1. Docker로 ELK 환경 설치

이론 설명 듣기전에 미리 설치하기!!!
원하는 폴더 경로 들어간다음,
$ git clone https://github.com/deviantony/docker-elk.git
$ cd docker-elk
$ docker-compose up setup
$ docker-compose up -d
Bash
복사
기본포트 정보
•
9200 : ElasticSearch
•
5601: Kibana
docker-compose up -d 명령어 이후
1.
Elasticsearch 접속 확인
localhost:9200 접속
Bash
복사
•
사용자 이름 : elastic
•
비밀번호 : changeme
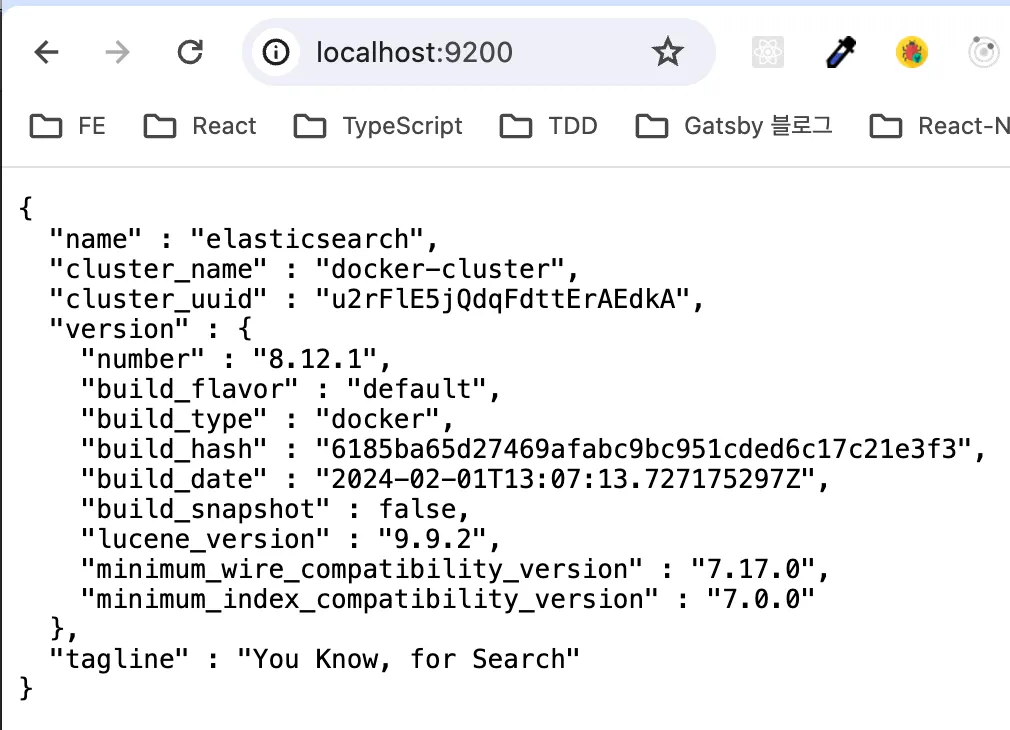
다음 결과 보이면 es 설치 성공
2.
