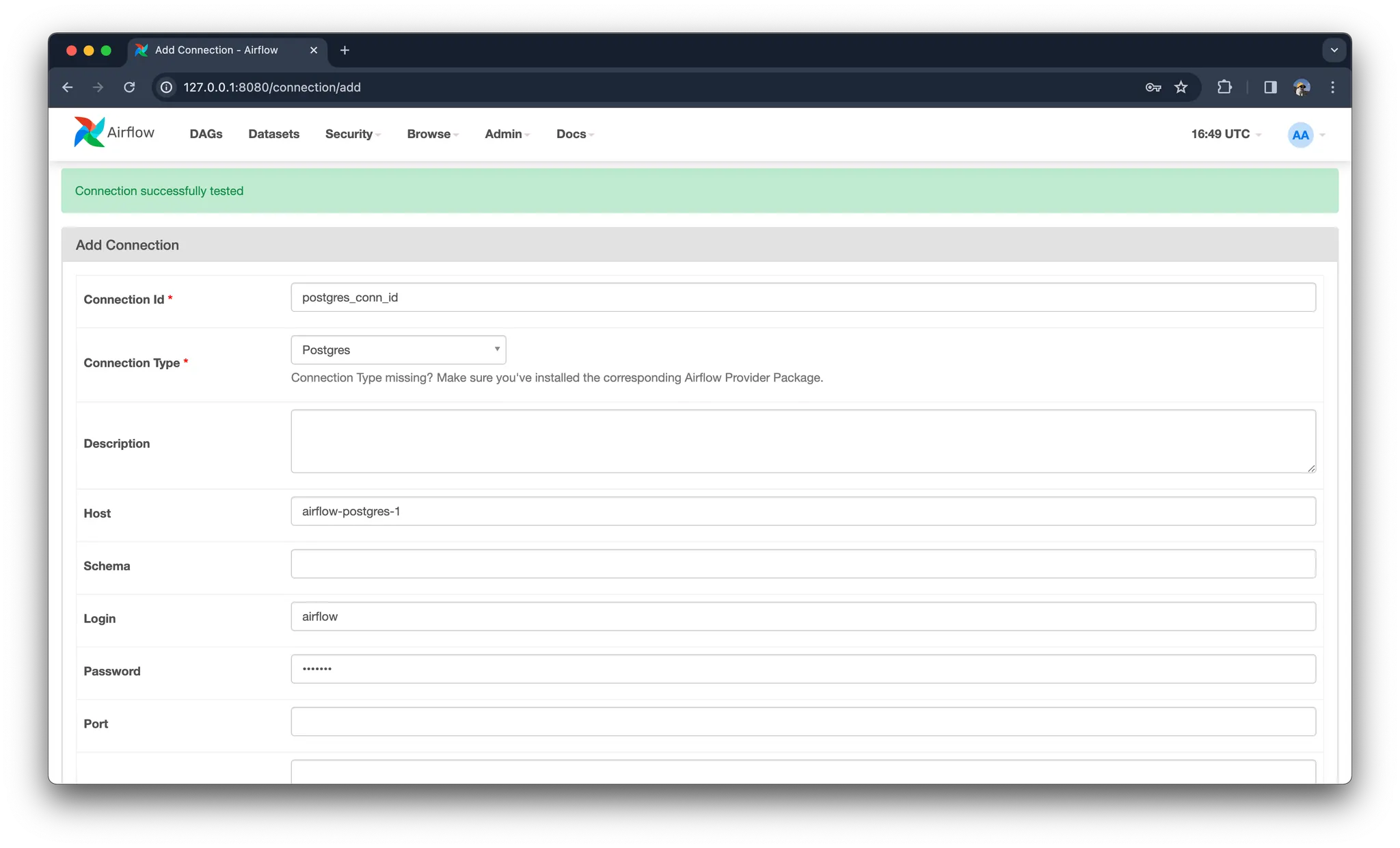
Connection Type을 Postgres로 변경하고 정보를 입력합니다.
•
Connection Id : postgres_conn_id
•
Connection Type : Postgres
•
Host : 자신의 Postgres 컨테이너 이름
◦
postgres
•
Login : airflow
•
Password : airflow
•
Port : 5432
4.
Test해보고 연결이 된다면 Save를 눌러 Connection을 등록 완료합니다.
5.
Admin의 Variables를 클릭합니다.
6.
+를 눌러 새로운 환경 변수를 등록해줍니다.
7.
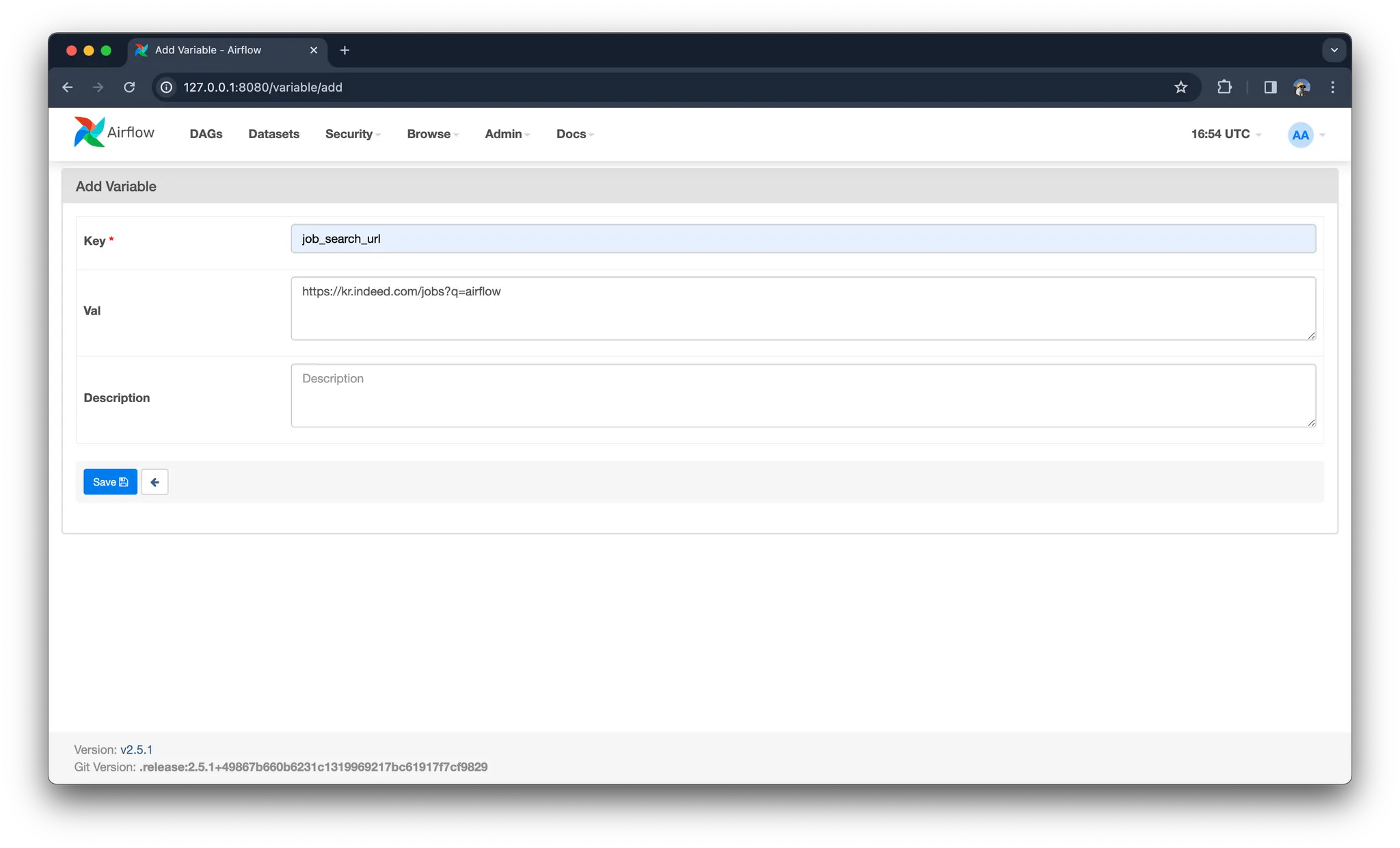
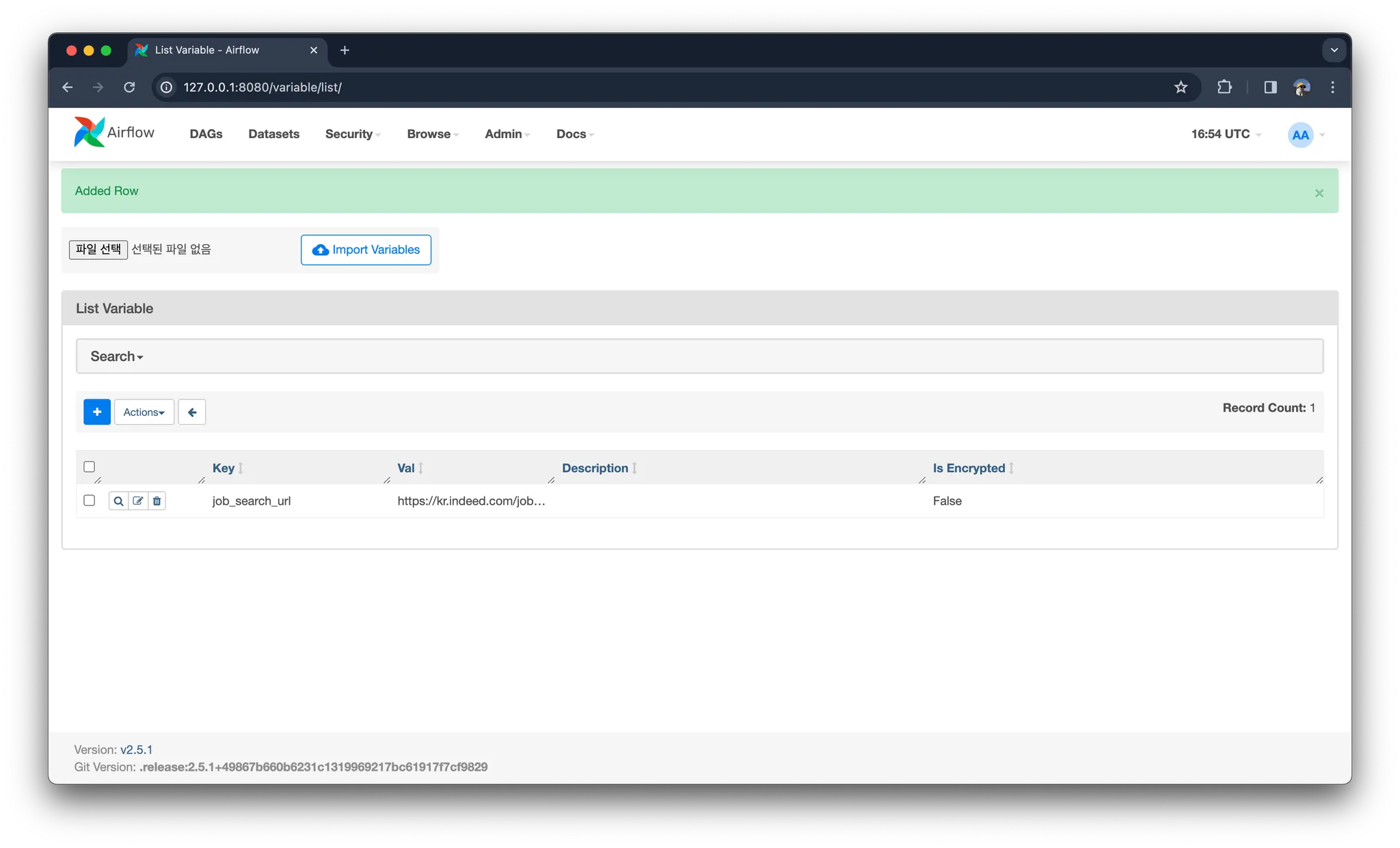
DAG 작성하기
우선, 전체 파일 구조는 다음과 같습니다.
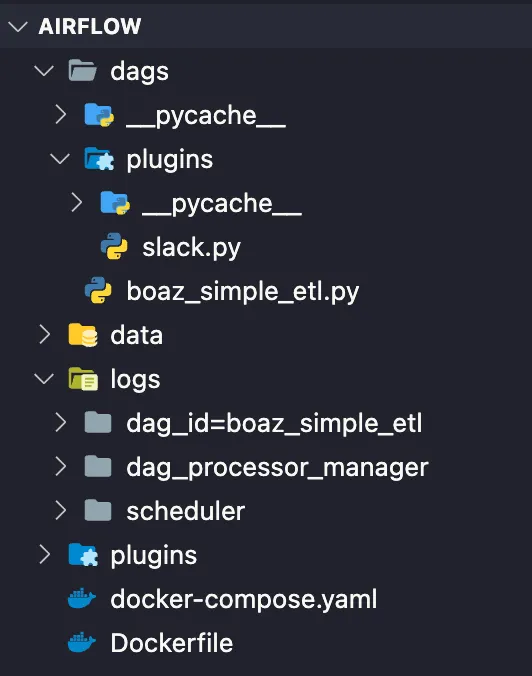
dags 폴더에 boaz_simple_etl.py 파일을 하나 생성합니다. (vi 혹은 IDE 활용)
# boaz_simple_etl.py
from datetime import datetime, timedelta
from airflow import DAG
from airflow.models import Variable
import requests
from bs4 import BeautifulSoup
import csv
# 사용할 Operator Import
from airflow.providers.postgres.operators.postgres import PostgresOperator
from airflow.operators.python import PythonOperator
from airflow.operators.bash import BashOperator
def extract(link):
