

데이터 파이프라인 개요
데이터 파이프라인이란?
•
데이터를 차례대로 전달해나가도록 구성된 시스템.
•
데이터를 정제하고, 변환하고, 분석하고, 저장하고, 전달하는 과정을 포함함.
•
분석, 리포팅, 머신러닝 등 데이터가 필요한 업무 수행을 위해 데이터를 ‘잘’ 가져다 주는 것이 데이터 파이프라인 구축이라 할 수 있다.
간단한 예시
•
RESTful API 소스 (추출) → 데이터 웨어하우스의 RDB 테이블 (로드)
•
사용자 이벤트 발생 → Kafka 등 메시지 브로커로 이벤트 발행 → Vector로 이벤트 구독 → ElasticSearch Index에 적재
•
서버 로그 발생 → Kubernetes filebeat 로그 수집 → Hadoop 적재 → Impala SQL로 분석
데이터 파이프라인 패턴 : ETL vs ELT(EtLT)
ETL
•
Extract (추출)
◦
데이터를 추출/수집하는 과정.
◦
기본적인 데이터 형태(CSV, JSON)를 직접 받아오거나 로그를 추출하기도 함.
•
Transform (변환)
◦
데이터를 분석하기 용이한 형태로 다시 변환하는 과정.
◦
최초에 추출/수집한 데이터는 그냥 저장하거나 분석하기 적합한 형태가 아니기 때문에, 저장과 분석에 용이한 형태로 변환하는 과정이 필요함.
•
Load (로드)
◦
데이터를 저장하는 과정.
◦
데이터 레이크, 혹은 데이터 웨어하우스 등에 저장함.
ELT
•
데이터를 변환하지 않고 일단 저장 후 추후 이용 단계에서 변환을 하는 것.
•
ETL에서 ELT가 등장한 배경
◦
지금 당장은 쓰지 않더라도 데이터를 우선 저장해두는 것의 필요성
→ 데이터 레이크 등을 이용하여 데이터를 있는 그대로 적재.
◦
최신 클라우드 기반 서버 기술을 기반으로 한 데이터 웨어하우스는 거의 무한대의 스토리지 기능과 확장 가능한 처리 능력을 제공함.
→ 데이터 웨어하우스 내에서 대규모 데이터셋에 대한 대량 변환이 가능해짐.
◦
열 기반 데이터베이스의 I/O 효율성, 데이터 압축, 데이터 처리를 위한 여러 병렬 노드에 데이터 및 쿼리를 분산하는 기능.
→ 데이터 웨어하우스 내에서 대규모 데이터셋을 저장, 변환 및 쿼리하는 것이 효율적으로 변함.
EtLT
•
ELT 단계에서 load 전에 아주 작은 변환을 수행하는 패턴.
데이터 수집
•
한 소스에서 데이터를 추출하는 작업.
벌크형 / 스트리밍형
•
벌크형(bulk) : 이미 존재하는 데이터를 정리해 추출하는 방법. 데이터 베이스와 파일 서버 등에서 정기적으로 데이터를 수집할 때 사용함.
•
스트리밍형(streaming) : 차례대로 생성되는 데이터를 끊임없이 연속적으로 보내는 방법. 모바일 앱이나 임베디드 장비 등에서 데이터를 수집하는 데에 사용함.
데이터 소스의 특성
소스 시스템 소유권에 따른 데이터 수집
•
일반적으로 수집하는 데이터는 조직이 소유한 소스 시스템과 타사 도구 및 공급업체에서 데이터를 수집하는 것이 일반적임.
•
이러한 소스 시스템이 위치하는 곳을 파악하여 추후에 발생할 수 있는 문제를 방지하는 자세가 필요함.
타사 데이터소스 | 내부적으로 구축된 시스템 |
- 엑세스 방법에 제한이 있을 수 있음. (SQL 데이터베이스 형태로 제공되지 않고, API로만 접근할 수 있는 경우)
- 타사 시스템에 많은 부하를 가하는 경우 법적인 문제가 발생할 수 있음. | - 시스템에 의도하지 않은 부하를 가하고 있는지.