Kibana 접속 확인
localhost:5601 접속
Bash
복사
•
사용자 이름 : elastic
•
비밀번호 : changeme
다음 화면 보이면 Kibana 설치 성공
2. Index 생성
Kibana Console 접속
localhost:5601 -> 왼쪽 메뉴 -> Management -> Dev Tools
Bash
복사
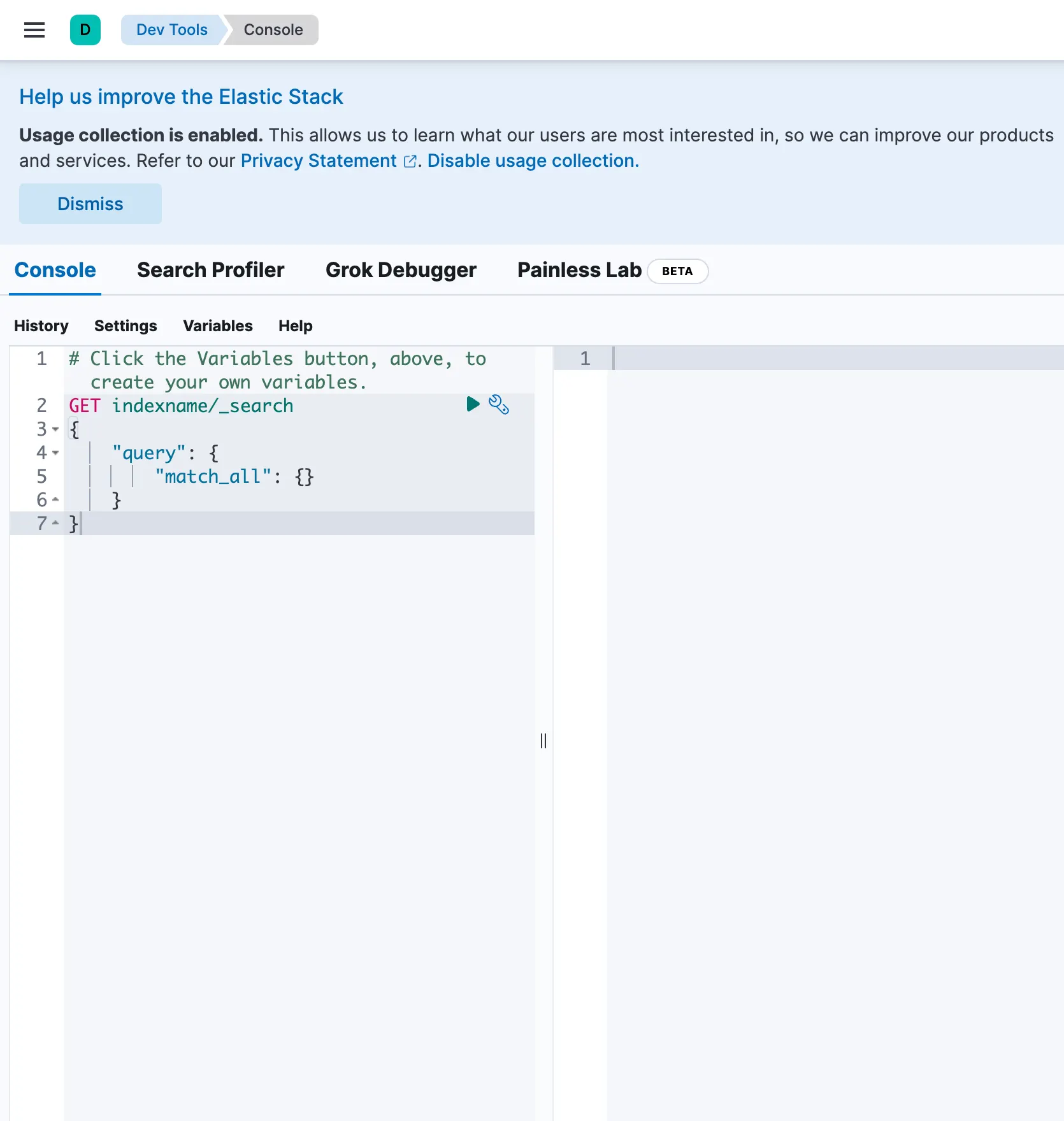
왼쪽에서 코드 입력 → 오른쪽에서 결과 확인
PUT sample_index
{
"settings": {
"index": {
