
Spark의 등장 배경 - Hadoop의 한계
Hadoop 간단 설명
Hadoop의 등장 배경
•
기술이 진화 함에 따라 데이터의 양이 급격하게 증가하기 시작
•
데이터를 통한 정량적 의사결정의 필요성의 증가
→ 큰 데이터를 처리할 수 있는 방법이 필요해짐.
Hadoop : 대용량 분산 저장 프레임워크
•
HDFS : 데이터를 저장하는 컴포넌트
◦
Hadoop Distributed File System
◦
한 개의 파일을 block 단위로 쪼개 각기 다른 기기에 분산 저장
•
YARN : 컴퓨팅 리소스를 관리하는 컴포넌트
◦
데이터를 분산 시켜 저장하는 기기들의 CPU, RAM과 같은 자원 정보를 관리
◦
연산을 처리하기 위해 어느 기기에 어떤 job을 배치할 지에 대한 스케쥴링 담당
•
Map/Reduce : Hadoop이 지원하는 데이터 연산 컴포넌트
◦
대용량 데이터를 어떻게 처리할지를 결정하는 API
◦
크게 Mapper와 Reducer로 구성됨
▪
Mapper : 전체 데이터를 (key, value)로 묶는 연산
▪
Reducer : Mapper에서 연산한 데이터를 묶고 정리하는 연산
HDFS에서의 MapReduce의 단점
•
번거로운 운영 복잡도로 인해 관리가 쉽지 않음.
•
일반적인 배치 처리를 위한 맵리듀스 API는 장황하고 많은 양의 기본 셋업 코드를 필요로 하며 장애 대응이 불안정함.
•
방대한 배치 데이터 작업을 수행하면서 많은 M/R 태스크가 필요해지면 각 태스크는 이후 단계를 위해 중간 과정을 데이터를 로컬 디스크에 작성해야 함.
→ 디스크 I/O 작업은 실행 시간을 느리게 함.
•
Hadoop M/R은 일반적인 배치 처리를 위한 대규모 작업에는 적당하지만 ML, Streaming, SQL 계통의 질의가 필요한 상황 등 다른 워크로드와 연계하는 것에 한계를 가짐.
Spark의 기본 개념
•
대규모 분산 처리를 위해 설계된 통합형 엔진
•
중간 연산을 위해 메모리 저장소를 지원하여 Hadoop MapReduce보다 훨씬 빠르게 동작
•
ML, SQL, Streaming 처리, Graph 처리 등을 위해 쉽게 사용 가능한 API로 이루어진 라이브러리를 가짐
Spark의 기본 철학 : 속도, 사용 편리성, 모듈성, 확장성
속도
•
스파크는 질의 연산을 방향성 비순환 그래프(DAG, directed acyclic graph)로 만들어 구성함. 이를 통해 사용자가 작성한 연산을 효율적인 연산 그래프로 만들어서, 독립된 태스크로 분해 후, 클러스터의 워커 노드에서 병렬 수행될 수 있도록 함.
•
물리적 실행 엔진인 텅스텐(Tungsten)으로 실행을 위한 간결한 코드를 생성해냄.
→ 연산을 최적화해줌
•
모든 중간 결과는 메모리에 유지되며, 디스크 I/O를 제한적으로 사용하므로 실행 속도 측면에서 성능이 크게 향상함.
사용 편리성
•
DataFrame이나 DataSet와 같은 고수준 데이터 추상화 계층 아래에 유연한 분산 데이터 세트(RDD, resilient distributed dataset)이라 불리는 단순한 논리 자료구조를 구축하여 단순성을 실현
•
연산의 종류를 트랜스포메이션(transformation)와 액션(action)으로 구분
•
단순한 프로그래밍 모델을 제공함으로써 사용자들이 각자 편한 언어로 Spark를 사용할 수 있도록 함.
모듈성
•
문서화가 잘 된 API로 이루어진 통합 라이브러리를 제공. 핵심 컴포넌트로 Spark SQL, Spark Streaming, Spark MLlib, GraphX를 가짐.
•
스파크 연산은 다양한 타입의 워크로드(배치 처리, 스트리밍 처리 등)에 적용 가능하며, 지원하는 모든 프로그래밍 언어로 사용 가능함. (Scala, java, python, SQL, R)
확장성
•
스파크는 저장보다는 빠른 병렬 연산 엔진에 초점이 맞춰짐.
