
1. Introduction
스트림처리(stream) : 끝없이 들어오는 데이터 흐름을 연속적으로 처리하는 것.
1-1. 스파크 스트리밍
•
스파크 코어 엔지의 분산처리 기능 위에 구축된 최초의 스트림 처리 프레임워크
•
스파크 스트리밍을 통해 실시간 데이터 소스(Kafka, HDFS 등)로부터 스트리밍 데이터를 받아 처리할 수 있음.
•
연속적인 데이터 스트림을 스파크가 작동할 수 있는 개별 데이터 컬렉션으로 변환
1-2. 배치 처리 vs 스트림 처리
1.
배치 처리 : 특정 시간 범위 내에서 대량의 데이터를 일괄 처리하는 것
•
데이터 크기가 알려져 있는 유한 데이터를 처리할 때 사용
•
시간이 지남에 따라 데이터가 수집되고 유사한 데이터가 일괄 처리/그룹화되면 처리
2.
스트림 처리 : 무한데이터(unbounded data)로부터 정보를 추출하는데 사용하는 규율 및 관련 기술의 집합
•
데이터의 크기를 알 수 없으며, 그 범위가 무한하고 연속적일 때 사용
ex) 모바일 디바이스에서 로그, sns 타임 피드, 증권 거래 주문 같이 실시간으로 계속 들어와서 쌓이는 데이터
스트림 처리 | 배치 처리 | |
데이터 범위 | 롤링 타임 윈도우 내 데이터 또는 가장 최신 데이터 레코드의 데이터를 처리 | 데이터 세트의 모든 또는 대부분의 데이터를 처리 |
데이터 크기 | 일부 레코드로 구성된 마이크로 배치 또는 개별 레코드 | 대규모 데이터 배치 |
성능 | 몇 초 또는 몇 밀리 초 지연 시간 소요 | 지연 시간 몇 분에서 몇 시간 |
분석 | 간단한 응답 가능, 수집 및 롤링 지표 | 복잡한 분석 |
장점 | - 이상징후와 문제를 신속하게 감지
- 데이터를 실시간으로 처리하여 빠른 의사 결정을 가능하게 함 | - 직관적, 유지보수와 개발이 비교적 단순
- 대용량 데이터를 효율적으로 처리 |

(사용 예시) Feature Store

[batch 처리]
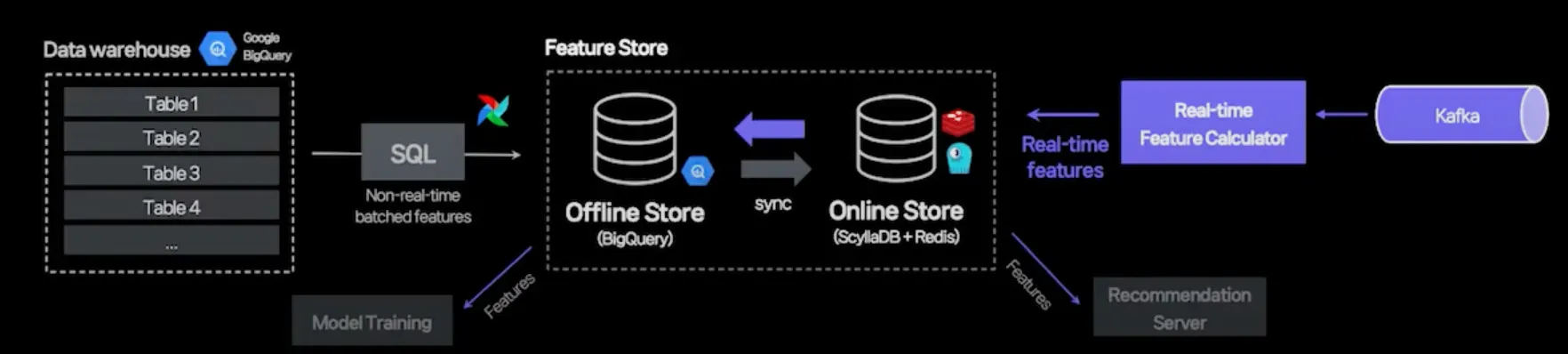
[Stream 처리]
•
예시 프로젝트 :
2. Spark Streaming API
•
스파크 스트리밍은 실시간 데이터 분석을 위한 스파크 컴포넌트로, 데이터는 카프카, 키네시스, TCP 소켓 등 다양한 경로를 통해서 입력받고, map, reduce, window 등의 연산을 통해 데이터를 분석한 결과를 최종 파일 시스템, 데이터베이스에 적재하는 시스템

•
스파크는 두 가지 스트리밍 API를 제공
1.