"number_of_shards": 1,
"number_of_replicas": 1
}
},
"mappings": {
"properties": {
"word": {
"type": "text"
}
}
}
}
GraphQL
복사
Index 구조
다음 코드 입력하여 생성된 index 정보 확인
GET sample_index
GraphQL
복사
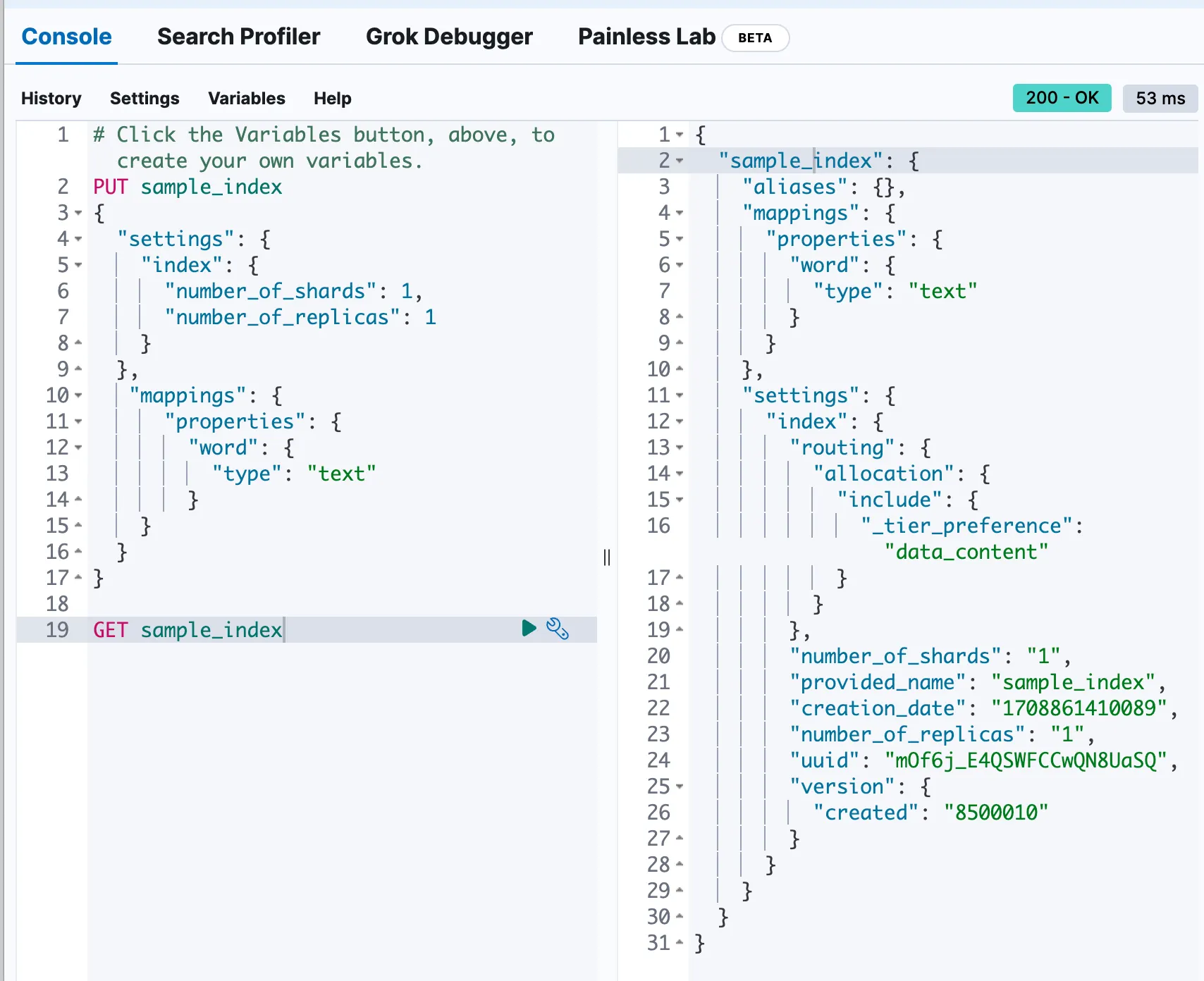
다음과 같은 결과 뜨면 성공!
3. logstash를 통해 db 데이터 가져오기
1.
mysql jdbc driver 설치
2.