•
저장과 연산을 모두 포함하는 Apache Hadoop과는 달리 연산에 집중.
◦
“스파크는 하둡이 아닌, 하둡의 MapReduce를 대체하는 용도이다.”
•
따라서, 다양한 데이터 소스를 통해 데이터를 읽고, 쓸 수 있다.
◦
Kafka, Kinesis, Azure, AWS S3, Hadoop hdfs 등
Spark Component
Spark Core
•
범용 분산 데이터 처리 엔진
•
전체 프로젝트의 기반으로서 분산된 작업 디스패치, 예약, 기본 I/O 기능을 제공
Spark SQL
•
구조화된 데이터와 동작
•
RDBMS, 구조화된 데이터의 파일 포맷(csv, JSON 등)을 가진 데이터를 불러들여 쿼리를 날릴 수 있도록 해줌.
Spark MLlib
•
Spark 확장형 머신러닝 라이브러리
•
MLlib에는 분류, 회귀분석, 추천 및 클러스터링 등 일반적인 학습 알고리즘이 존재하여 쉽게 분석가능함.

아파치 스파크 1.6을 시작으로, MLlib 프로젝트는 spark.mllib와 spark.ml 두 패키지로 분리되었다. 전자는 RDD 베이스 기반 API이고, 후자는 데이터 프레임 기반 API이다. 전자는 유지보수 모드이며 새로운 기능은 모두 spark.ml로 들어간다.
Spark Streaming
•
Stream 데이터를 처리할 수 있게 해주는 라이브러리
GraphX
•
그래프의 병렬 계산을 가능하게 해주는 라이브러리
•
추출/변환/로드와 탐색 분석, 반복적 그래프 계산이 한 시스템 내에 통합되어 있음.
Spark 기본 아키텍처
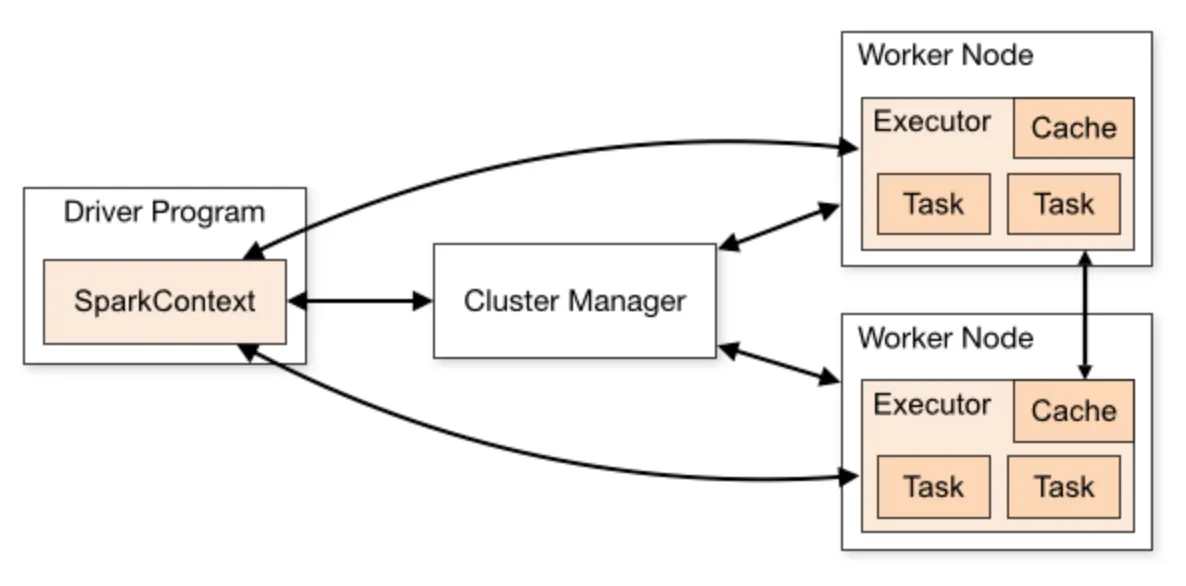
Spark Driver
•
스파크 애플리케이션을 실행하는 프로세스
•
main 함수를 실행하고, 스파크 컨텍스트(SparkContext) 객체를 생성함.
•
스파크 애플리케이션의 라이프 사이클을 관리하고, 사용자로부터 입력을 받아서 각 애플리케이션에 전달하며, 작업 처리결과를 사용자에게 알려줌.