f = requests.get(link)
return f.text
def transform(text):
soup = BeautifulSoup(text, 'html.parser')
titles = []
tmp = soup.select(".title")
for title in tmp:
titles.append(title.get_text())
return titles
def load(titles):
with open("job_search_result.csv", "w") as file:
writer = csv.writer(file)
writer.writerow(titles)
def etl():
link = "https://kr.indeed.com/jobs?q=airflow"
text = extract(link)
titles = transform(text)
load(titles)
# DAG 설정
dag = DAG(
dag_id="boaz_simple_etl",
schedule_interval="@daily",
start_date=datetime(2022,6,15), #원래 시작했어야 한 날짜 하지만 명시적으로 시작 안 해주면 dag는 시작 안 함
default_args = {
'retries': 1,
'retry_delay': timedelta(minutes=3),
}, #dag 밑에 속한 task에 적용되는 파라미터
tags=["BOAZ"], #팀별로, 태스크별로 tag 붙일 수 있음 (DAG 수백개 되면 하나하나 기억할 수 없음. tag 필수)
catchup=False #start_date와 실제 시작일 사이에 실행 안 된 것을 한 번에 실행해주는 옵션 (모르겠으면 false…)
)
# Operator 만들기
creating_table = PostgresOperator(
task_id="creating_table",
postgres_conn_id="postgres_conn_id", # 웹UI에서 connection을 등록해줘야 함.
