목차
1 Kafka 기본 개념 및 설치
1.1 Kafka Overview
1.1.1 Kafka의 주요 기능
1.
Kafka 는 pub-sub model 을 지원하는 분산 메세지 큐이다.
2.
여러대의 서버로 scale-out 할 수 있는 클러스터를 구성한다.
3.
Topic 을 중심으로 producer 라고 하는 publisher 와 consumer(group) 이라고 하는 subscriber 로 데이터를 관리하고 처리한다.
4.
하나의 Topic 은 복수개의 partition 으로 확장가능하다.
1.1.2 Kafka 가 해결하는 문제
1.
기존의 RabbitMQ와 같은 single message queue 가 가지는 scale과 속도 문제를 해결할 수 있다.
2.
Cluster 구성으로 Fault tolerance, High availability 를 자체적으로 해결한다.
3.
topic, partition, offset, producer(ack), consumer group(commit) 개념으로 대용량 분산 메세지 처리에서의 메세지 저장과 처리의 신뢰를 관리할 수 있는 메커니즘을 구현했다.
4.
대용량 데이터를 다루면서도 빠른 데이터 처리가 가능하게 한다.
1.1.3 이벤트 스트리밍 플랫폼
이벤트 스트리밍 플랫폼이란 여러 이벤트 소스에서 발생하는 이벤트를 안정적으로 처리할 수 있는 시스템으로, 초당 기가바이트 이상의 이벤트를 처리하기 위해 높은 안정성 및 확장성을 갖춰야 한다. Kafka cluster(broker servers)는 안정성과 확장성이 뛰어난 분산 메세지큐이다.
뿐만 아니라 producer API, consumer API, Kafka-Streams, Kafka-Connector의 라이브러리를 통해서 탄력적으로 스트리밍 데이터를 처리할 수 있도록 하는 이벤트 스트리밍 플랫폼의 방향으로 발전하고 있다.
1.2 Kafka 구성요소
1.2.1 Kafka 서버 및 클라이언트
Kafka는 고성능 TCP 네트워크 프로토콜을 통해 통신하는 서버와 클라이언트로 구성된 분
산 시스템이다.
•
서버 : Kafka는 하나 이상의 서버로 구성된 클러스터다. 서버 중 일부는 브로커라고 하는 스토리지 계층을 형성한다. 그 외의 다른 서버는 Kafka Connect를 통해 데이터를 스트리밍하면서 Kafka를 다른 시스템(e.g. RDBMS, 다른 Kafka 클러스터 등)과 통합한다.
•
클라이언트 : Kafka 클라이언트를 사용하면 네트워크 또는 시스템 문제가 발생한 경우에도 고가용성을 보장하면서 이벤트 스트림을 병렬적으로 처리할 수 있는 분산 애플리케이션 및 마이크로서비스를 만들 수 있다. Kafka 커뮤니티에서는 Java, Scala, Go, Python, C/C++ 등 다양한 언어 기반의 Kafka 클라이언트 라이브러리를 제공하고 있다.
1.2.2 Kafka 주요 개념 및 용어
이벤트(event) : 이벤트는 발생한 일에 대한 기록으로, ‘레코드’ 또는 ‘메시지’라고도 한다. Kafka에서는 이벤트 형태로 데이터를 읽거나 쓴다. 이벤트에는 키, 값, 타임스탬프 및 선택적 메타데이터 헤더가 포함된다. 다음은 이벤트 예시다.
이벤트 키: 홍길동
이벤트 값: 1,000원 입금
이벤트 타임스탬프: 2023년 2월 1일 오전 2시 30분
Plain Text
복사
프로듀서(producer)와 컨슈머(consumer) : 프로듀서와 컨슈머는 모두 Kafka 클라이언트다. 프로듀서는 Kafka에 이벤트를 발행하며, 컨슈머는 프로듀서가 발행한 이벤트를 구독해서 읽고 처리한다. Kafka에서 프로듀서와 컨슈머는 서로 완전히 분리되어 있는데, 이는 Kafka가 높은 확장성을 달성할 수 있는 핵심 요인이다.
(e.g. 프로듀서는 컨슈머가 메시지를 수신하는 것을 기다릴 필요 없다)
Kafka가 이벤트를 처리하는 데 있어서 몇 가지를 보장하도록 설정할 수도 있다.
(e.g. 이벤트는 최소한 한 번 이상 처리된다.)
