

1. Elastic Stack 이란?
Elastic Stack은 데이터 분석에 필요한 모든 유형의 데이터를 실시간으로 검색, 분석, 시각화할 수 있는 Elastic의 오픈소스 데이터 분석 플랫폼을 말한다.
과거에는 “Elasticsearch”, “Logstash”, “Kibana”의 맨 앞글자를 활용해서 ELK Stack으로 불렸지만, 현재는 “Beats”등 여러 기술이 추가되면서 Elastic Stack이라는 이름으로 부르고 있다.
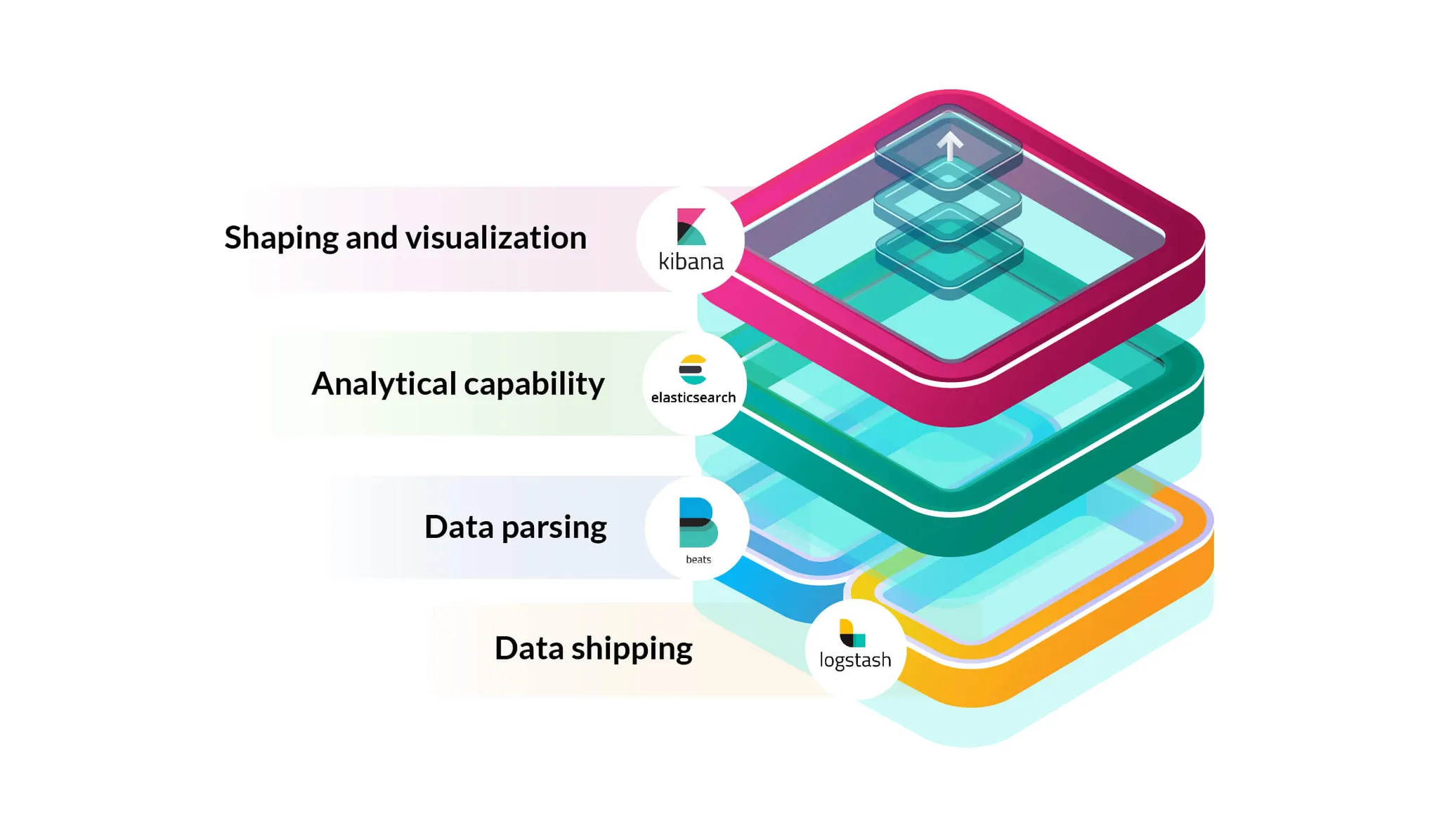

Beats, Logstash : 데이터를 수집하고 가공
Elasticsearch : 데이터 저장 및 분석
Kibana : 시각화 및 모니터링
1.1 Elasticsearch - 데이터 관리(저장/검색/분석)

elasticsearch는 검색 엔진 이면서 데이터 베이스이기도 하다.