- 데이터를 점진적으로 로드할 수 있는지의 여부를 확인. |
수집 인터페이스 종류
•
Postgres 또는 MySQL 데이터베이스와 같은 애플리케이션 뒤에 있는 데이터베이스
•
REST API와 같은 시스템 상단의 추상화 계층
•
Apache Kafka와 같은 스트림 처리 플랫폼
•
로그, 쉼표로 구분된 값(csv) 파일 및 기타 플랫 파일을 포함하는 공유 네트워크 파일 시스템(NFS) 또는 클라우드 스토리지 버킷
•
데이터 웨어하우스 또는 데이터 레이크
•
HDFS 또는 HBase 데이터베이스의 데이터
데이터의 형식(구조)의 종류
•
REST API의 JSON
•
MySQL 데이터베이스의 잘 구성된 데이터
•
MySQL 데이터베이스 테이블 열 내의 JSON
•
반정형화된 로그 데이터
•
CSV, 고정 폭 형식(FWF) 및 기타 플랫 파일 형식
•
플랫 파일의 JSON
•
Kafka의 스트림 출력
데이터 사이즈
•
수집하려는 데이터 사이즈에 따라 수집 / 저장 방식이 달라질 수 있음.
•
저장 방식을 고려할 때는 이후 처리 단계를 어떻게 진행할 것인지를 고려하는 것도 도움이 될 수 있음.
데이터 클렌징 작업과 유효성 검사
•
데이터 소스의 특성이 다양하듯 소스 데이테의 품질이 매우 다양할 수 있음. 따라서, 데이터들에 대한 클렌징 작업 및 유효성 검사를 진행하여 데이터의 품질을 보장해주는 것이 중요함.
•
아래는 소위 ‘품질이 낮은, 지저분한 데이터’들의 특징을 정리한 것임.
◦
중복되거나 모호한 레코드
◦
고립된 레코드
◦
불완전하거나 누락된 레코드
◦
텍스트 인코딩 오류
◦
일치하지 않는 형식(eg. 전화번호 데이터에서, 010-xxxx-xxxx, 010xxxxxxxx와 같이 -의 사용이 제각각)
◦
레이블이 잘못되었거나 레이블이 지정되지 않은 데이터
데이터 처리 방식 - 스트림 처리 / 배치 처리
•
배치 처리 : 특정 시간 범위 내에서 대량의 데이터를 일괄 처리하는 것
◦
데이터 크기가 알려져 있는 유한 데이터를 처리할 때 사용
◦
시간이 지남에 따라 데이터가 수집되고 유사한 데이터가 일괄 처리/그룹화되면 처리
•
스트림 처리 : 무한데이터(unbounded data)로부터 정보를 추출하는데 사용하는 규율 및 관련 기술의 집합
◦
데이터의 크기를 알 수 없으며, 그 범위가 무한하고 연속적일 때 사용
ex) 모바일 디바이스에서 로그, sns 타임 피드, 증권 거래 주문 같이 실시간으로 계속 들어와서 쌓이는 데이터
스트림 처리 | 배치 처리 | |
데이터 범위 | 롤링 타임 윈도우 내 데이터 또는 가장 최신 데이터 레코드의 데이터를 처리 | 데이터 세트의 모든 또는 대부분의 데이터를 처리 |
데이터 크기 | 일부 레코드로 구성된 마이크로 배치 또는 개별 레코드 | 대규모 데이터 배치 |
성능 | 몇 초 또는 몇 밀리 초 지연 시간 소요 | 지연 시간 몇 분에서 몇 시간 |
분석 | 간단한 응답 가능, 수집 및 롤링 지표 | 복잡한 분석 |
장점 | - 이상징후와 문제를 신속하게 감지
- 데이터를 실시간으로 처리하여 빠른 의사 결정을 가능하게 함 | - 직관적, 유지보수와 개발이 비교적 단순
- 대용량 데이터를 효율적으로 처리 |
데이터 저장
데이터 웨어하우스
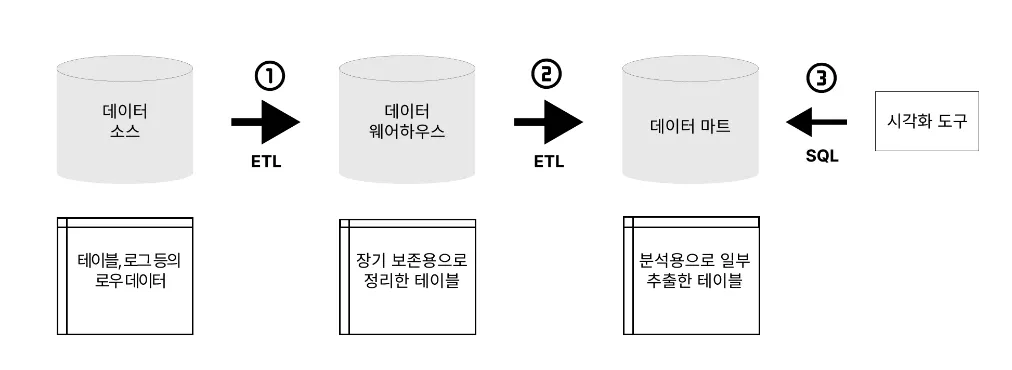
•
기업이나 조직에서 사용하는 모든 데이터를 한 곳에 모아서 관리하고 분석하는 시스템.