1.2.3 Kafka의 토픽(Topic)
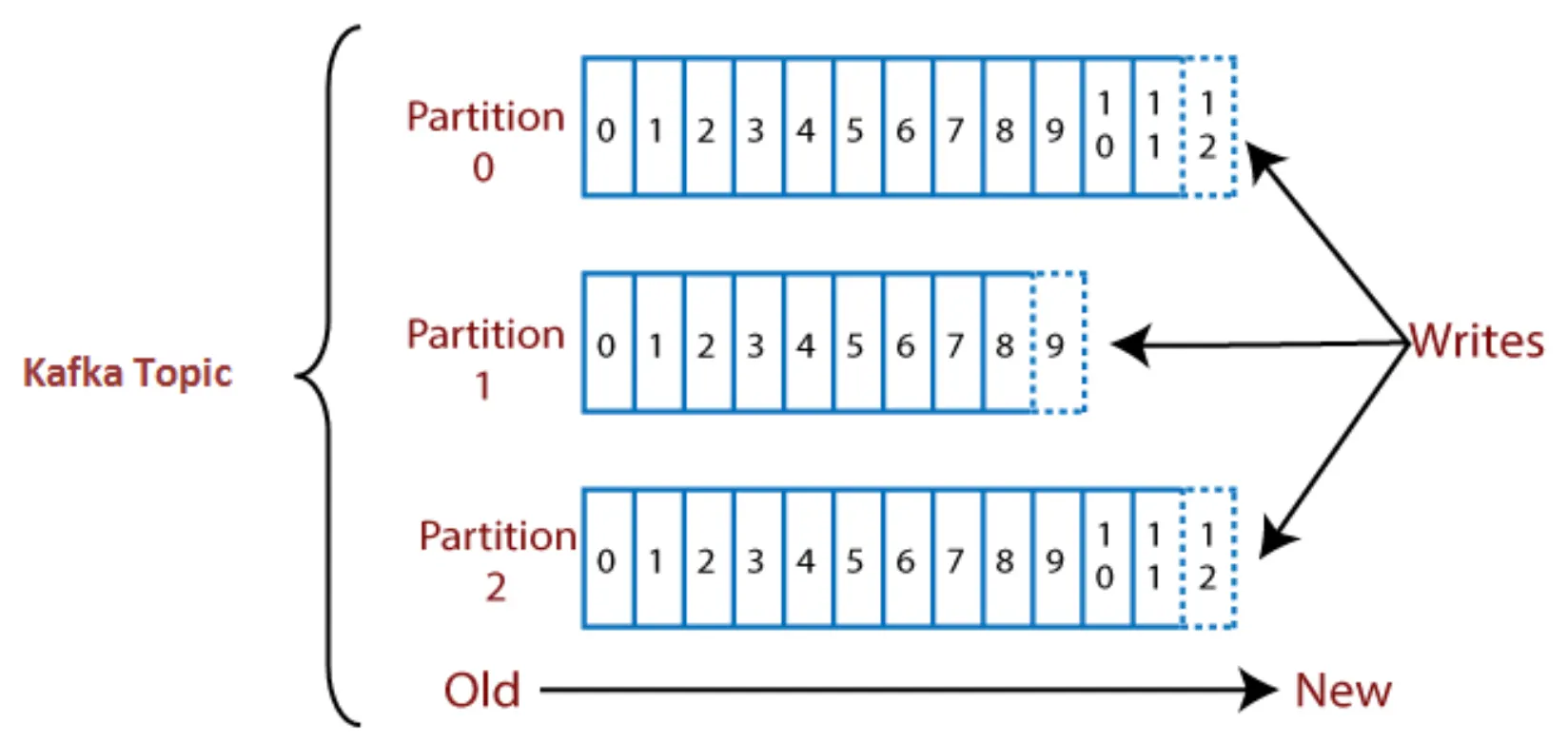
•
토픽(topic) : 이벤트가 저장되는 공간이다. 토픽은 관련 이벤트를 그룹화하고 영구적으로 저장한다. 매우 단순하게 보면, 토픽은 파일 시스템의 폴더고, 이벤트는 해당 폴더의 파일이다.
위에서 예로 든 이벤트의 토픽은 ‘계좌이체’가 될 수 있다. 하나의 토픽에 여러 프로듀서가 이벤트를 발행할 수 있고, 여러 컨슈머가 하나의 토픽을 구독해서 이벤트를 읽을 수 있다.
기존 메시징 시스템과 달리 이벤트는 소비 후 삭제되지 않기 때문에 토픽의 이벤트는 필요한 만큼 여러 번 읽을 수 있다.
Kafka는 토픽 별로 이벤트 유지 기간을 설정할 수 있고, 해당 기간이 지나면 이벤트는 자동으로 삭제된다. 토픽 이름 자체가 고유한 식별자로 기능한다.
•
파티션(partition) : Kafka의 토픽은 여러 파티션으로 나눠진다. 토픽이 Kafka의 논리적 개념이라면, 파티션은 토픽에 속한 이벤트가 저장되는 가장 작은 물리적 저장 단위다. 파티션에 저장되는 이벤트를 레코드라고 부르며, 토픽을 생성할 때 파티션 수를 지정할 수 있다.