•
Indexing
elasticsearch는 모든 레코드를 JSON 도큐먼트 형태로 입력하고 관리하며, 도큐먼트를 인덱싱해 쿼리 결과에 일치하는 원본 도큐먼트를 반환한다. 텍스트 외에도 숫자, 날짜, IP 주소, 지리 geo 정보 등 다양한 데이터 타입에 대해 최적화되어 있다.
•
병렬 처리, 분산 처리
elasticsearch는 텍스트나 도큐먼트의 경우 인덱싱 시점에 분석을 거쳐 용어 단위로 분해하고 역인덱스 사전을 구축한다. 숫자나 키워드 타입의 데이터들은 집계에 최적화된 칼럼 기반 자료구조를 저장한다. 최적화된 자료구조를 바탕으로 병렬처리나 분산처리를 할 수 있다. 클러스터가 구성되어 있다면 데이터 양과 무관하게 1초 이내의 응답을 기대할 수 있다.
분산 시스템으로서 elasticsearch는 복수의 인스턴스를 병렬로 배치하고 분산 처리해 검색 속도를 무한히 확장할 수 있게 한다. 또한, 노드 간 복제 기능을 통해 일부 노드가 다운되더라도 정상적으로 서비스를 지속할 수 있게 한다.
•
Lucene 기반 검색 엔진 (최적화된 자료구조 지원, scoring 등..)
elasticsearch는 루씬(Lucene)기반 검색엔진으로서 강력한 기능들을 가지고 있다. 그 중 하나가 scoring, 연관도에 따른 정렬이다. 검색어에 대해 유사도 스코어를 기반으로 한 정렬을 제공한다. 이것은 문자열 콘텐츠에서 검색을 수행할 때 강력한 기능이 된다.
•
REST API
elasticsearch의 편리한 점은 모든 통신을 REST API를 이용하도록 만들어 프로그래밍 언어와 무관하게 활용할 수 있다는 것이다. 별도의 드라이버 라이브러리가 없더라도 웹 브라우저나 curl 명령 등을 이용해 기능을 활용할 수 있다.
•
DSL (Domain Specific Language)
elasticsearch는 DSL 쿼리를 사용하는데 JOIN 쿼리가 어렵기 때문에 반정규화를 기본으로 모델링해야 한다.
•
단점
◦
저장공간이 크게 압축되지 않고 시스템 리소스를 많이 사용한다.
◦
인덱스가 불변의 자료구조이기 때문에 도큐먼트를 수정하거나 삭제할 경우 비용이 저렴하지 않다.
→ 하지만 단점들이 검색 성능을 끌어올리기 위해 trade-off된 부분들이기에 용인되는 제약들.
1.2 Logstash - 데이터 처리 파이프라인

logstash는 이벤트 수집과 정제를 위한 도구이다.
•
데이터 수집 및 가공
logstash를 사용해 로그, 메트릭, 웹 어플리케이션 등 다양한 소스로부터 로그를 수집할 수 있다.
또한, 필터 기능을 사용해 비정형이나 반정형 데이터를 분석하기 쉬운 형태로 정제할 수 있고, 엘라스틱서치 외에 다양한 플랫폼으로 정제된 데이터를 내보낼 수 있다.