sql='''
CREATE TABLE IF NOT EXISTS job_search_result (
title TEXT
)
''',
dag = dag
)
etl = PythonOperator(
task_id = "etl",
python_callable = etl, # 실행할 파이썬 함수
dag = dag
)
# 저장되었다는 사실 echo
store_result = BashOperator(
task_id="store_result",
bash_command= "echo 'ETL Done'",
dag=dag
)
# 파이프라인 구성하기
creating_table >> etl >> store_result
Python
복사
Webserver에서 DAG 실행해보기
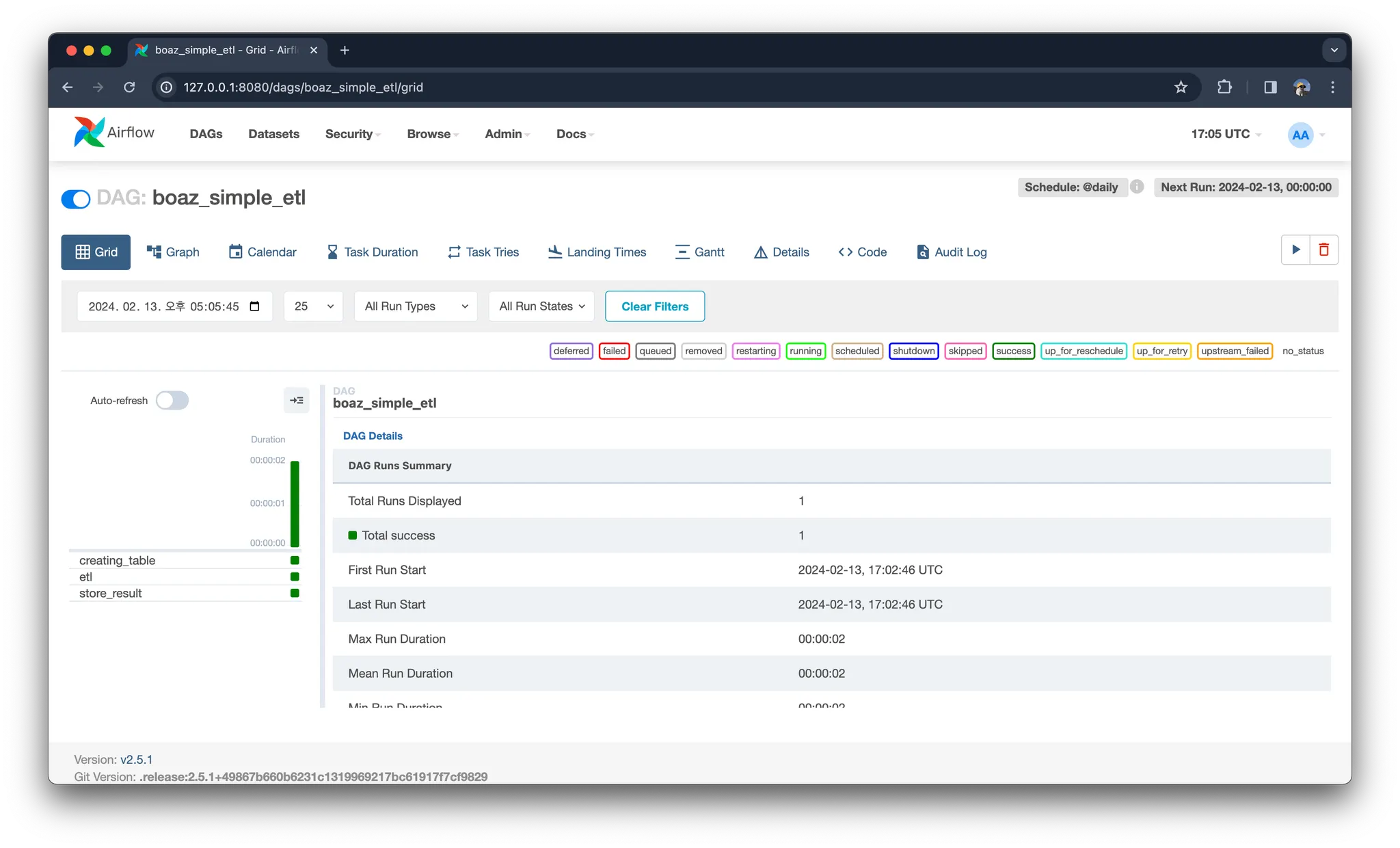
dags 폴더에서 dag를 작성하게 되면 scheduler는 이 파일을 파싱하여 web ui에서도 볼 수 있도록 나타냅니다. dag는 작성했다고 해서 바로 실행되는 것은 아닙니다. 왼쪽 토글 버튼을 클릭하여 DAG를 실행시킬 수 있습니다.