압축해제 후, jar 파일 찾아서 다음 경로에 넣기
# jar 파일 위치
mysql-connector-java-8.0.30/src/mysql-connector-java-8.0.30.jar
Bash
복사
3.
docker-elk/logstash 경로 내에 plugin 폴더 생성 후, jar 파일 복사
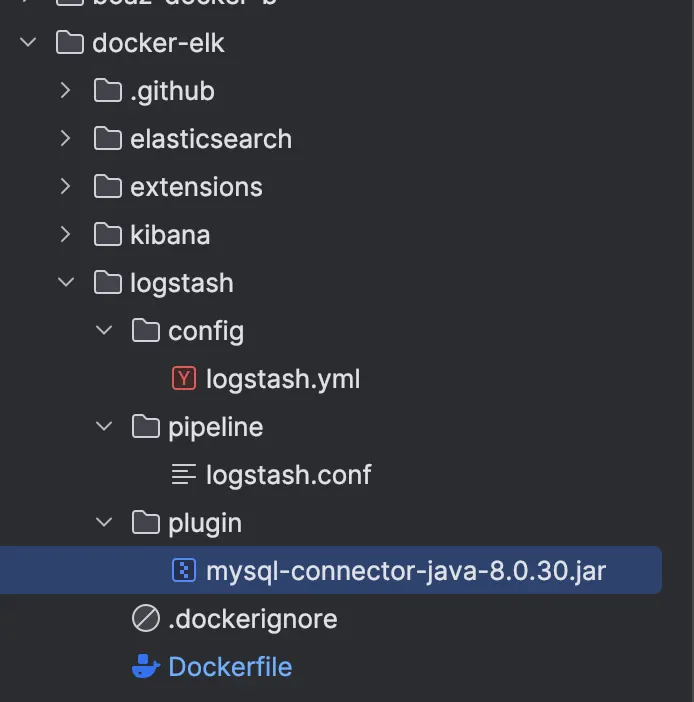
4.
docker-compose.yml 의 logstash : volumes 부분에 한 줄 추가
...
...
...
logstash:
build:
context: logstash/
args:
ELASTIC_VERSION: ${ELASTIC_VERSION}
volumes:
- ./logstash/config/logstash.yml:/usr/share/logstash/config/logstash.yml:ro,Z
- ./logstash/pipeline:/usr/share/logstash/pipeline:ro,Z
- ./logstash/plugin/mysql-connector-java.8.0.30.jar:/usr/share/logstash/jdk/mysql-connector-java-8.0.30.jar:ro,Z
# 3번째 항목 추가
...
...
...
YAML
복사
5.
logstash.conf 파일 수정
# logstash/pipeline/logstash.conf
# 해당 파일을 통해 rdb connection 수립 후, 지정된 host로 db 전송
input {
jdbc {
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_driver_library => "/usr/share/logstash/jdk/mysql-connector-java-8.0.30.jar"
jdbc_connection_string => "jdbc:mysql://my-rds-db.cz0kgkmmo5si.ap-northeast-2.rds.amazonaws.com:3306/elasticsearch_DB?useSSL=false"
jdbc_user => "admin"
jdbc_password => "espractice"
statement => "SELECT * FROM elasticsearch_DB.word_table"
schedule => "*/10 * * * * *" # 10초마다 데이터 fetch
}
}
## Add your filters / logstash plugins configuration here
output {
elasticsearch {
hosts => ["http://elasticsearch:9200"]
index => "sample_index"
user => "elastic"
password => "changeme"
document_id => "%{id}"
}
}
Bash
복사
•
input
◦
jdbc를 통한 rds mysql 연결
◦
statement : SQL문을 통해 원하는 데이터 select
◦
schedule: cron 표현식(초/분/시/월/일/요일)으로 데이터 가져오는 주기 설정
•
ouput
◦
host : 데이터를 보내려는 elasticsearch의 주소
◦
index : 생성하려는 index 이름 → 이미 존재하는 index면 거기로 저장됨
◦
document_id : index 내 문서의 키 값 → 중복되면 데이터 저장 안됨
6.
container recreate (yml 파일 변경하였기 때문)
$ docker-compose up --build --force-recreate -d
Bash
복사
Retrying individual bulk actions that failed or were rejected by the previous bulk request.