•
logstash 동작
logstash는 형식에 무관하게 데이터를 동적으로 수집, 변환, 전송하는 구조로 되어있다. 비구조적인 데이터에서도 구조를 도출하고, IP주소에서 위치 정보 좌표를 해독하고, 민감한 필드를 익명화하거나 제외시키는 등의 전반적인 작업을 쉽게 해준다.
•
로그 가공
logstash는 코딩 없이 간단한 설정 만으로도 로그를 가공할 수 있다. 설정의 대부분을 플러그인으로 사용할 수 있는데 200개 이상의 플러그인이 존재한다.
•
elasticsearch 인덱싱 성능 최적화
logstash를 사용해 elasticsearch의 인덱싱 성능을 최적화하기 위한 배치 처리와 병렬 처리가 가능하고, 영속적인 큐를 사용해 현재 처리 중인 데이터 양이 급증하는 부하 상황에서도 안정성을 보장해준다.
1.3 Kibana - 시각화

kibana는 시각화와 엘라스틱서치 관리 도구이다.
•
elasticsearch의 UI
elasticsearch는 모든 입력을 REST API형태로 받아들이기 때문에 복잡한 요청을 일일히 작성하기에 불편함이 있을 수 있다. 이런 불편을 해소해주는 것이 kibana이다.
kibana에는 elasticsearch에 대한 대부분의 관리 기능, API를 실행할 수 있는 콘솔, 솔루션 페이지, 스택의 각 구성 요소들을 위한 모니터링 페이지 등이 포함되어있다.
•
시각화, 대시보드
kibana는 시각화와 대시보드 기능을 제공해준다. 라인 차트, 파이 차트 등과 테이블, 지도 등의 다양한 시각화 요소들을 클릭 몇 번으로 쉽게 구성할 수 있다. 특히 대시보드 기능으로 시각화 요소들을 한 화면에 배치하고 실시간 업데이트할 수 있다.
•
실시간 모니터링, 데이터 분석, APM, SIEM 등의 솔루션
프레젠테이션 만들듯이 시각화를 구성할 수 있는 캔버스, 실시간으로 인덱싱되는 로그를 지속적으로 확인할 수 있는 로그, 애플리케이션의 성능 모니터링을 위한 APM, 보안 이벤트를 관제할 수 있는 SIEM 등 강력한 솔루션이 포함되어 있다.
1.4 Beats - 경량 데이터 수집기

beats는 엣지단에서 동작하는 경량 수집기이다.
•
용도별로 최적화된 경량 에이전트
logstash로 이벤트 정보를 수집하기 위해선 실제 서비스 호스트에 수집기를 설치해야하는데 logstash는 다양한 필터와 설정을 제공해 무겁기 때문에 활용도가 떨어질 수 있다.
따라서 filebeat, metricbeat 등으로 부르는 경량 수집기인 beats가 포함되어 있다. 복잡한 이벤트 가공은 지원하지 않고 가벼워서 서비스 호스트에 부담 없이 설치할 수 있다.
•
beats의 종류와 구조
Filebeat. 경량 로그 및 기타 데이터 수집기
Metricbeat. 경량 메트릭 데이터 수집기
Packetbeat. 경량 네트워크 데이터 수집기
Winlogbeat. 경량 Windows 이벤트 로그 수집기
Auditbeat. 경량 감사(Audit) 데이터 수집기
Heartbeat. 가동 시간 모니터링을 위한 경량 데이터 수집기
Functionbeat. 서버를 사용하지 않는 수집기
보통 beats에서 서비스 호스트 정보를 수집하고 logstash에서 취합, 가공해 elasticsearch로 전송하는 아키텍처가 많이 사용된다.