DStream API(Spark Streaming)
2.
정형화(구조적) 스트리밍 API(Spark Structured Streaming)
2-1. 스파크 스트리밍(Dstream)
스파크는 배치 처리를 지향하는 프레임워크로, 스트리밍 데이터를 처리하기 위해 배치 처리 기능을 스트리밍 데이터에 적용하는 마이크로 배치 아키텍쳐를 사용
2-1-1. 스파크 스트리밍 연속형 처리 vs 마이크로 배치 처리
1.
레코드 단위 처리 모델(record-at-a-time processing model) - 다른 프레임워크
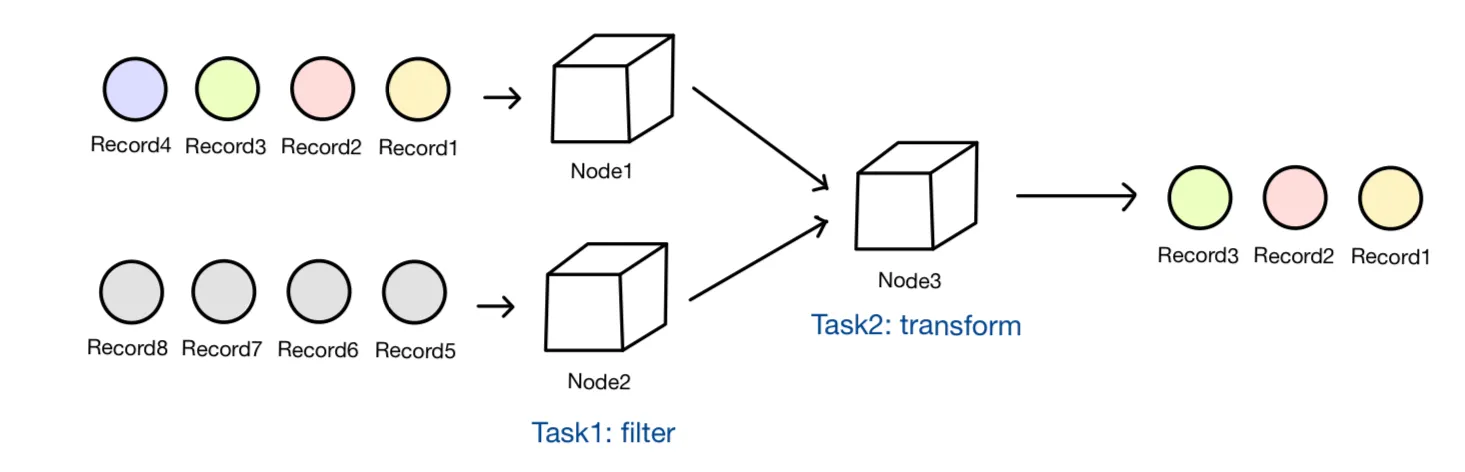
: 시스템을 구성하는 각 노드는 다른 노드에서 전송하는 메시지를 끊임없이 수신하고 새로 갱신된 정보를 자신의 하위 노드로 전송하여 처리 → 각 노드별로 하는 태스크가 다름. 다루는 데이터 동일.
•
각 노드가 신규 메시지에 즉시 반응하며, 전체 입력량이 비교적 적을 때 가장 빠르게 응답.