Spark executor
•
실제 태스크(task) 실행을 담당.
•
YARN의 컨테이너와 비슷한 역할.
•
익스큐터는 태스크 단위로 작업을 실행하고, 결과를 드라이버에게 알려줌.
•
익스큐터가 동작 중 오류가 발생하면 다시 재작업을 진행
Cluster Manager
•
스파크 애플리케이션이 실행되는 클러스터에서 자원을 관리 및 할당하는 역할.
•
아래의 4가지 클러스터 매니저를 지원
종류 | 설명 |
StandAlone(내장 단독) | - 스파크에서 자체적으로 제공하는 클러스터 매니저
- 각 노드에서 하나의 익스큐터만 실행 가능 |
YARN(얀) | - 하둡 클러스터 매니저
- 리소스 매니저, 노드 매니저로 구성됨. |
Mesos(메소스) | - 동적 리소스 공유 및 격리를 사용하여 여러 소스의 워크로드를 처리
- 아파치의 클러스터 매니저
- 마스터와 슬레이브로 구성됨 |
Kubernetes(쿠버네티스) | - 쿠버네티스의 마스터 |
SparkSession
•
스파크 응용 프로그램의 진입점.
•
스파크 2.0 이전에는 SparkContext가 스파크 애플리케이션의 집합점이였음.
•
SparkSession을 통해 SparkContext, SQLContext, HiveContext, SparkConf, StreamingContext 등 다른 컨텍스트들을 한 곳에 통합시킴.
→ 결론 : Spark의 어떤 기능을 사용하던 SparkSession을 생성해주어야 한다.
•
SparkSession과 SparkContext의 차이점에 대한 더 읽어볼거리
•
SparkSession 생성 코드
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("DataFrame").getOrCreate()
Python
복사
Spark의 데이터 구조 : RDD, Dataframe, Dataset
RDD(Resilient Distributed Data) - Spark 1.0
•
Resilient(회복력있는, 변하지 않는), Distributed(분산된) Data(데이터)
◦
Resilient : 메모리 내부에서 데이터가 손실되면 유실된 파티션을 재연산해 복구. Read Only.
◦
Distributed : 스파크 클러스터를 이용하여 메모리에 분산되어 저장 및 처리
◦
Data : 데이터
•
RDD Lineage(혈통)
◦
RDD는 Resilient(불변의) 속성을 가지는데(Read Only), 그로 인해 데이터 처리 중 RDD를 변형, 집계하는 과정에서 새로운 RDD를 생성하게 됨.
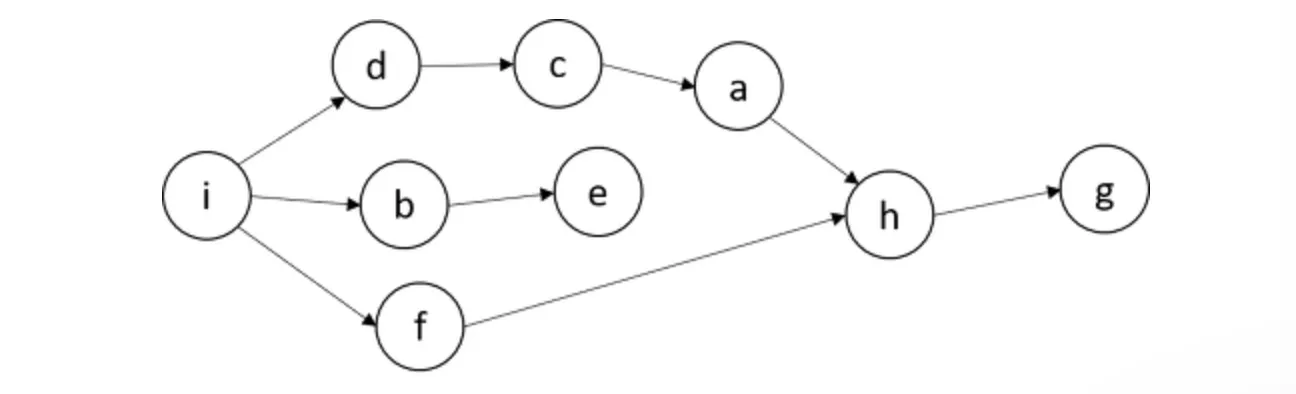
◦
스파크는 이러한 과정을 위의 그림처럼 DAG(Directed Acyclic Graph, 비순환 그래프) 형식으로 표현을 하고, 이것을 RDD Lineage라고 함.