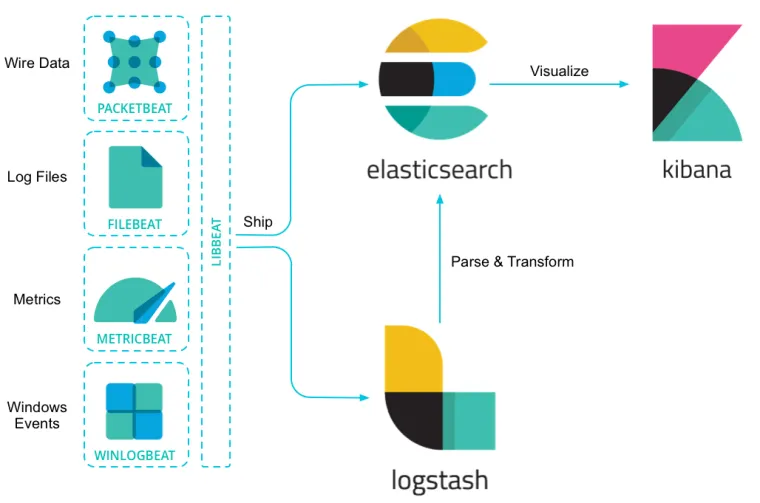
특히, 파일비츠의 내장된 모듈에 서비스 정제를 위한 파이프라인 설정, 샘플 대시보드 등의 기능이 포함되어 별도의 설정 없이 빠르게 로그 수집이 가능하다.
2. ELK의 활용 용도
2.1 전문(full text) 검색 엔진
elasticsearch의 기본적인 용도는 전문 검색 엔진의 구현이다. 일반 RDB에 비해 elasticsearch의 검색 성능이 좋은 이유는 전문 검색을 빠르고 정확하게 하기 위해 용어 term 단위로 분석해 인덱싱을 해두고 이를 기반으로 검색을 수행하는 역인덱싱 inverted indexing 기법이 활용되었기 때문이다. elastic stack에는 용어 분석을 위한 다양한 언어별 분석기가 있고, 유사도 스코어링을 위해 다양한 방법을 제공한다.
2.2 로그 통합 분석
elastic stack은 여러 장비와 서비스에서 발생하는 로그들을 통합하고 검색하는 데 최적화된 솔루션이다. 로그를 별도의 복잡한 구성없이 바로 수집할 수 있다.