•
오프셋(offset) : 파티션의 레코드에는 오프셋이라는 파티션 내에서 고유하고 순서 정보를 가진 식별자가 할당된다. 오프셋은 변경 불가능한 숫자로 Kafka에서 관리되며, 무한하게 증가한다. 오프셋 값의 순서는 파티션 내에서만 보장되고, 토픽의 전체 파티션 대상으로는 순서가 보장되지 않는다.
1.2.4 Kafka 브로커(Broker)
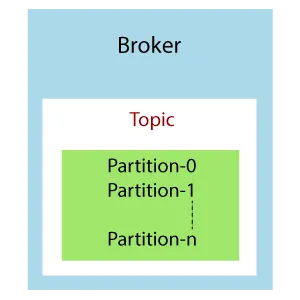
Kafka 클러스터는 하나 이상의 브로커 서버로 구성된다. 브로커는 여러 토픽을 갖고 있는 컨테이너로, 토픽은 여러 파티션을 가질 수 있다. 클러스터의 브로커는 정수 번호로만 식별된다.
Kafka 브로커는 부트스트랩 브로커 라고도 한다. 하나의 브로커와 연결되면 전체 클러스터와 연결되기 때문이다. 브로커가 전체 Kafka 데이터를 포함하지는 않지만, 클러스터의 각 브로커는 다른 모든 브로커와 해당 브로커가 가진 파티션 및 토픽에 대해 알고 있다.
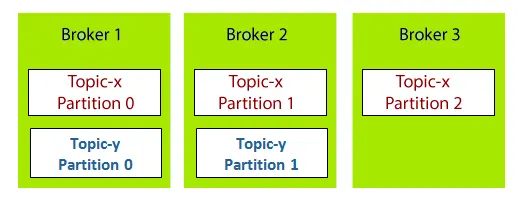
예를 들어 Broker 1, Broker 2, Broker 3 세 개의 브로커로 구성된 Kafka 클러스터를 가정해보자. 각 브로커는 Topic-x라는 토픽을 갖고 있다. Topic-x의 모든 파티션은 하나의 브로커에만 속하지 않고, 여러 브로커에 분산된다. 브로커 1과 브로커 2에는 Topic-y가 포함되어 있는데, Topic-y는 파티션 수가 2개이기 때문에 두 개의 브로커에만 분산된 것이다. 즉 브로커 번호와 파티션 번호 사이에는 어떠한 관계도 존재하지 않는다는 것을 알 수 있다.
1.2.5 Kafka 클라이언트 API
Kafka 프로젝트에서 공식 지원하는 API는 다음과 같은 종류가 있다.
•
Producer API : 하나 이상의 토픽에 이벤트를 발행하는 프로듀서 클라이언트를 만들고 싶을 때. Kafka에 데이터를 write 하는 가장 낮은 수준의 API
•
Consumer API : 하나 이상의 토픽을 구독하고, 가져온 이벤트 스트림을 처리하는 컨슈머 클라이언트를 만들고 싶을 때. Kafka로부터 데이터를 read 하는 가장 낮은 수준의 API
•
Streams API : kafka에 대한 입력 출력을 stream 으로 처리하는 API. producer, consumer 를 내부적으로 이용하고, 더 추상화된 고수준의 API를 제공
•
Connector API : 기존 데이터 시스템 또는 애플리케이션과 Kafka 사이의 데이터 이동을 쉽게 할 수 있도록 제공하는 고수준의 API. Connector의 목적은 Consumer/Producer 클라이언트를 만들지 않고도 쉽게 Kafak와 외부 시스템 간에 데이터 스트리밍을 할 수 있도록 돕는 것.
1.3 Kafka 설치
Kafka 브로커 3개로 Kafka 클러스터를 구축해보자. 일반적으로 Kafka는 Zookeeper를 사용하여 Kafka 클러스터에 대한 모든 메타데이터 정보를 저장하고 관리하며, Zookeeper를 모든 Kafka 브로커 또는 서버를 관리하고 구성하는 중앙 집중식 컨트롤러로 사용한다.
그러나 최신 Kafka 버전에서는 모든 서버 구성 정보를 Zookeeper에 저장하는 대신 Kafka 서버 내부의 토픽 파티션으로 저장할 수 있다. Zookeeper 없이 Kafka를 시작하려면 KRaft와 같은 Kafka Raft 메타데이터 모드로 Kafka를 실행해야 한다.
브로커와 컨트롤러 역할을 모두 수행하는 Kafka 서버를 “combined” 서버라고 라는데, combined 서버는 테스트 및 개발 환경에서 사용할 것을 권장한다. combined 모드에서는 브로커와 별도로 컨트롤러만 스케일 아웃할 수 없기 때문이다.
1.3.1 AWS EC2 인스턴스 생성
AWS 콘솔에서 EC2 인스턴스 3개를 생성하자. 인스턴스 유형은 t2.xlarge, 스토리지는 32GiB, 보안 그룹은 인/아웃바운드 모두 전체 허용으로 설정하면 된다.