7.
kibana 를 통해 index에 들어온 데이터 확인
localhost:5601 -> 왼쪽 메뉴 -> Management -> Stack Management
Bash
복사
해당 화면 접속 후,
Management 메뉴 -> Data의 Index Management
Bash
복사
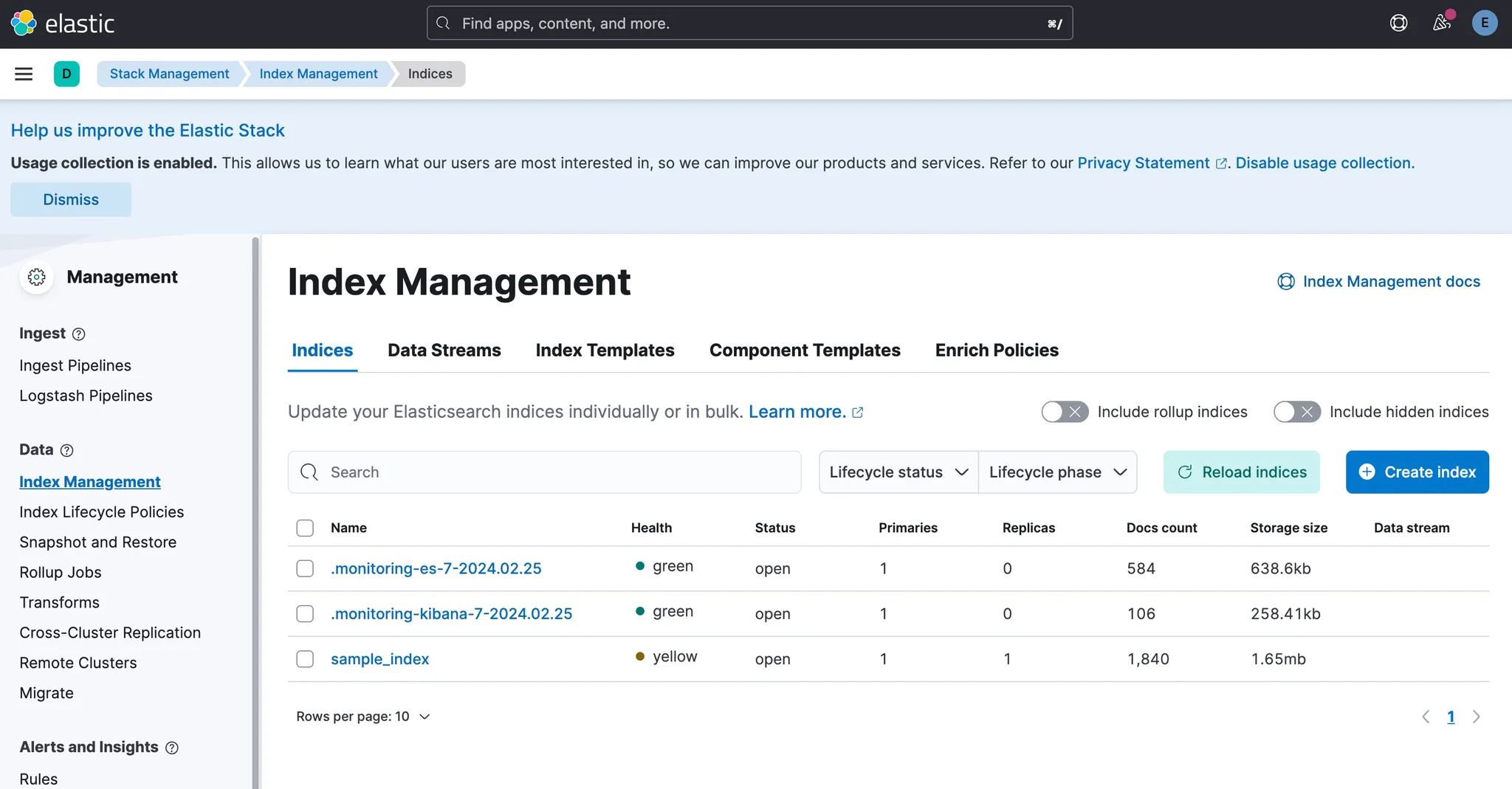
다음과 같이 sample_index 의 Docs count 값이 1840이면 성공