•
데이터를 중앙 집중적으로 저장하여 효율적으로 분석할 수 있도록 해줌.
•
대량의 데이터를 장기 보존하는 것에 최적화. 정리된 데이터를 한 번에 전송하는 것에는 적절하지만, 소량의 데이터를 자주 쓰고 읽는 데는 적합하지 않음.
→ 데이터 마트의 필요성
•
업무에 있어서 중요한 데이터 처리에 사용되기 때문에 아무때나 함부로 사용해 시스템에 과부하가 걸리면 곤란함.
→ 데이터 마트의 필요성
데이터 레이크
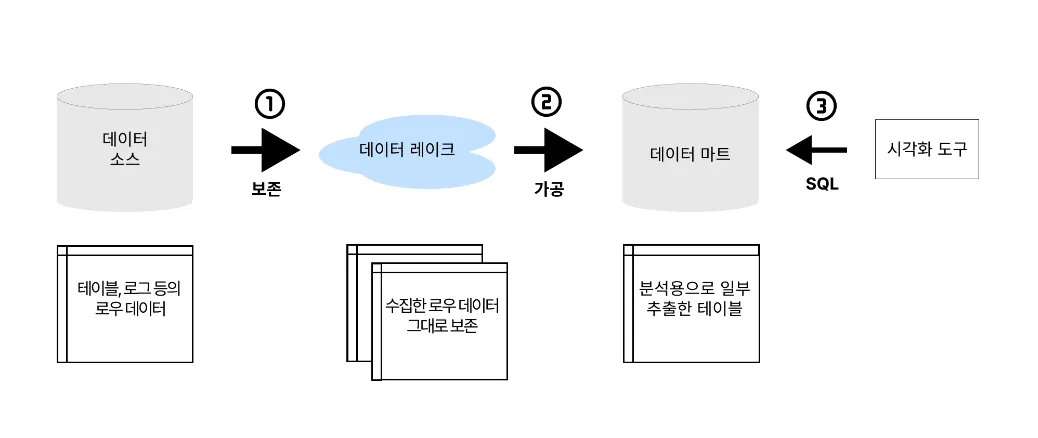
•
데이터를 있는 그대로 데이터 웨어하우스에 넣을 수 없는 경우가 존재.
•
모든 데이터를 원래의 형태로 축적해 나중에 필요에 따라 가공하는 구조.
•
물밀듯이 들어오는 데이터를 저장하는 공간을 ‘데이터를 축적하는 호수’에 빗대어 표현한 데이터 축적 장소. 미가공의 데이터를 있는 그대로 저장.
데이터 마트
•
특정 주제나 비즈니스 프로세스에 관한 정보를 중심으로 구성.
•
데이터 웨어하우스보다 작고 더 특화된 데이터 저장소.
ex) 마케팅 부서 : 사용하는 고객 정보나 판매 분석 데이터, 재고 관리 등과 관련된 데이터를 모아서 구성.
데이터 통합 방식
Full Table Replecation(전체 복제)
•
테이블을 소스 데이터베이스에서 데이터 웨어하우스로 완전히 로드하는 경우
•
SCD(Slowly Changing Dimension)
◦
데이터가 전체 새로고침 된 경우, 기존 데이터에 대한 변경 사항을 덮어쓰기 때문에 과거 변경 사항을 추적하기 위한 방법이 필요함.
◦
SCD는 레코드가 유효한 날짜 범위를 포함하여 엔티티가 변경될 때마다 테이블에 새 레코드를 추가하는 방법임.