•
레코드 단위 부하가 매우 크기 때문에, 최대 처리량이 적음.
•
고정형 연산 토폴로지(컴퓨터 네트워크 요소를 물리적으로 연결하는 방식)를 사용하므로, 전체 시스템을 중지해야 애플리케이션을 변경할 수 있다.
2.
마이크로 배치 처리(micro-batch stream processing) - 스파크

: 입력 데이터를 작은 배치로 모으고 다수의 분산 태스크를 이용해 각 배치를 병렬로 처리 → 각 노드별로 동일한 태스크를 진행. 다루는 데이터 다름.
•
특정 시간 간격 내에 유입된 데이터 블록을 끊어 RDD로 구성하고 아주 짧은 주기로 배치처리를 진행
RDD(Resilient Distributed Dataset) 스파크의 기본 데이터셋 추상화 객체로 메모리 내부에서 데이터가 손실 되었을 때 유실된 파티션을 재연산해 복구할 수 있는 형태로 구성되어 있음. 또한, 스파크 클러스터를 통해 메모리에 데이터를 분산 저장
•
입력 데이터를 작은 배치로 모으기 위해 대기시간을 가진 뒤, 각 시간대 별 배치를 일반적인 배치처리 형태로 병렬 처리하여 결과를 출력
•
노드당 처리량이 레코드 단위 처리보다 높음
3.
레코드 단위 처리 모델과 마이크로 배치 처리 모델 비교
레코드 단위 처리 | 마이크로 배치 처리 | |
처리 방식 | 데이터 스트림의 각 레코드를 독립적으로 처리. 레코드가 도착할 때마다 실시간으로 처리. | 스트리밍으로 들어오는 레코드를 작은 마이크로 배치로 나누어 처리. 고정된 시간 간격마다 배치를 생성하고 처리. |
지연 시간 | 일반적으로 마이크로 배치 처리보다 더 낮은 지연 시간을 가짐. | 각 배치의 처리는 빠르지만, 배치를 생성하는 간격이 존재하기 때문에 지연이 발생할 수 있음. |
처리 방식의 결과 | 하나의 레코드를 출력함. | 배치 단위로 레코드를 출력함. |
복잡성 | 배치 간의 상태 관리 등의 일부 복잡한 처리가 필요. 각 노드간의 종속성이 존재. | 하나의 노드에서 모든 태스크가 실행되기 때문에, 레코드 단위 처리 모델보다 복잡성이 덜 함. |
운영 방식 | 낮은 지연 시간과 정확한 처리가 필요한 실시간 응용 프로그램에 적합. | 높은 처리량(자원 사용량이 높음.)과 스케줄링의 간단함이 필요한 응용프로그램에 적합. |
장애 및 복구 | 하나의 노드에서 장애가 발생하면 전체 프로세스가 멈춤. 즉, 해당 노드를 빨리 회복시켜야 장애 복구가 됨. | 하나의 노드에서 장애가 발생하면, 이를 대신할 노드가 존재함. 즉, 레코드 단위 처리보다 장애에 덜 민감함. |
마이크로 배치 처리가 유용한 이유
•
웬만한 파이프라인은 굳이 초 단위 이하의 반응 속도를 필요로 하지 않음. 예를 들어, 실시간 검색 순위, 실시간 최대 클릭 페이지 등의 정보를 띄울 때, 1초 정도의 지연은 크게 문제가 되지 않는다.
•
파이프라인의 다른 부분들에 더 큰 지연이 있는 경우가 많다. 예를 들어, 데이터 수집 단계에서 지연이 있는 경우 스파크 스트리밍보다 더 빠른 속도를 지원하는 처리 단계가 필요하지 않다.