Dev Tools 에서도 확인 가능
localhost:5601 -> 왼쪽 메뉴 -> Management -> Dev Tools
YAML
복사
다음 명령어 실행
GET sample_index/_search
GraphQL
복사
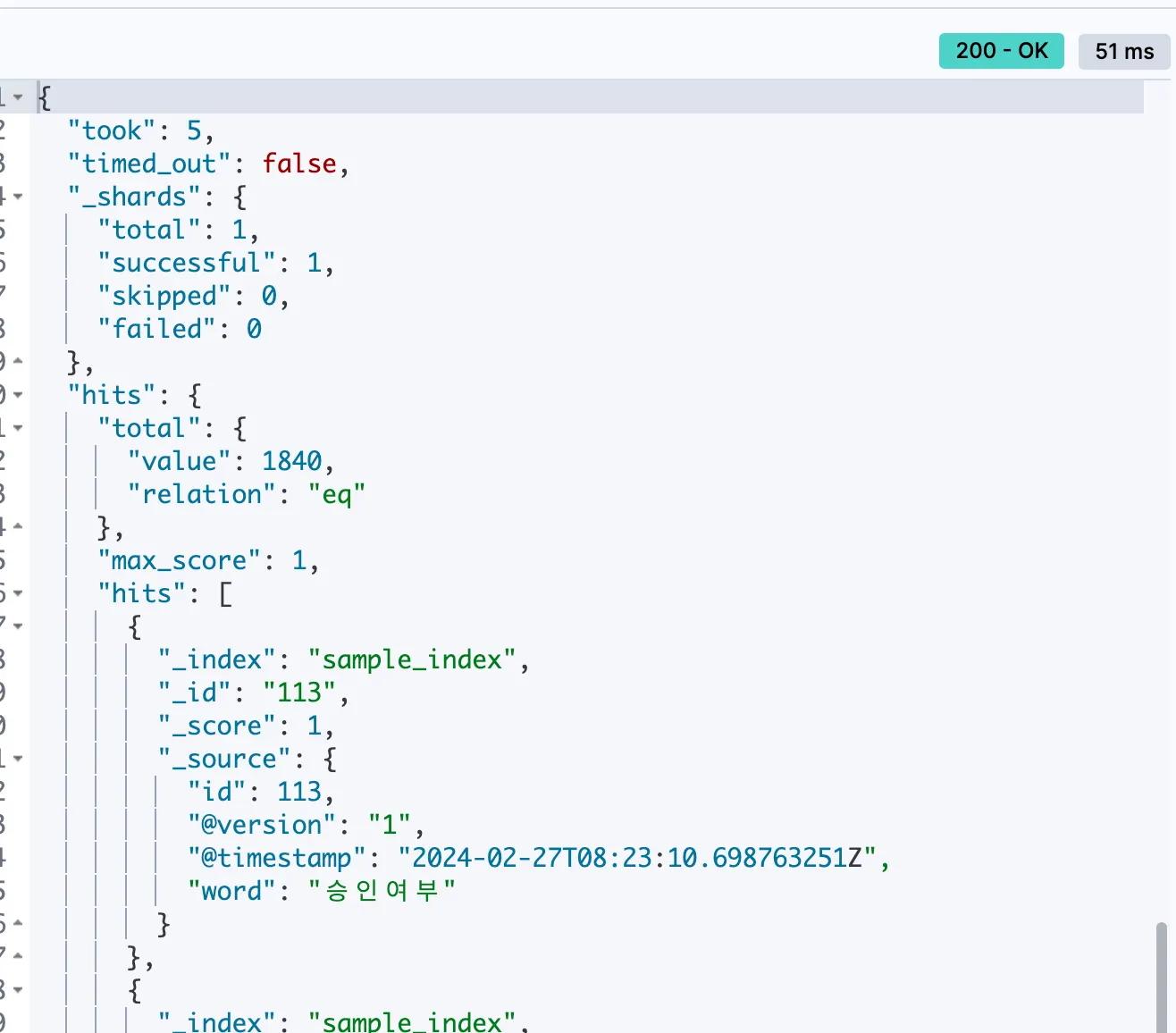
hits.total.value 값이 1840이면 성공
4. nori tokenzier 를 통한 한글 검색
nori tokenizer란?