beats를 이용해 적은 리소스로 로그들을 수집하고, logstash로 다양한 필터를 통해 일원화된 형태로 가공하고, elasticsearch로 대용량 로그를 빠른 인덱싱과 텍스트 검색을 통해 로그들을 통합해 연관 분석을 지원할 수 있다. 또 kibana로 로그 UI나 대시보드를 사용해 모니터링을 할 수 있다.

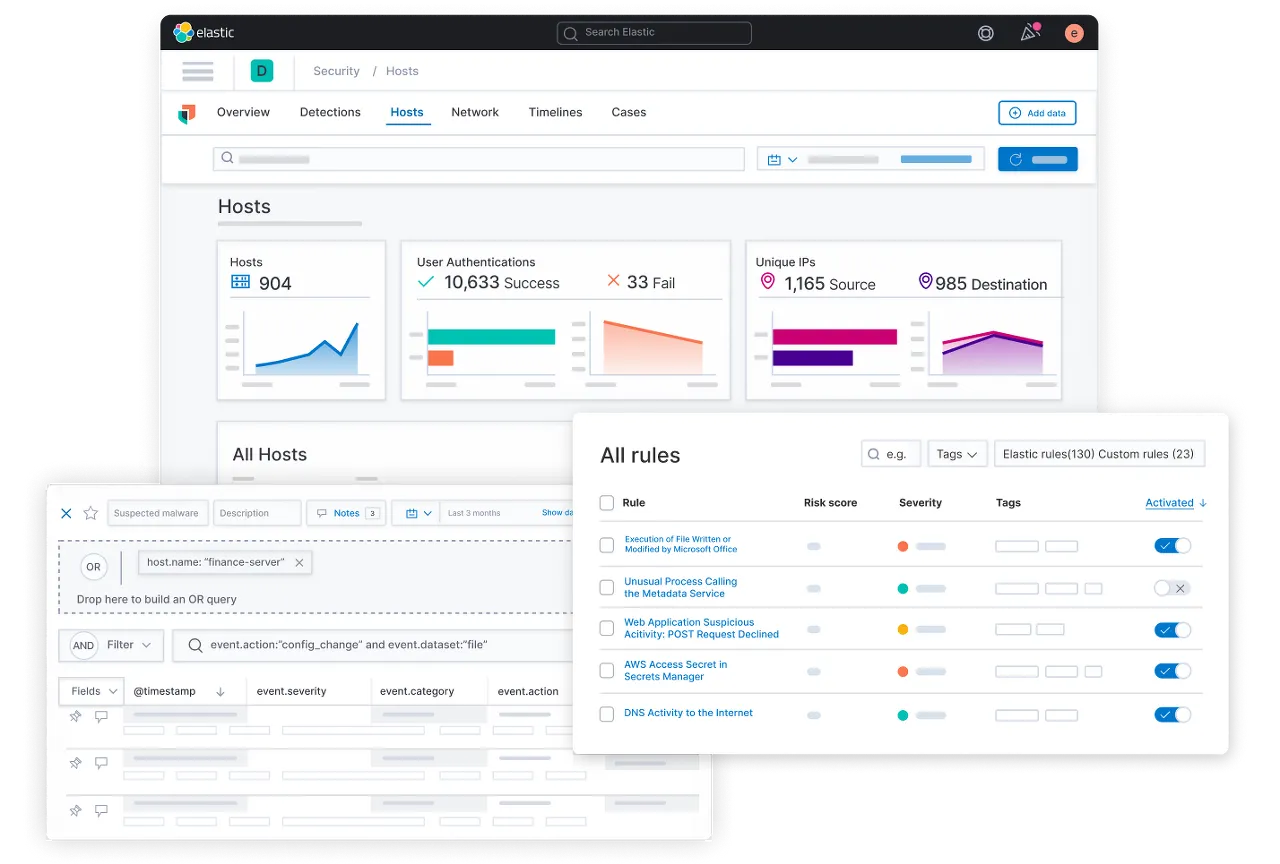
2.3 보안 이벤트 분석
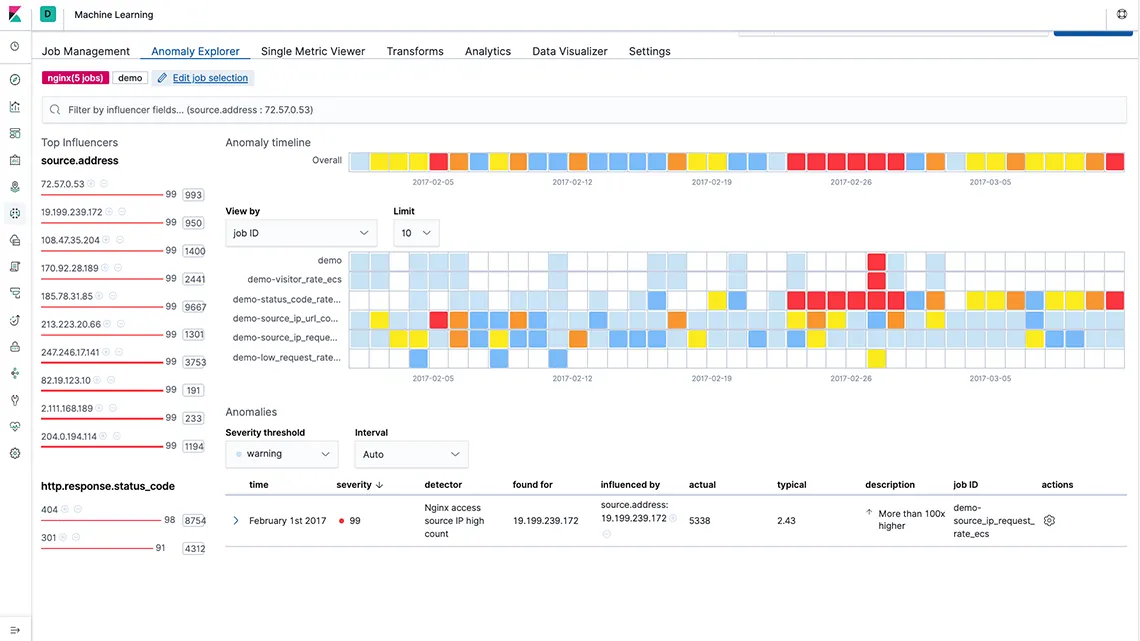
elastic SIEM(Security Information and Ebent Mangament)은 beats의 모듈을 이용해 애플리케이션, Endpoint, Infra Structure, 클라우드, 네트워크 등 다양한 소스에서 수집한 이벤드를 기반으로 엔드포인트 활동, 인증 로그, DNS 트래픽, 네트워크 플로우에서 이상 징후, 불법 로그인 시도, 사용자 접근 패턴 등의 문제를 빠르게 찾아낸다. 또한, SIEM UI에서 분석을 비롯한 고유한 탐지 규칙 또한 가능하다.