2-1-2. 스파크 스트리밍(Dstream)
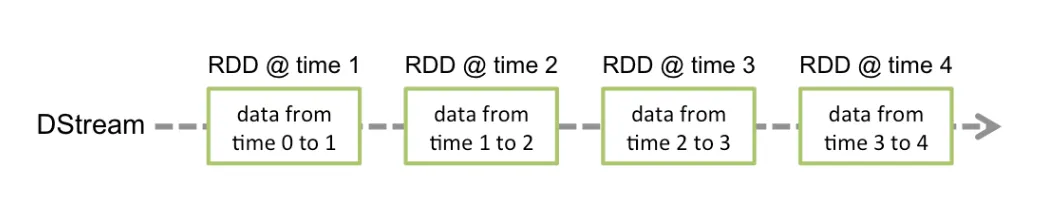
•
Dstream : 시간별로 도착한 데이터들의 연속적인 모임
•
각 Dstream은 시간별 RDD들의 집합으로 구성됨.
•
새로운 Dstream을 만들어 내는 Transformation 연산과 외부 시스템에 데이터를 써주는 출력 연산을 지원한다.
2-1-3. Dstream의 한계
배치나 스트림 처리를 위한 단일 API 부재
•
배치와 스트리밍에 대해 나름 일관성이 있는 API를 제공하긴 했지만 정확히 일치하진 않음.
•
따라서, 배치 잡을 스트리밍 잡으로 전환할 때, 명시적으로 코드를 재작성하는 단계가 필요함.
논리/물리 계획 간에 구분 부족
•
Dstream은 RDD를 기반으로 만들어졌기 때문에, 개발자가 작성한 코드 그대로 연산을 수행함.
•
즉, 자동화된 최적화 단계가 없기 때문에 최고의 성능을 얻기 위해서는 수동적인 최적화 과정이 필요함.
이벤트 타임 윈도우를 위한 기본 지원 부족
•
Dstream은 윈도우 연산을 각 레코드를 스파크 스트리밍에서 받은 시각(= 처리 시간, processing time)을 기준으로 수행.
•
하지만, 실제 사례에서는 처리 시간보다는 레코드가 생성된 시각(= 이벤트 타임, event time)으로 윈도우 연산을 수행하기를 바라는데, 스파크 스트리밍은 이를 지원하지 않음.
2-2. 구조적 스트리밍(Structured Streaming)
•
구조적 스트리밍 : 스파크 SQL 엔진을 기반으로 개발된 확장성있고 장애를 허용(fault-tolerant)하는 스트림 처리 엔진. 정적 데이터에 대한 배치(batch) 연산을 정의하는 것과 같은 방법으로 스트리밍 연산을 정의할 수 있음.
•
Scala, Java, Python이나 R에서 Dataset/DataFrame API를 사용하여 스트리밍 집계, 이벤트-시간 윈도우, 스트림-배치 조인 등을 표현할 수 있으며, 이렇게 주어진 연산은 배치 방식 연산과 마찬가지로 최적화된 스파크 SQL 엔진에서 실행됨.
•
시스템은 체크포인트와 로그 선행 기입(write-ahead log)를 통해 장애 발생 시에도 종단간 정확히 한 번(exactly-once) 데이터 처리를 보장함.
2-2-1. 구조적 스트리밍의 프로그래밍 모델


•
스파크 스트리밍에서는 순차적으로 들어오는 데이터를 무한히 데이터가 추가되는 테이블로 취급한다.
•
이를 통해 배치 프로세싱과 유사한 방식으로 데이터를 다룰 수 있게 됨.
•
스파크는 새롭게 들어오는 데이터를 무한한 크기의 입력 테이블(unbounded table)에 점진적으로 추가하는 증분(incremental) 쿼리를 실행함.
2-2-2. 구조적 스트리밍 쿼리의 기초
입력 소스
•
파일 소스
◦
디렉토리에 있는 파일을 데이터 스트림으로 읽어옴.
◦
텍스트, csv, json, orc, parquet 파일 형식 지원.
•
Kafka 소스
◦
Kafka 브로커 버전 0.10.0 이상에서 호환
•
소켓 소스(테스트용)
◦
연결된 소켓으로부터 UTF-8 텍스트 데이터를 읽어옴.
◦
종단간 장애 허용 보장하지 않음.