1. elasticsearch container 접속 후 nori tokenizer 설치 및 적용
$ docker ps -a
Bash
복사
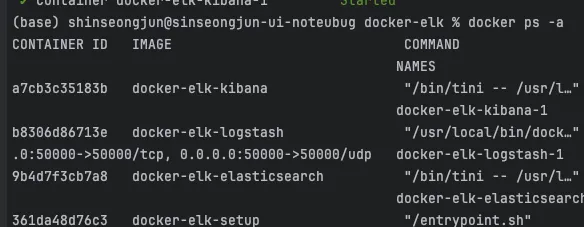
docker-elk-elasticsearch의 CONTAINER ID 값 알아낸 다음, 컨테이너 접속
$ docker exec -it b8306d86713e bash
Bash
복사
다음 명령어로 nori plugin 설치 → bin/elasticsearch-plugin install analysis-nori
elasticsearch@9b4d7f3cb7a8:~$ bin/elasticsearch-plugin install analysis-nori
Bash
복사
설치 후, 다시 프로젝트 경로로 돌아와 elasticsearch 컨테이너 재시작
elasticsearch@9b4d7f3cb7a8:~$ exit
$ docker-compose restart elasticsearch
Bash
복사
Kibana Dev Tools에서 nori 분석기 잘 설치되었는지 확인 가능
GET _analyze
{
"text": ["건강보험가입여부"],
"tokenizer": "nori_tokenizer"
}
GraphQL
복사
결과가 다음과 같이 나온다면 nori 설치 성공

2. Index에 nori 분석기 적용
•
settings : nori 적용된 analyzer 및 tokenizer 설정
•
mappings : 문서 내 원하는 field에 nori analyzer 적용
DELETE sample_index
PUT sample_index
{
"settings": {
"analysis" : {
"analyzer": {
"nori": {
"type": "custom",
"tokenizer": "nori_mixed"
}
},
"tokenizer": {
"nori_mixed": {
"type": "nori_tokenizer",
"decompound_mode": "mixed"
}
}
}
},
"mappings": {
"properties": {
"word" : {
"type" : "text",
"analyzer" : "nori"
}
}
}
}
GraphQL
복사
한 번 생성된 index면 settings, mappings 정보 변경 불가하므로, 삭제한 후 다시 생성
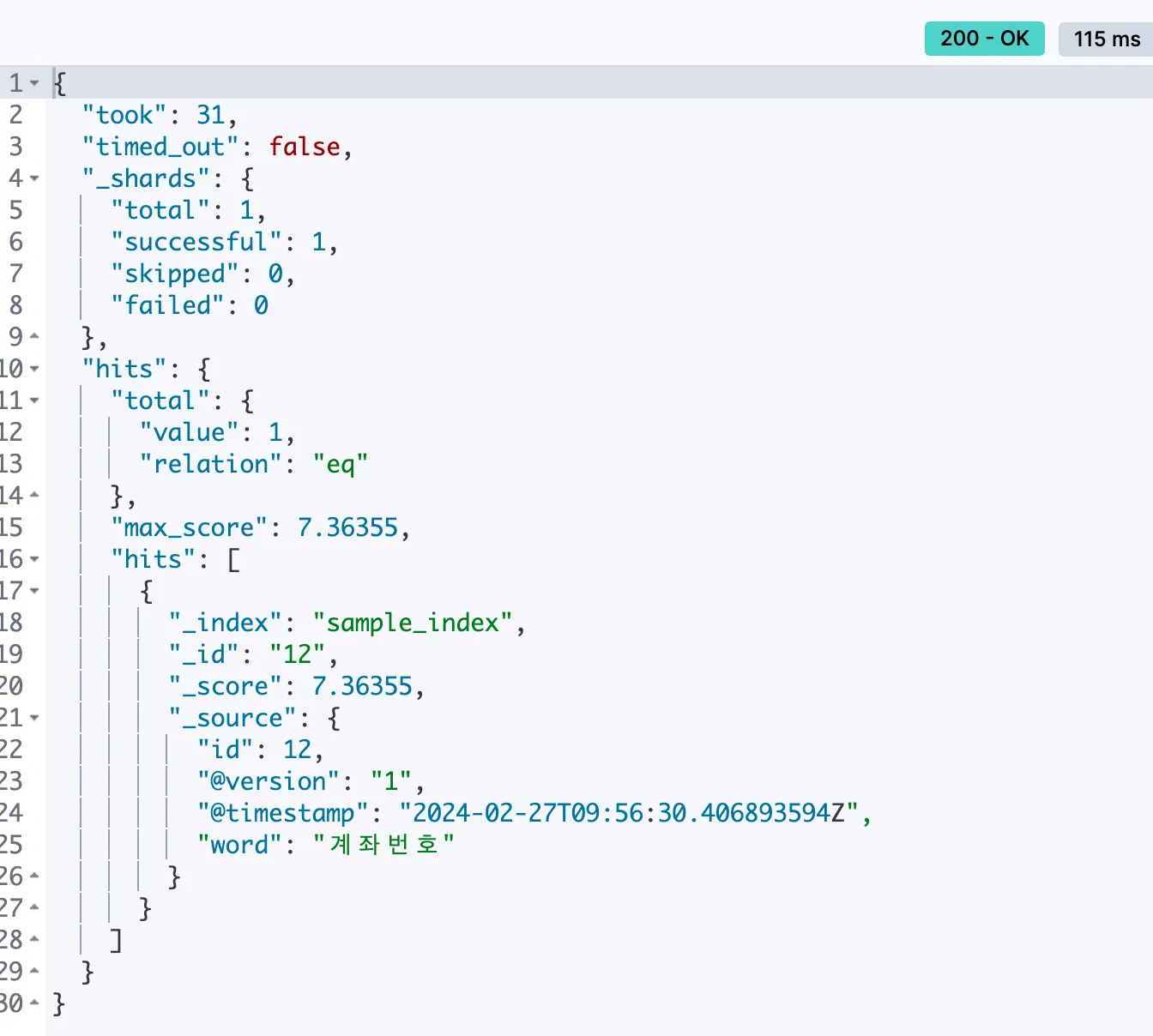
3. nori 적용된 검색 결과 비교 - match vs term
일반적인 QueryDSL 로 검색한다면, 대부분 match 나 term 쿼리를 베이스로 작성
