RDD(Resilient Distributed Dataset) - 탄력적인 분산 데이터셋..?
RDD의 5가지 특징
1.
데이터 추상화
데이터는 클러스터에 흩어져있지만 하나의 파일인것 처럼 사용이 가능하다.
2.
Resilient & Immutable
탄력적이고 불변하는 성질이 있다. 데이터의 연산을 실행하는 여러 노드 중 하나가 망가진다면? 네트워크 장애, 하드웨어/메모리 문제 등이 발생. Immutable하면 문제의 복원이 가능해진다.


탄력적이다
3.
Type-safe
•
Integer RDD
•
String RDD
•
Double RDD
컴파일시 Type을 판별할 수 있어 문제를 일찍 발견할 수 있다.
4.
Unstructured/Structured Data

5.
Lazy
게으르다 - 결과가 필요할 때까지 연산을 하지 않는다.
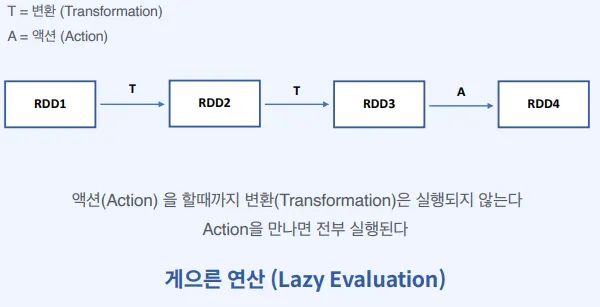
•
Spark Operation은 두가지로 나뉠 수 있다.
Spark Operation = Transform + Action
왜 RDD를 쓸까
•
유연하다
•
짧은 코드로 할 수 있는게 많다
•
개발할때 무엇보다는 어떻게에 대해 더 생각하게 한다 (how-to)
•
게으른 연산 덕분에 데이터가 어떻게 변환될지 생각하게 된다
•
데이터가 지나갈 길을 닦는 느낌