•
속도 소스(테스트용)
◦
초당 생성될 행의 수를 지정하면 그것에 맞게 데이터를 생성함.
스트리밍 DataFrame/Dataset의 스키마 추론과 파티션
•
기본적으로, 파일 기반 소스에서 동작하는 구조화된 스트리밍 처리는 스키마를 지정해주어야 한다.
◦
스파크의 자동 추론 기능을 켜려면 spark.sql.streaming.schemaInference 를 true로 설정하면 된다.
◦
하지만, 이는 장애가 발생했을 경우 스트리밍 쿼리에 일관된 스키마가 사용되는 것을 보장하지 않기 때문에 권장하지 않는다.
•
파티션 탐색은 /key=value/ 라는 이름의 하위 디렉토리가 있고, 디렉토리 탐색 과정에서 해당 디렉토리를 처리할 때 수행됨.
◦
사용자가 제공한 스키마에 이러한 이름의 컬럼이 포함되어 있다면, 스파크가 자동으로 읽어 들이는 파일의 경로를 이용해 컬럼의 값을 채운다.
◦
하지만 파티션 되는 컬럼은 정적이어야 한다. 즉, /data/year=2015/가 존재할 때 /data/year=2016/를 추가하는 것은 괜찮지만, 컬럼을 바꾸어 /data/data=2016-04-17/이라는 디렉토리를 생성하는 것은 안 된다.
스트리밍 DataFrame/Dataset의 연산
•
DataFrame/Dataset에서 자주 사용되는 대부분의 연산은 스트리밍에서도 지원함.
•
Streaming 데이터의 특성상 일부 지원하지 연산이 존재함. (ex. sort, distinct 등)
◦
경우에 따라, 출력 결과에 대해 .foreach() 메소드를 이용하여 적용 가능.
◦
이 외도 적용하고자 하는 문제에 따라 해결법이 존재하는 경우도 있고, 없는 경우도 있음. → Google참고
•
배치 데이터 처럼 임시 뷰를 생성하여 SQL 쿼리를 적용할 수도 있다.
# sql 예시 코드
df = ... # df를 streaming DF로 받아옴.
df.createOrReplaceTempView("임시뷰테이블이름")
spark.sql("select count(*) from 임시뷰테이블이름") # 다른 스트리밍 DataFrame을 반환
Python
복사
출력 모드
•
Append(default)
◦
마지막 트리거 이후 결과 테이블에 새로 추가된 로우만 싱크로 출력됨.
◦
이는 결과 테이블에 이미 추가된 로우를 절대 변경하지 않는 쿼리에만 지원됨.
◦
select, where, map, flatMap, filter, join 등
•
Complete
◦
매 트리거 후에 전체 결과 테이블이 싱크로 출력됨.
◦
이 모드에서는 집계 쿼리를 지원함.
•
Update
◦
마지막 트리거 이후 결과 테이블에서 업데이트된 로우만 싱크로 출력.
출력 싱크
•
파일 싱크 : 출력을 디렉토리에 저장
writeStream
.format("parquet") # "orc", "json", "csv" 등이 될 수 있음
.option("path", "path/to/destination/dir")
.start()
Python
복사
•
Kafka 싱크 : 출력을 Kafka의 하나 이상의 토픽에 저장
writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("topic", "updates")
.start()
Python
복사
•
Foreach 싱크 : 출력의 레코드에 대해 임의의 연산을 실행.
writeStream
.foreach(...)
.start()
Python
복사
•
콘솔 싱크(디버깅용) : 트리거가 호출될 때마다 콘솔/표준 출력에 출력.