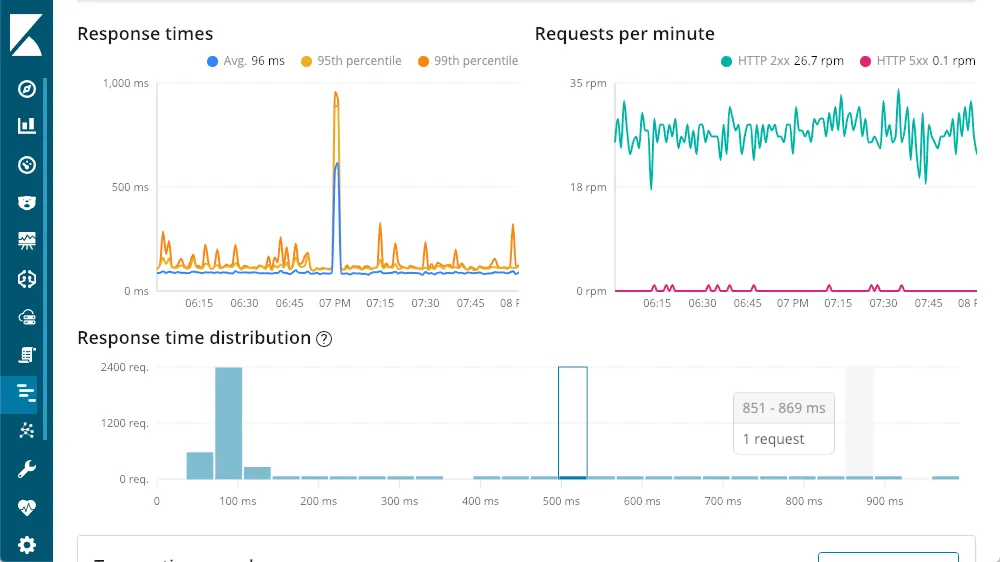
2.4 애플리케이션 성능 분석
elastic stack의 성능 모니터링 도구 APM, Application Performance Monitoring 은 프로그래밍 언어별 에이전트를 통해 성능 지표 수집을 돕고 분석을 위한 UI를 제공한다.
또한, metricbeat와 packetbeat를 사용해 시스템을 비롯해 연계된 다양한 서비스들의 성능 정보를 수집할 수 있게 도와준다. 이 기능은 다른 UI나 머신러닝 등의 기능과 연계하면 효과가 배가 된다.