SCD 예시 (멘멘 A조 가람이 정리본)
Append-Only Incremental Replication(부분 추가 복제)
•
소스 데이터베이스에서 추가된 데이터만을 로드하는 방식
Updated At Incremental Replication(부분 갱신 복제)
•
소스 데이터베이스에서 추가 및 수정된 데이터만을 로드하는 방식
워크플로 관리
•
워크플로 관리 기술 : 매일 정해진 시간에 배치 처리를 스케줄대로 실행하고, 오류가 발생한 경우 관리자에게 통지하는 목적으로 사용.
BOAZ 21기 엔지니어링 방학 세션 - Airflow 자료 참고
실습 : 기업들의 실제 데이터 파이프라인 분석

데이터 파이프라인 분석 큰 틀
1.
데이터 원천이 무엇인지 : 어떤 특징을 가진 데이터에 대한 파이프라인인지?
2.
목적이 무엇인지 : 최종 사용자가 누구미여, 어떤 용도로 이용할 데이터에 대한 파이프라인인지?
3.
ETL? ELT? 데이터 웨어하우스? 데이터 레이크?
4.
개선점? 의문점?
콴다(Qanda) : 데이터 마트 생성을 위한 데이터 파이프라인 구축

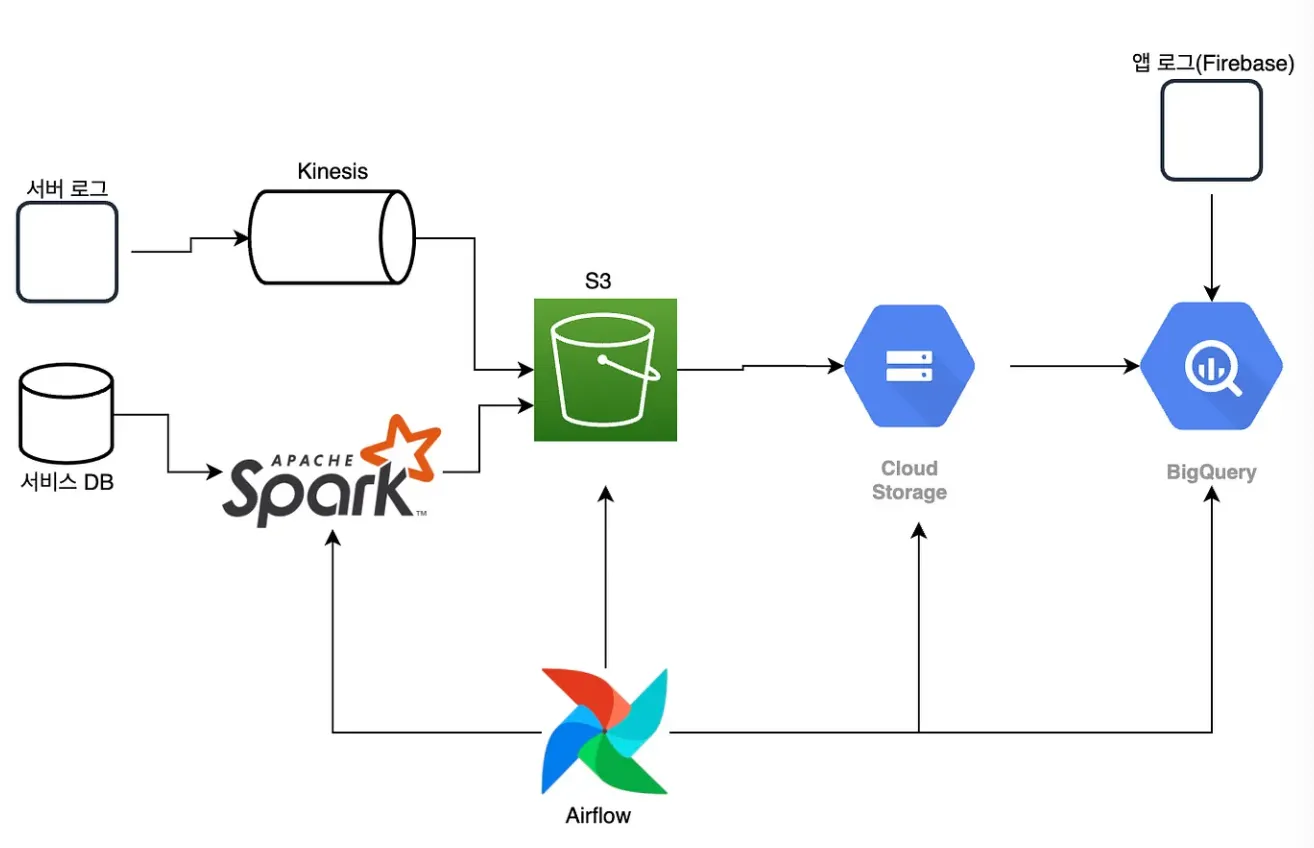
데이터 원천
•
서비스 DB 및 서버 로그
목적
•
마트 파이프라인 (마트 테이블 생성)
◦
마트 테이블(=데이터 마트) : 자주 접근하거나 중요한 데이터들을 잘 연결하여 만들어둔 테이블
1.