◦
매 트리거 이후에 드라이버의 메모리에 출력 전체가 수집, 저장되기 때문에 적은 양의 데이터에 대해 디버깅 목적으로 사용되어야 함.
writeStream
.format("console")
.start()
Python
복사
•
메모리 싱크(디버깅용) : 출력이 메모리에 in-memory 테이블 형태로 저장됨.
writeStream
.format("memory")
.queryName("tableName")
.start()
Python
복사
3. 이벤트 시간 처리
3-1. 이벤트 시간 vs 처리 시간
•
이벤트 시간(Event time): 데이터가 발생한 시점
◦
데이터에 기록된 시간 필드
◦
데이터마다 이벤트 시간을 비교할 때, 지연되거나 무작위로 도착한 이벤트가 있으므로 스트리밍 처리 시 이를 제어할 수 있어야 함
예) 웹 사이트에서 사용자 활동을 추적하는 시스템
•
처리 시간(Processing time): 시스템에서 이벤트 또는 레코드를 처리하는 시간
◦
시스템이 데이터를 수신하고 처리를 시작하는 시간 기준
◦
이벤트 시간처럼 외부 시스템에서 제공하는 것이 아니라, 스트리밍 시스템이 제공하는 속성이므로 순서가 뒤섞이지 않음
예) 일괄 처리 시스템에서 레코드의 처리 시간은 디스크에서 읽고 시스템에서 처리한 시간
이벤트 시간 처리가 필요한 이유
컴퓨터 네트워크의 불안정으로 이벤트 전송은 성공하거나 실패할 수 있다. 따라서, 처리 시스템의 이벤트 순서는 이벤트 시간 순으로 정렬되어 있음을 보장할 수 없으며, 이러한 데이터로 분석시 잘못된 결과를 얻을 수 있게 된다.
3-2. 윈도우 연산
•
윈도우
◦
스트림 처리를 위해 데이터를 더 작고 유한한 집합으로 그룹화하는 방법.
◦
윈도우는 정의된 시간 또는 이벤트 범위에 속하는 데이터의 특정 부분만 포함하는 집합. 즉, 전체 데이터 스트림의 하위 집합으로 생각할 수 있다.
•
윈도우 종류
◦
텀블링 윈도우: 크기가 고정되고 겹치지 않는 윈도우. 데이터를 고정 기간의 겹치지 않는 동일한 크기의 창으로 분할합니다. 시작 및 종료 시간이 잘 정의되어 있고, 각 데이터 레코드가 다른 레코드와 독립적인 데이터를 분석하는 데 유용함
예) 5분의 텀블링 기간을 사용하는 경우, 데이터 스트림은 겹치지 않는 5분 기간으로 나누어짐

•
슬라이딩 윈도우: 고정된 크기의 겹치는 윈도우. 데이터를 동일한 크기의 고정 기간 동안 겹치는 창으로 분할합니다. 슬라이딩 윈도우는 연속 흐름이 있고, 각 데이터 레코드가 이전 및 미래 레코드에 의존하는 데이터를 분석하는 데 유용함
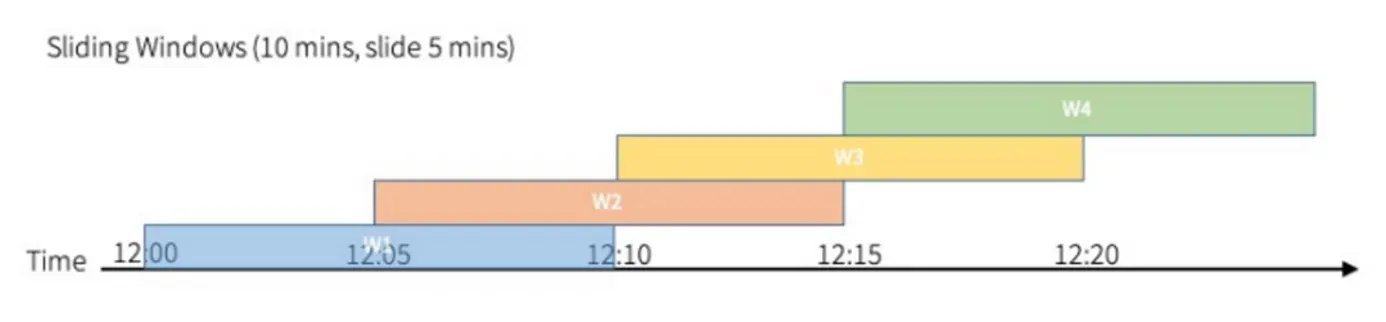
예) 10분의 슬라이딩 윈도우와 5분의 슬라이드 간격을 사용하는 경우, 데이터 스트림은 5분이 겹치는 10분 기간으로 분할.