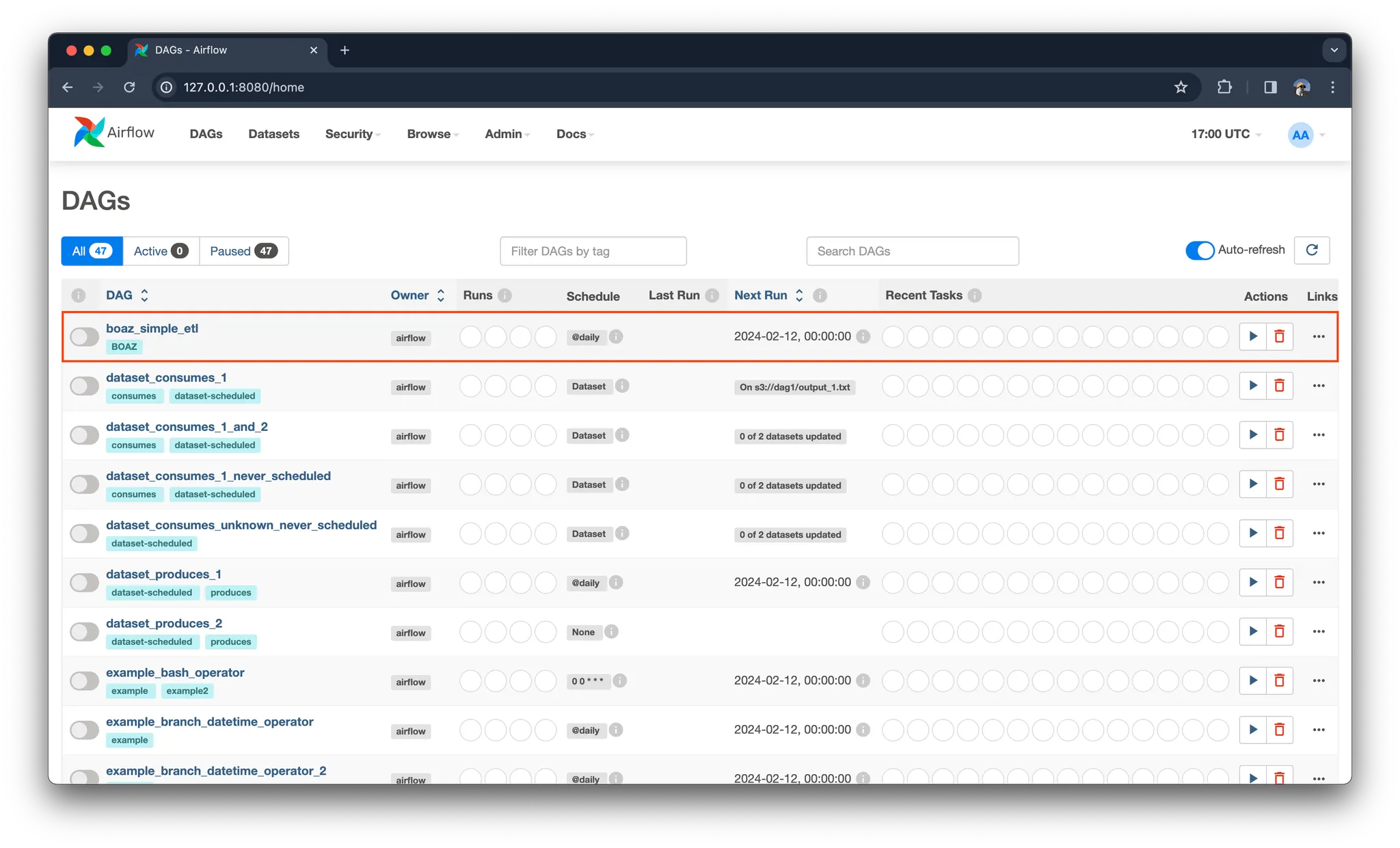
실행 후 boaz_simple_etl을 클릭하여 들어가면 아래와 같은 화면을 볼 수 있습니다. 각 태스크의 진행 상황과 메타 데이터들을 볼 수 있습니다. 이때 각 태스크가 초록색이라면 성공, 노란색이라면 실행 중, 빨간색이라면 실패했다는 것을 의미합니다. (Graph를 클릭하여 워크플로우 과정을 조금 더 직관적으로 볼 수도 있습니다)
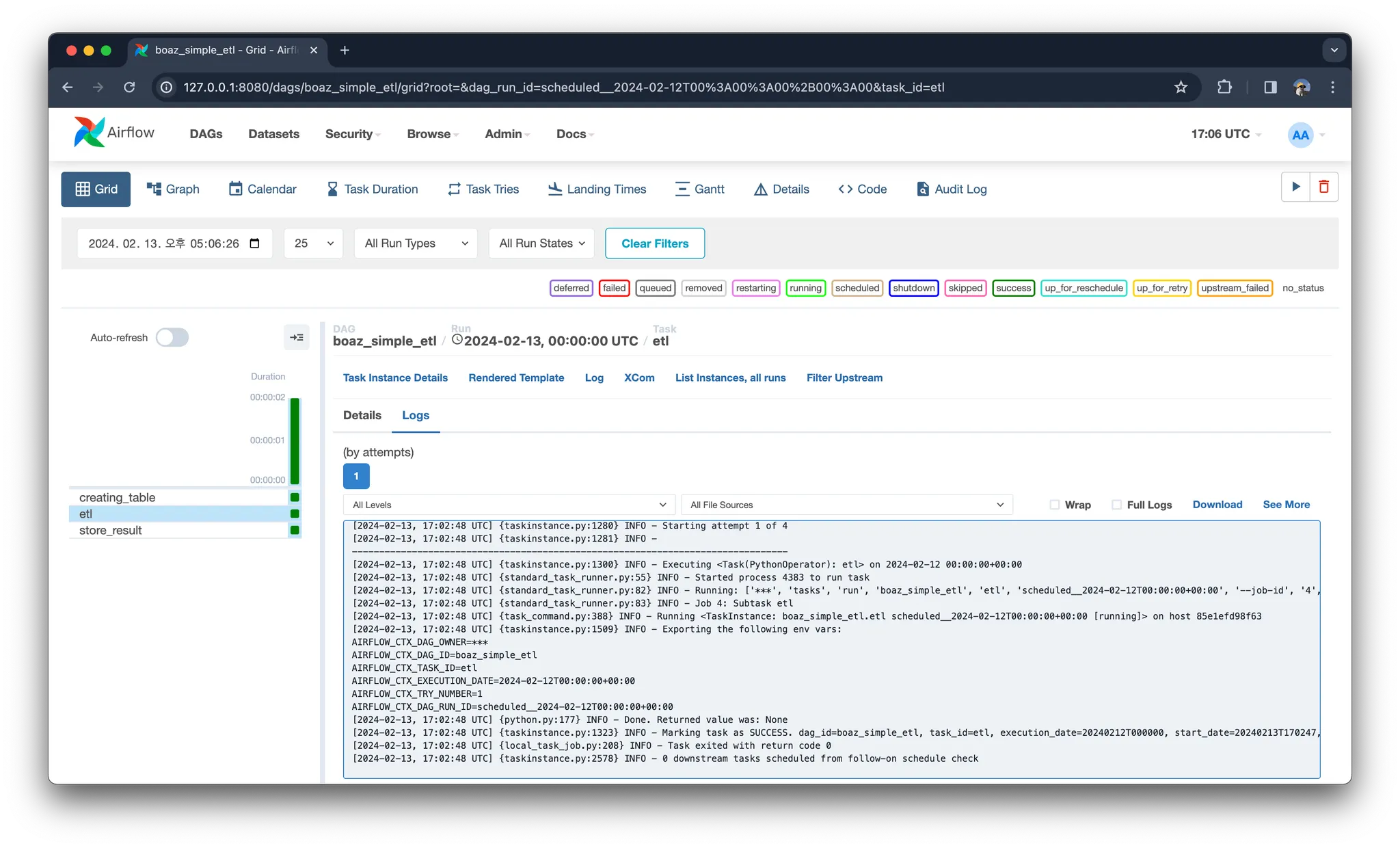
만약 계속해서 실행이 지속되거나, 태스크 실행에 실패했다면 각 태스크를 클릭하여 log를 확인할 수 있습니다. DAG 디버깅은 이 실행 로그들을 보며 할 수 있습니다.