필요한 데이터들이 어느 테이블들에 있는지 찾아보지 않아도 되고,
2.
원하는 데이터를 얻기 위해 복잡한 조인 연산을 하지 않아도 됨.
데이터 파이프라인 구분
•
서비스 DB
◦
이미 정제가 되어있는 데이터 소스로부터 데이터를 불어들이는 작업
◦
작업 목표를 위해 데이터를 변환하는 작업이 필요함 → ETL 파이프라인으로 구성.
◦
AWS ECS 서비스 위에서 Spark를 띄워서 사용.
◦
코드 추상화 작업을 통해 재사용 가능한 코드를 구현해놓음.
•
서버 로그 및 클라이언트 로그
◦
BigQuery를 활용한 ELT 파이프라인으로 구성.
◦
서버로그의 경우 Kinesis를 이용하여 스트림으로 들어오는 데이터를 S3에 로드
◦
클라이언트 로그의 경우 firebase에 우선 적재
◦
이후, BigQuery를 활용하여 필요한 형태로 데이터를 변환하는 과정을 거침.
그 외의 스케쥴링 및 자동화
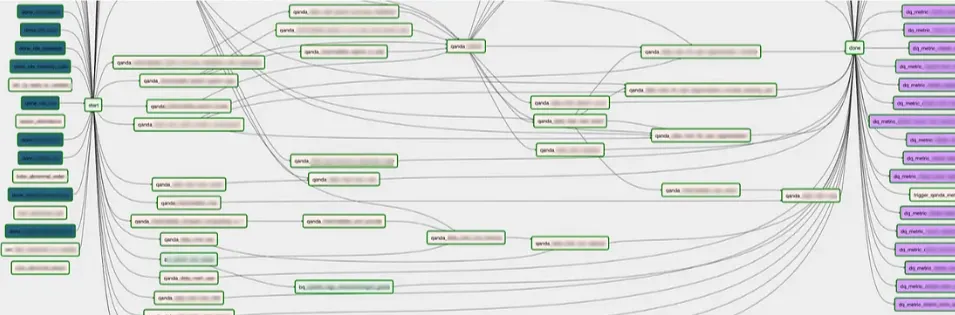
•
Airflow를 이용하여 마트 테이블을 생성하는 DAG를 자동으로 생성하는 작업을 생성
•
분석가분들이 SQL파일을 이용하여 마트 테이블 생성을 요청하면, 자동으로 SQL 파일명과 동일한 이름을 가지는 task를 생성함. 즉, SQL 파일 수 만큼 마트 태스크가 생성됨.
•
요청이 들어왔을 때, DFS 알고리즘을 이용하여 생성하고자 하는 작업이 DAG를 생성하기 위한 비순환 구조 조건을 만족하는지를 점검한 뒤 task를 생성함. 만약, 에러가 난다면 슬랙으로 알람을 보내도록 설정.
그 외의 비슷한 작업물
•
뱅크샐러드의 경우에도 데이터 분석가가 직접 데이터 파이프라인을 설계할 수 있도록 한 작업을 진행한 듯하여 관련 블로글 링크를 첨부합니다!


야놀자 : AWS 위에서 데이터 파이프라인 운영하기
라인(LINE) : 하루 400억 건 발생 데이터 처리를 위한 데이터 파이프라인


Reference
•
데이터 파이프라인 핵심 가이드, 위키북스, 2022
•
빅데이터를 지탱하는 기술, 제이펍, 2021