•
세션 윈도우: 특정 시간 간격 내에 발생하는 이벤트를 기반으로 데이터를 그룹화하는 동적 윈도우. 특정 비활성 기간 내에 발생하는 모든 데이터 레코드를 함께 그룹화하며 기간은 사용자가 지정합니다.
예) 시간 제한이 10초인 세션 윈도우를 사용하는 경우, 마지막 데이터 레코드로부터 10초 이내에 도착하는 모든 데이터 레코드는 동일한 창에 함께 그룹화됩니다. 세션 윈도우는 활성 기간 사이에 비활성 기간이 있는 데이터를 분석하는 데 유용합니다.

3-3. 워터 마킹
•
워터 마킹
◦
이벤트 시간 처리에서의 시간 제한 설정.
◦
지연 데이터를 위해 이전의 데이터를 계속 기억을 한다면 메모리 부족 오류 및 성능 저하 문제가 발생함. 따라서, 어느 기간까지 기억할 것인지를 표기하고, 해당 기간이 지난 데이터는 폐기하는 방식.
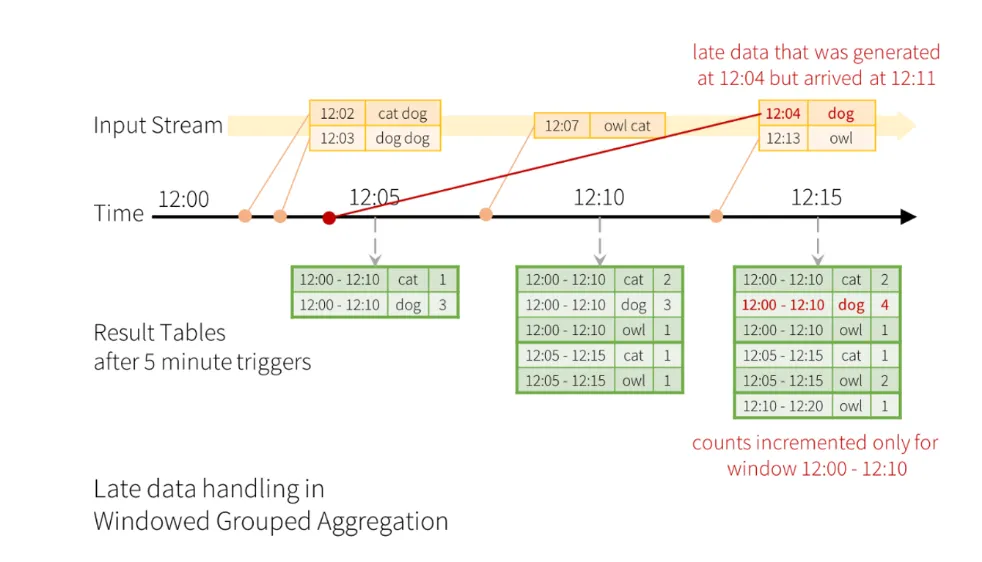
•
만약, 12:11에 12:04에 생성된 데이터가 늦게 수신된다고 하면, 해당 윈도우 시간(12:00~ 12:10)에 집계되도록 해야 함
•
지연 데이터가 이전 윈도우의 집계를 정확히 업데이트 할 수 있게, 오랜 기간동안 이전의 부분 집계에 대한 중간 상태를 유지해야 함
•
해당 쿼리가 며칠 동안 걸쳐 장기간 실행된다면, 시스템에 누적되는 메모리가 과부하가 올 수 있음
•
시스템 메모리의 과부하를 방지하기 위해 워터마크를 지정하여, 지연되는 데이터를 허용하는 시간 임계값을 조정