◦
특정 RDD 관련 정보가 메모리에서 유실되었을 경우에 이전 단계의 RDD 정보를 가져옴으로써 빠르게 복구가 가능해짐.
◦
이러한 특징 덕분에 Spark는 Fault-tolerant를 보장하게 됨.
▪
Fault-tolerant(장애 허용 시스탬) : 시스템을 구성하는 부품의 일부에서 결함 또는 고장이 발생하여도 정상적 혹은 부분적으로 기능을 수행할 수 있는 시스템
•
Transformation(변환) 과 Action(액션)

◦
RDD 연산은 Transformation과 Action으로 구분되며, 스파크는 Transformation을 호출할 때는 작업을 구성하고, Action이 호출될 때는 실제 계산을 실행하게 됨(lazy-execution).
◦
실제로 하고자 하는 작업의 큰 틀을 잡은 상태에서, 자원 배분 등을 고려하여 실제 실행 계획을 세운 뒤 연산을 진행함으로써 좀 더 효율적인 연산 수행.
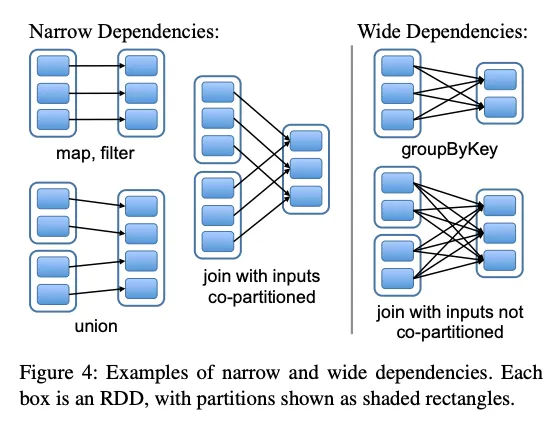
◦
내부 과정을 간단히 설명을 하자면, 위와 같이 이전 RDD와 다음 RDD의 종속성(dependency)을 Narrow와 Wide로 구분한 뒤,
◦
재연산이 더 빠른 경우(Narrow)에는 중간 결과를 저장하지 않고, 재연산을 했을 때 더 오래걸리는 경우(Wide)에는 중간 결과를 저장(checking point)해놓는 전략을 취함.
Narrow와 Wide의 재연산 속도가 차이가 나는 이유는 Narrow Dependency 상황에서는 하나의 RDD만 참고하기 때문에 하나의 노드에서만 작업이 가능하므로 네트워크 통신이 필요없다. 하지만, Wide Dependency 상황에서는 여러개의 RDD를 참고해야 하므로 네트워크 통신이 필요해짐으로 시간이 오래걸리게 된다.
→ 이러한 성질 때문에 hadoop을 in-memory로 돌리더라도 spark가 더 좋은 성능을 보임.
Dataframe - Spark 1.3
•
pandas의 DataFrame과 유사함.
•
RDD와 같이 변경 할 수 없는 데이터 집합. 연산이 Transformation과 Action으로 구분되며 Catalyst Optimizer를 통해 실제 연산 과정이 최적화됨.
•
RDB 처럼 Schema를 가지고 있으며기에 SQL을 이용하여 쿼리를 통한 분석이 가능
Dataset - Spark 1.6
•
java, scala를 이용하여 Spark를 이용할 때 사용 가능
•
JVM 객체에 대한 바인딩으로 Encoder를 사용하여 유형별 JVM 객체를 Tungsten의 내부 메모리 표현으로 mapping한다. 결과적으로 encoder를 통해 JVM 객체를 효율적으로 직렬화/비직렬화 할 수 있으며 소형의 바이트 코드를 생성하게 됨으로써 cache size 축소 및 처리시간과 관련하여 성능을 개선할 수 있음.
실습 세팅
git clone https://github.com/YunSeo00/BOAZ_MANMAN_A.git
Python
복사
docker-compose up
Python
복사
Spark RDD 및 Dataframe 실습
•
RDD.ipynb 파일 실행
•
Dataframe.ipynb 파일 실행
•
postgreSQL container 접속 후 저장된 데이터 확인
docker exec -it boaz_manman_a-postgres-1 /bin/bash
psql -U boaz -d boaz
\dt # table 확인
select * from boaz_engin_a; # 내용 확인
Python
복사