GET sample_index/_search
{
"query": {
"match": {
"word": "계좌"
}
}
}
GET sample_index/_search
{
"query": {
"term": {
"word": "계좌"
}
}
}
GraphQL
복사
둘의 차이점
•
match 쿼리 : 지정한 필드에 analyzer가 존재하면 질의어 또한 analyzing 과정을 거친다.
•
term 쿼리 : analyzer 처리 과정을 거치지 않는다.
GET sample_index/_search
{
"query": {
"match": {
"word": "계좌번호"
}
}
}
GET sample_index/_search
{
"query": {
"term": {
"word": "계좌번호"
}
}
}
GraphQL
복사
•
match 쿼리 : “계좌”, “번호”로 분석되어 검색
•
term 쿼리 : “계좌번호”로 검색
Q. “계좌번호” 값이 index에 있는데 term 쿼리 결과가 나오지 않는 이유??
A. “word” 필드가 “text” 타입으로 되어있기 때문
•
text 필드 타입 : 형태소 분석을 통해서 색인 키를 가지게 된다.
→ 따로 설정이 없으면 standard analyzer로 색인되는데 기본적으로 불용어, lowercase, whitespace로 색인
ex) 스팀게임 추천 : “스팀게임”, “추천” 2개의 단어로 키가 잡힌다.
•
keyword 필드 타입 : 텍스트 자체를 키로 색인
ex) 스팀게임 추천 : “스팀게임 추천” 으로 저장됨.
다음 명령어로 keyword 타입 field 추가 가능
DELETE sample_index
PUT sample_index
{
"settings": {
"analysis" : {
"analyzer": {
"nori": {
"type": "custom",
"tokenizer": "nori_mixed"
}
},
"tokenizer": {
"nori_mixed": {
"type": "nori_tokenizer",
"decompound_mode": "mixed"
}
}
}
},
"mappings": {
"properties": {
"word" : {
"type" : "text",
"analyzer" : "nori",
"fields": {
"keyword": {
"type": "keyword"
}
}
}
}
}
}
GraphQL
복사
keyword 필드 추가 후, 다음과 같이 검색하면 계좌번호 결과가 정상적으로 나온다.
GET sample_index/_search
{
"query": {
"term": {
"word.keyword" : "계좌번호"
}
}
}
GraphQL
복사