Slack SDK를 활용한 Slack App 구성
App 생성하기

위의 링크를 통해 app을 생성합니다.
App 설정하기
OAuth & Permissions의 Scopes에 들어가서 chat:write 와 im:write 를 추가합니다.
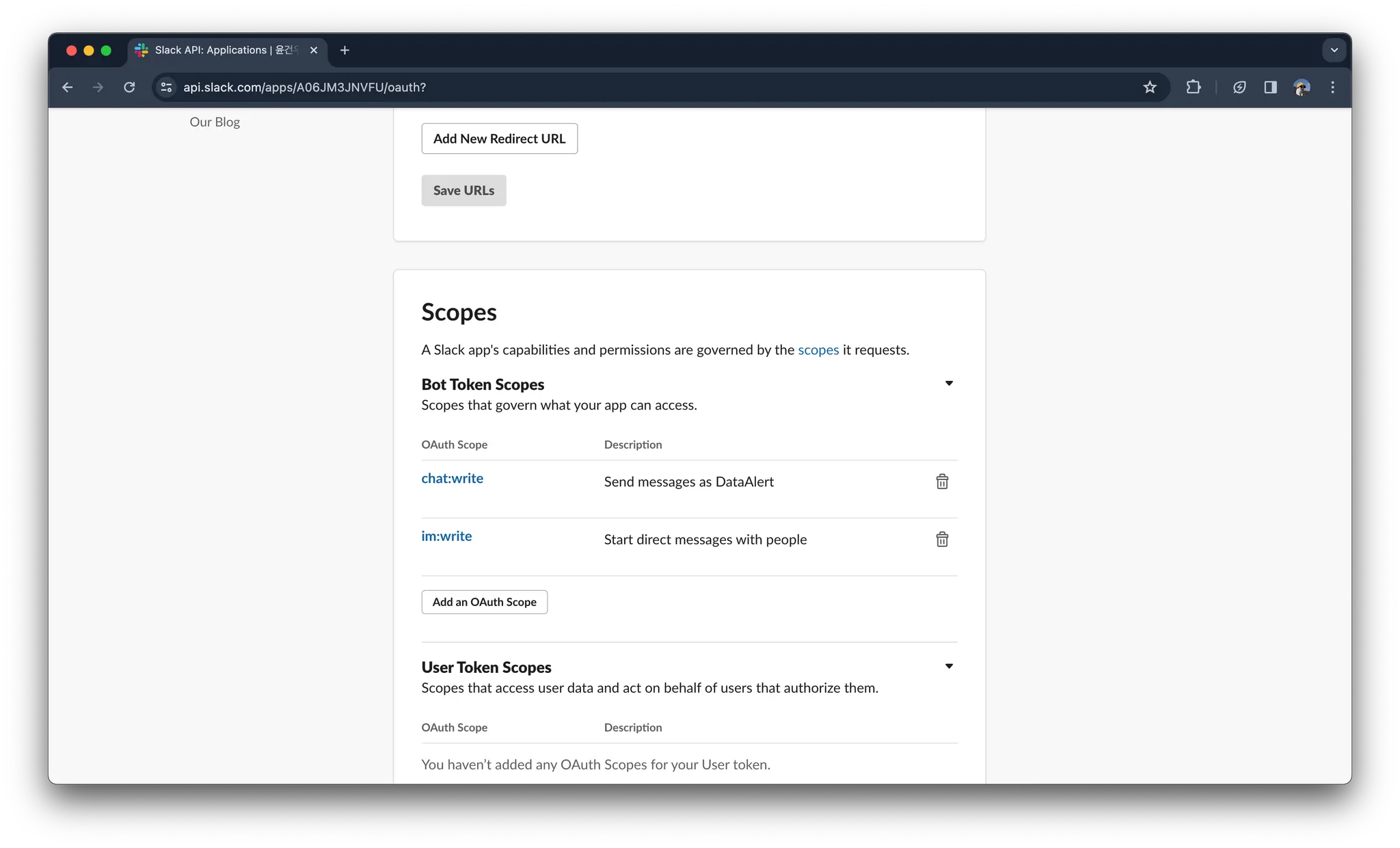
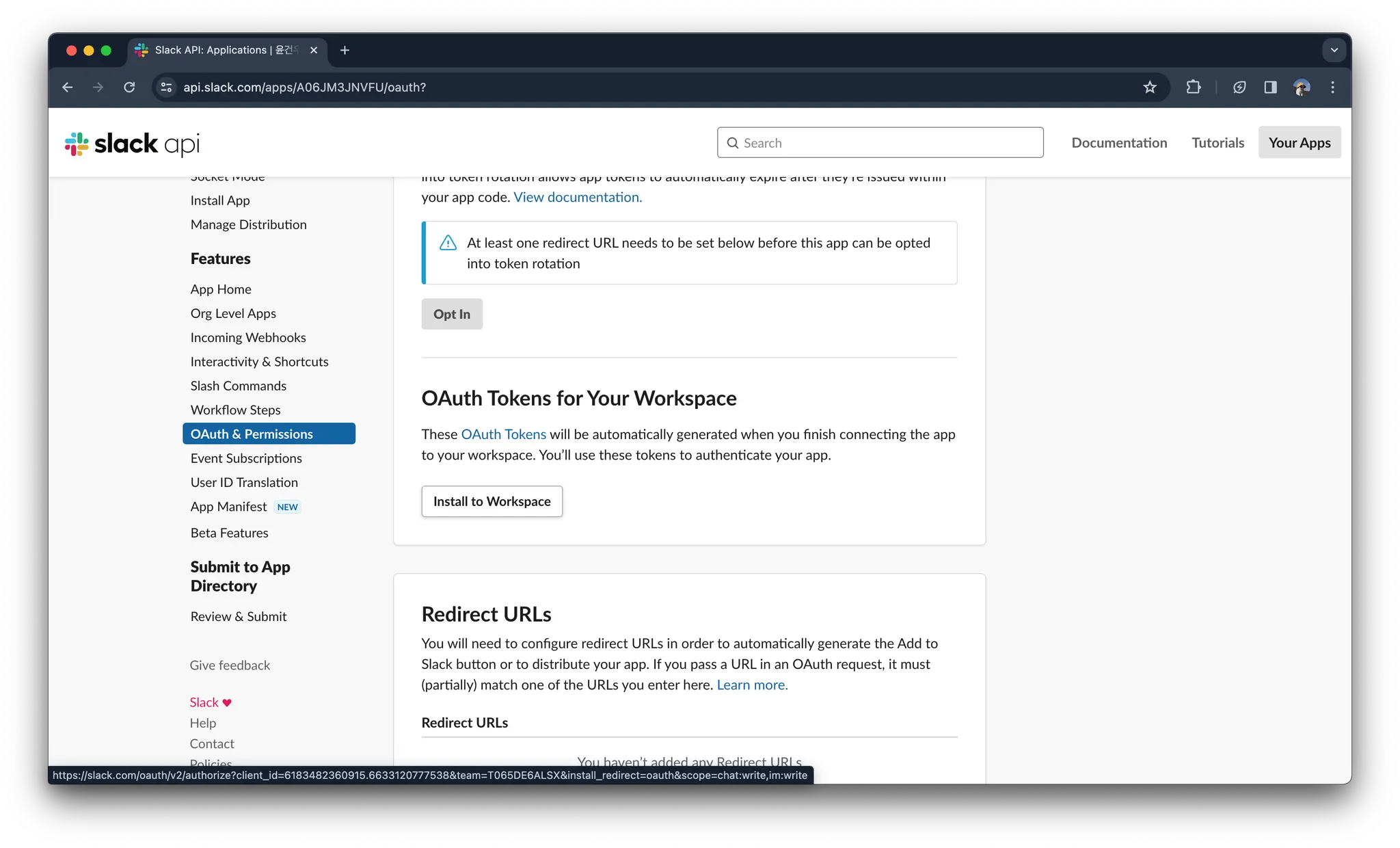
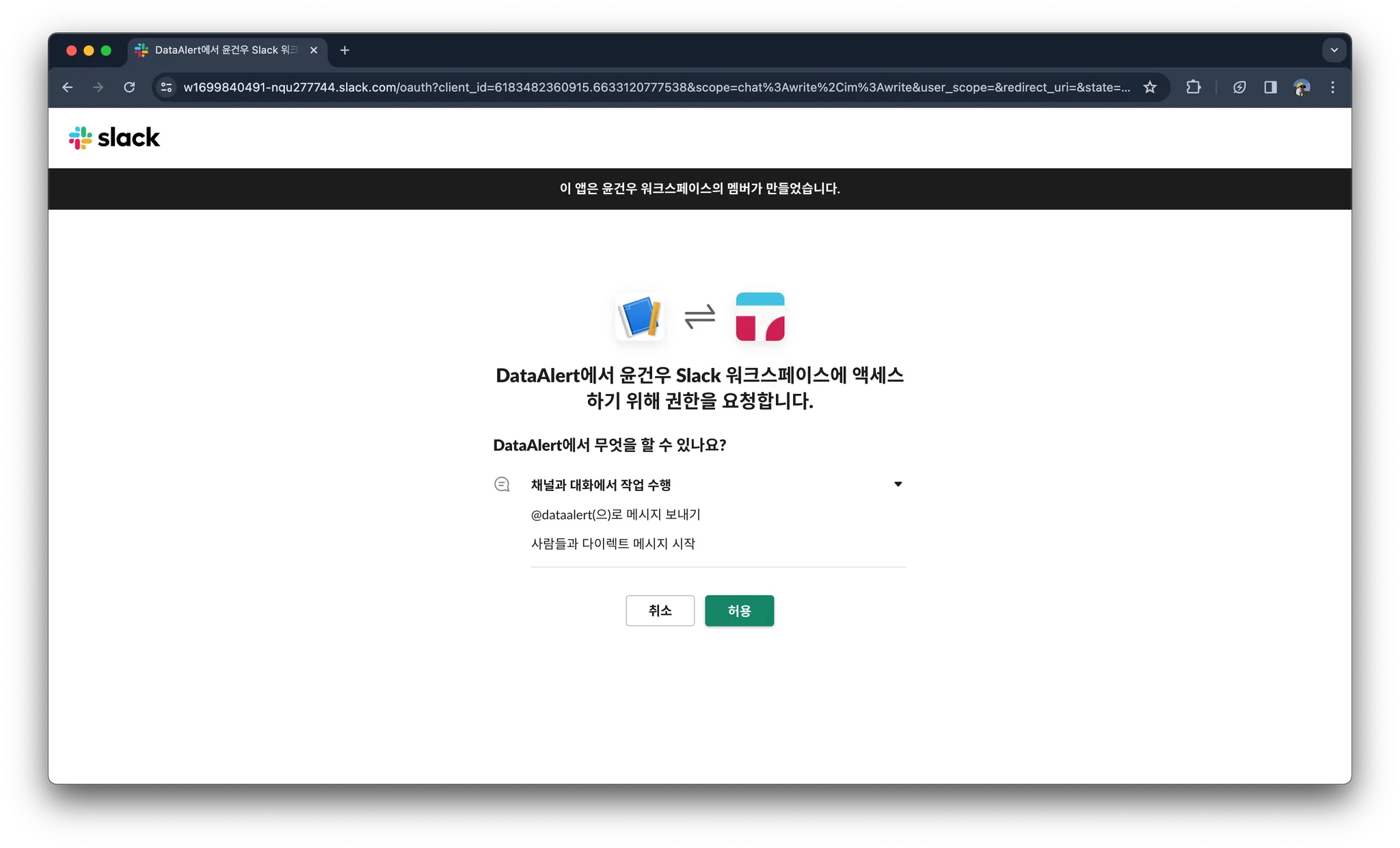
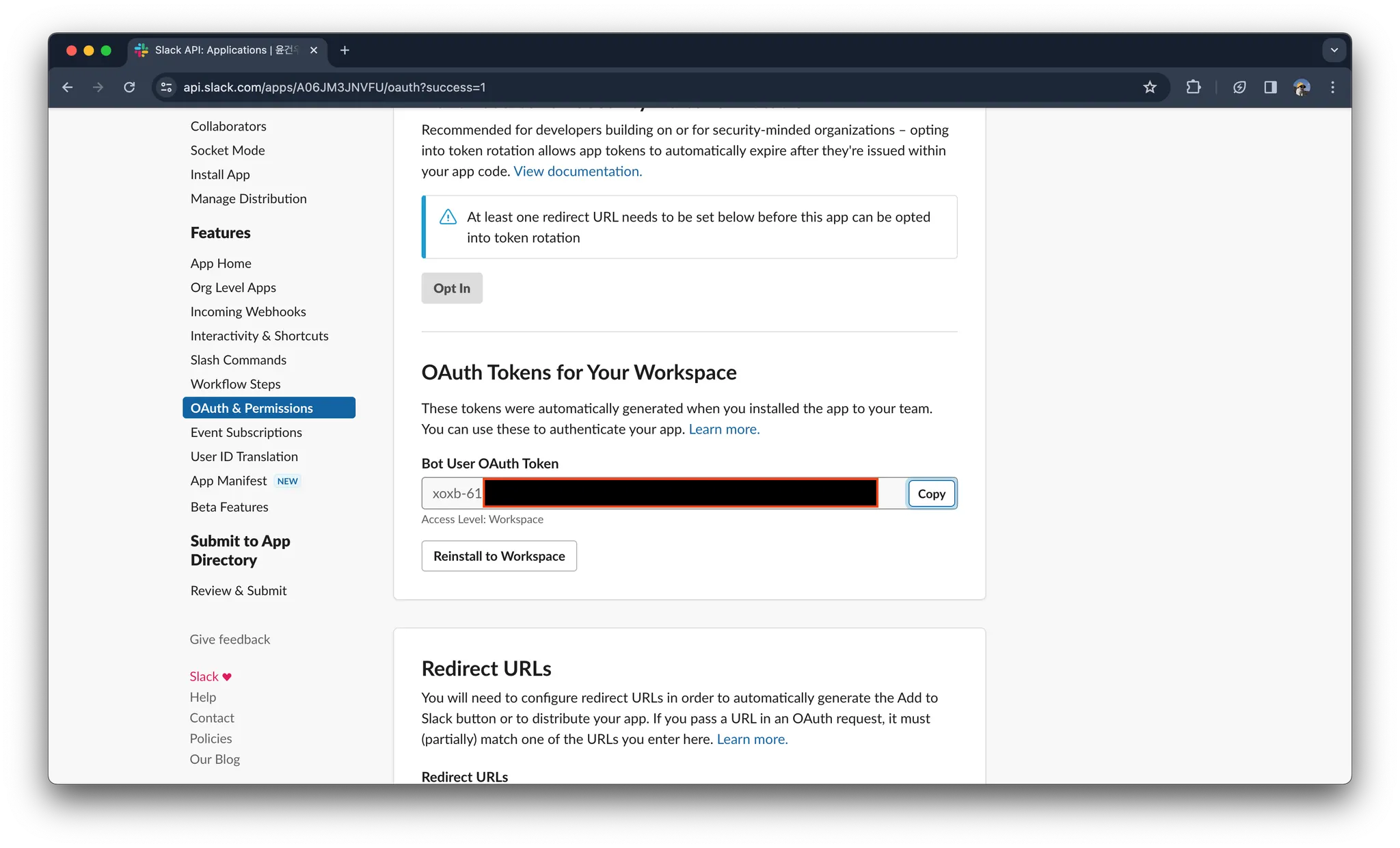
발급받은 토큰은 메모장에 꼭 저장해두기!
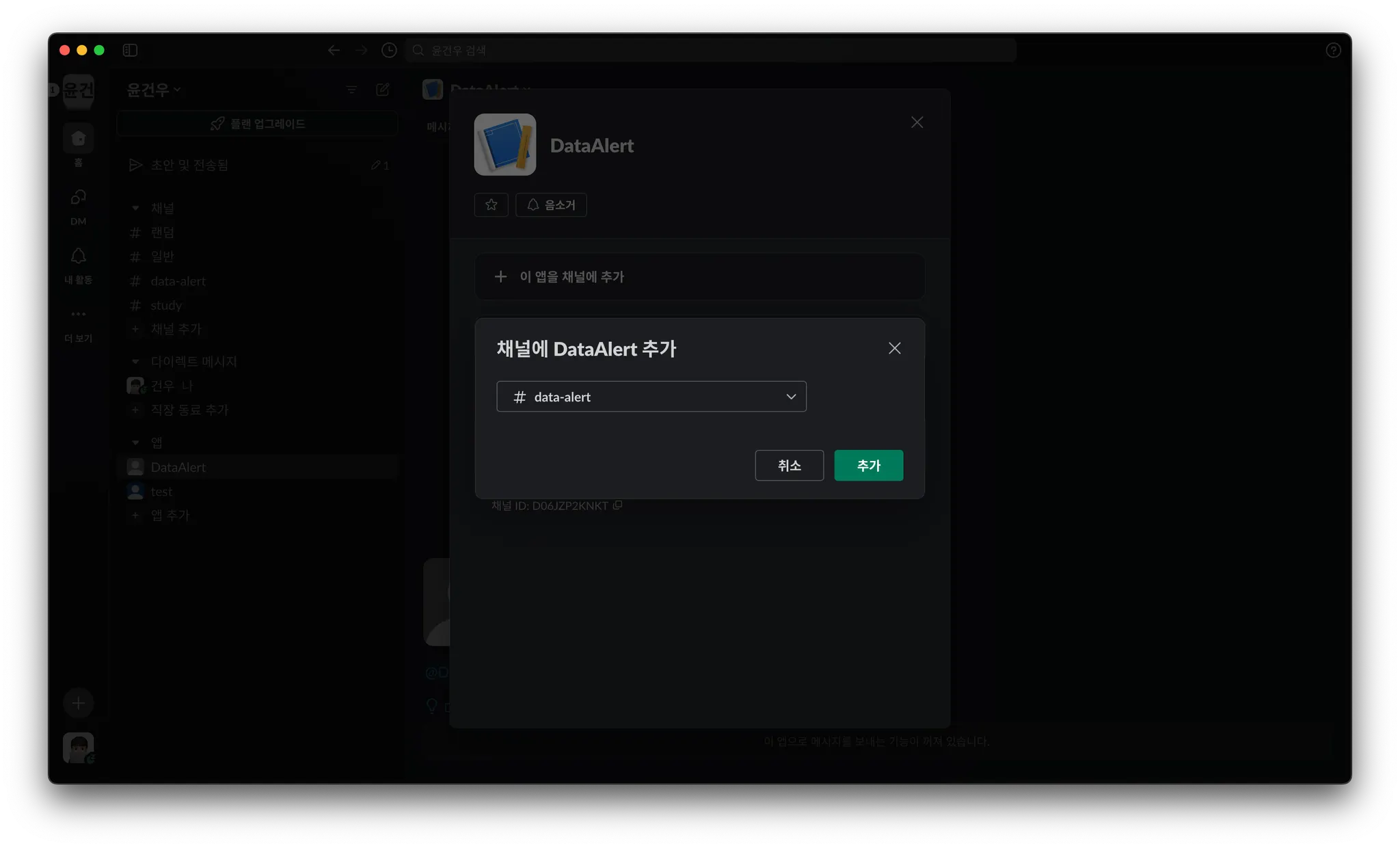
다음은 워크스페이스로 들어가서 채널에 방금 생성한 App을 추가합니다.
코드 수정 및 알림 받기
dags/plugins/slack.py 생성.
from slack_sdk import WebClient
from datetime import datetime
class SlackAlert:
def __init__(self, channel, token):
self.channel = channel
self.client = WebClient(token=token)
def success_msg(self, msg):
text = f"""
date : {datetime.today().strftime('%Y-%m-%d')}
alert :
Success!
task id : {msg.get('task_instance').task_id},
dag id : {msg.get('task_instance').dag_id},
log url : {msg.get('task_instance').log_url}
"""
self.client.chat_postMessage(channel=self.channel, text=text)
def fail_msg(self, msg):
text = f"""
date : {datetime.today().strftime('%Y-%m-%d')}
alert :
Fail!
task id : {msg.get('task_instance').task_id},
dag id : {msg.get('task_instance').dag_id},
log url : {msg.get('task_instance').log_url}
"""
self.client.chat_postMessage(channel=self.channel, text=text)
Python
복사
boaz_simple_etl.py를 수정합니다.