2.5 머신러닝
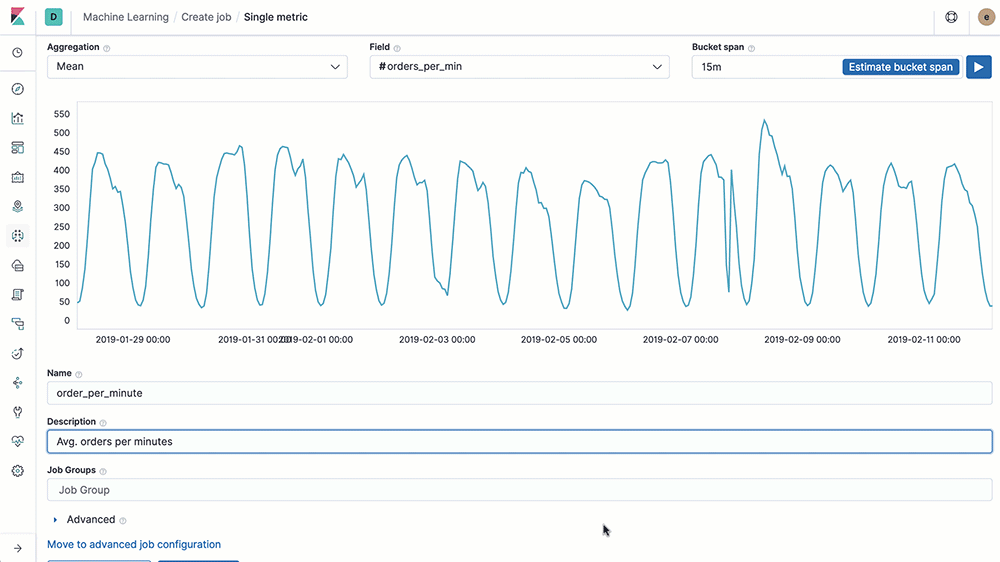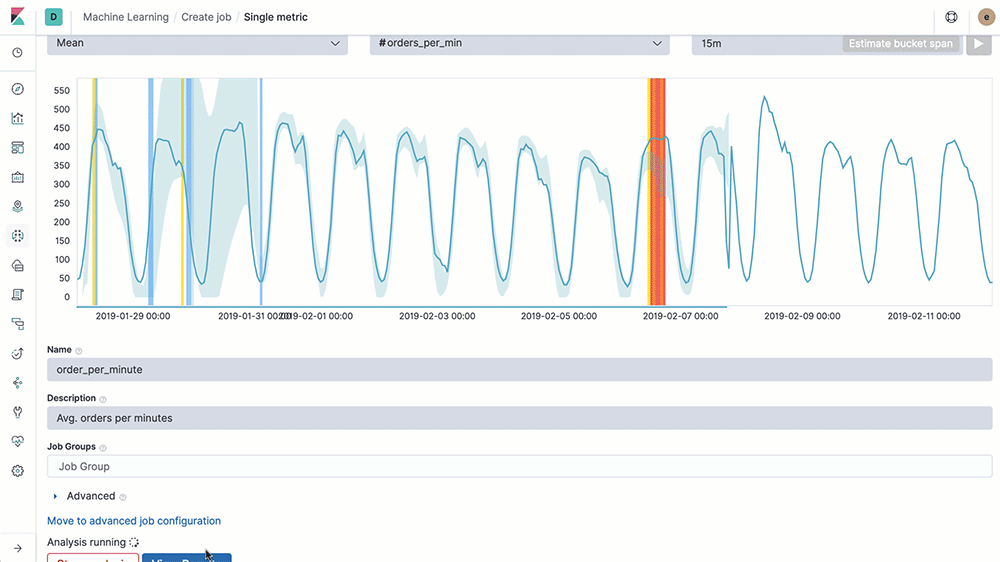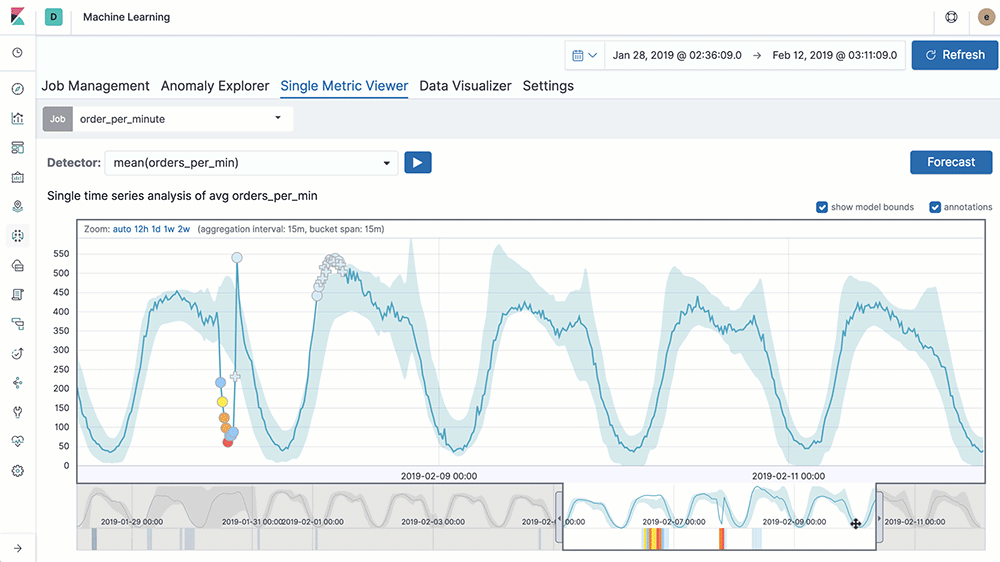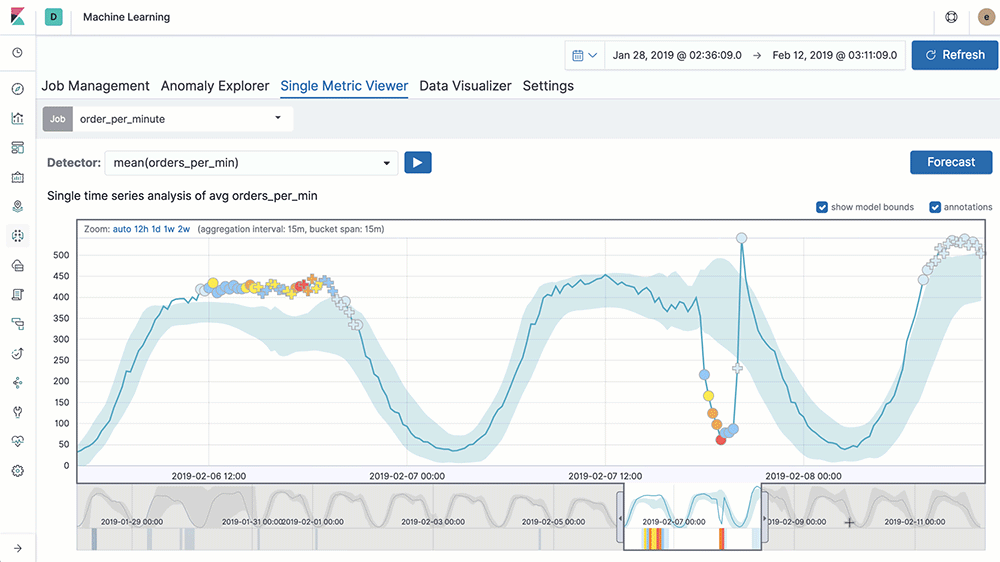
엘라스틱 유료 라이선스를 구매할 경우 머신러닝 기능을 제공한다. 데이터를 엘라스틱 서치에 저장한 후 비지도 학습을 통해 데이터에서 패턴을 발견할 수 있고, 시계열 모델을 통해 이상 징후를 탐지하고 과거 데이터를 기반으로 동향을 예측하게 도와준다.
3. 실제 사용 사례
•
Uber의 대규모 실시간 데이터 통찰 플랫폼 ‘Gairos’
◦
Apache Kafka Topic > Gairos Collect Pipeline > Elasticsearch Gairos Query service Apache Hive/Presto log-term Data
Gairos Query service Apache Hive/Presto log-term Data•
Kafka와 연동
◦
beats에서 수집한 각 장비의 이벤트를 kafka로 전송 → 이를 Logstash로 다시 읽기 or Kafka에 저장된 다른 시스템의 이벤트를 elasticsearch로 읽기 등
•
하둡 생태계와 연동
◦
es-hadoop 모듈을 이용해 Spark에서 elasticsearch API를 이용하여 도큐먼트 읽거나 인덱싱 등 상호작용 수행이 가능하다.
•
RDBMS와 연동
◦
기존의 RDB에 저장된 데이터를 인덱싱하거나 입력받은 이벤트에 정보를 주입하는 등 여러 용도로 사용된다.
유사 제품군
•
Elastissearch - Apache Solr
•
Logstash/Beats - Fluentd
•
Kibana - Grafana, Tableau
•
Elastic Stack - Splunk