# boaz_simple_etl.py
from datetime import datetime, timedelta
from airflow import DAG
from airflow.models import Variable
from plugins.slack import SlackAlert
import requests
from bs4 import BeautifulSoup
import csv
# 사용할 Operator Import
from airflow.providers.postgres.operators.postgres import PostgresOperator
from airflow.operators.python import PythonOperator
from airflow.operators.bash import BashOperator
def extract(link):
f = requests.get(link)
return f.text
def transform(text):
soup = BeautifulSoup(text, 'html.parser')
titles = []
tmp = soup.select(".title")
for title in tmp:
titles.append(title.get_text())
return titles
def load(titles):
with open("job_search_result.csv", "w") as file:
writer = csv.writer(file)
writer.writerow(titles)
def etl():
link = "https://kr.indeed.com/jobs?q=airflow"
text = extract(link)
titles = transform(text)
load(titles)
# SLACK 정의
slack = SlackAlert("#채널 이름", "발급받은 token")
# DAG 설정
dag = DAG(
dag_id="boaz_simple_etl",
schedule_interval="@daily",
start_date=datetime(2022,6,15), #원래 시작했어야 한 날짜 하지만 명시적으로 시작 안 해주면 dag는 시작 안 함
default_args = {
'retries': 1,
'retry_delay': timedelta(minutes=3),
'on_success_callback': slack.success_msg, # 성공시 SLACK 함수 요청
'on_failure_callback': slack.fail_msg, # 실패시 SLACK 함수 요청
}, #dag 밑에 속한 task에 적용되는 파라미터
tags=["BOAZ"], #팀별로, 태스크별로 tag 붙일 수 있음 (DAG 수백개 되면 하나하나 기억할 수 없음. tag 필수)
catchup=False #start_date와 실제 시작일 사이에 실행 안 된 것을 한 번에 실행>해주는 옵션 (모르겠으면 false…)
)
# Operator 만들기
creating_table = PostgresOperator(
task_id="creating_table",
postgres_conn_id="postgres_conn_id", # 웹UI에서 connection을 등록해줘야 함.
sql='''
CREATE TABLE IF NOT EXISTS job_search_result (
title TEXT
)
''',
dag = dag
)
etl = PythonOperator(
task_id = "etl",
python_callable = etl, # 실행할 파이썬 함수
dag = dag
)
# 저장되었다는 사실 echo
store_result = BashOperator(
task_id="store_result",
bash_command= "echo 'ETL Done'",
dag=dag
)
# 파이프라인 구성하기
creating_table >> etl >> store_result
Python
복사
DAG를 다시 Manual하게 실행시킵니다.
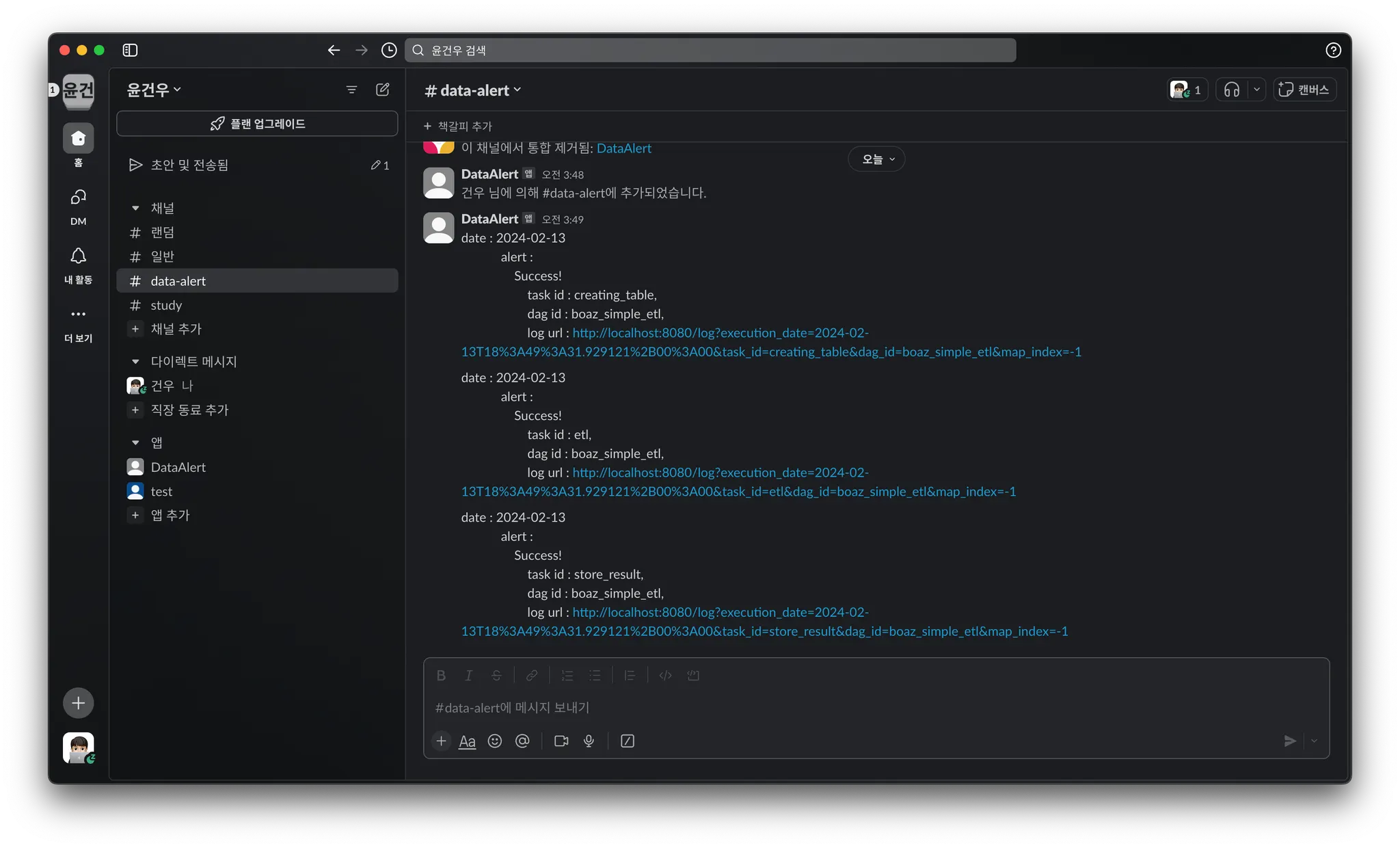
알림이 잘 오는 것을 확인할 수 있습니다.